SR (Super Resolution) - cheeseBG/EmergencyResponseSystem GitHub Wiki
Appendix: https://dydeeplearning.tistory.com/4
This architecture improved performance by removing unnecessary parts from the previously announced convolution residual network (SRResNet).
Limitations of recent research:
- Restoration performance is sensitive to even minor structural changes.
- In SR, the correlation between different scales is not considered and is considered independent.
EDSR Suggestion:
- Delete the parts we don't need. If the network is complex, it is difficult to train, and it is sensitive to loss function settings and model modifications.
- During model training, we train a model on a different scale from a pretrained model to utilize the information for each scale (X2, X3, X4).
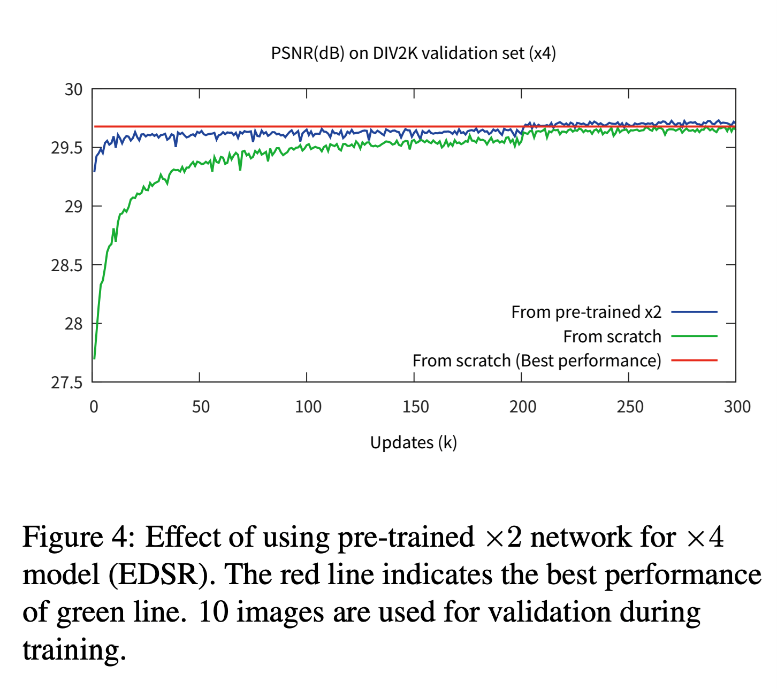
When training for x3 scale and x4 scale in the model, if you initialize and train with the parameters of the network pretrained for x2 scale, the following results will be obtained. You can see that the blue line (pretrained x2) converges faster than the green line (random initialization).
Proposed Methods:

Removed Batch Normalization from SRResnet, which used Residual Block.
Batch normalization hurts fluidity because it normalizes features.
And since it uses the same memory as the convolution layer, memory usage was reduced by 40% during training when Batch Normalization was not used.
This means that by reducing the BN, you can build a larger model.
How to increase model performance?
Increasing a parameter by stacking more layers or increasing the number of filters.
In General CNN Architecture, it is effective to increase the number of channels rather than the number of layers.
But Increasing the number of channels makes training unstable.
To prevent this, the Residual scaling factor is set to 0.1 in the Residual Block of Architecture.
In each residual block, the constant scaling layers are placed after the last convolution layers.
