0819. Most Common Word - chasel2361/leetcode GitHub Wiki
Given a string paragraph and a string array of the banned words banned, return the most frequent word that is not banned. It is guaranteed there is at least one word that is not banned, and that the answer is unique.
The words in paragraph are case-insensitive and the answer should be returned in lowercase.
Example 1:
Input: paragraph = "Bob hit a ball, the hit BALL flew far after it was hit.", banned = ["hit"]
Output: "ball"
Explanation:
"hit" occurs 3 times, but it is a banned word.
"ball" occurs twice (and no other word does), so it is the most frequent non-banned word in the paragraph.
Note that words in the paragraph are not case sensitive, that punctuation is ignored (even if adjacent to words, such as "ball,"), and that "hit" isn't the answer even though it occurs more because it is banned.
Example 2:
Input: paragraph = "a.", banned = []
Output: "a"
這題我用 hash table 來解決,python 的 collections 函式庫中有內建方便的計數器 Counter,把 list 會進去之後就會自動 hash 並計算出現的次數。所以演算的流程不難,可以分成幾個步驟
- 清理文字,把空白跟符號去除
- 計算每個文字出現的次數
- 確認紀錄中是否有敏感詞,若有的話便去除(不計算敏感詞的個數) 寫出來的程式碼如下:
from collections import Counter
import re
class Solution:
def mostCommonWord(self, paragraph: str, banned: List[str]) -> str:
words = [word.lower() for word in re.split(r'[!?\',;. ]', paragraph)]
words = Counter(words)
banned.append('')
for bword in banned:
if bword in words:
words.pop(bword)
return words.most_common(1)[0][0]參考大大的寫法之後發現可以更精簡,如下:
from collections import Counter
import re
class Solution:
def mostCommonWord(self, paragraph: str, banned: List[str]) -> str:
words = re.findall(r'\w+', paragraph.lower())
words = Counter([word for word in words if word not in banned])
return words.most_common(1)[0][0]這樣寫的時間複雜度會是O(n)(整個paragraph跟words各要走一遍),空間複雜度也是O(n)
C++的寫法也很類似,只是沒有方便的 Counter 可以用,程式碼如下
class Solution {
public:
string mostCommonWord(string paragraph, vector<string>& banned) {
unordered_map<string, int> words;
// clean paragraph
for(int i=0; i<paragraph.size();){
string s = "";
while(i < paragraph.size() && isalpha(paragraph[i])){
s.push_back(tolower(paragraph[i++]));
}
while(i < paragraph.size() && !isalpha(paragraph[i])){
i++;
}
// count a word
words[s]++;
}
for(auto x: banned) words[x] = 0;
string res = "";
int count = 0;
// choose max count
for(auto x: words){
if(x.second > count){
res = x.first;
count = x.second;
}
}
return res;
}
};另外還有看到一個特別的寫法,就是用一個資料結構,叫做 Trie (字典樹),它的結構範例如下圖
字典樹其實就是儲存字串的樹,每個連結出去的節點儲存了父節點所存之字串,再新增一個字元而成的字串。在這題裡面只要讓每個節點多儲存出現的次數,就可以解題了。除此了這個字典樹的資料結構外,我們還需要 insert, findMax 以及 ban 三個函式。
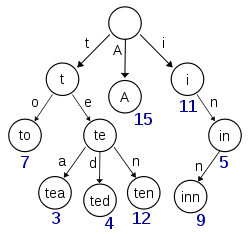
insert 函式負責確認需要處理的字串是否有出現在字典樹中,若有便增加出現次數;若無則將此字串新增至字典樹中。
findMax 函式負責從字典樹的 root 出發,搜尋出現次數最多的字串
ban 函式負責將指定的字串於字典樹中的出現次數強制設為零
有了這三個函數之後,只要依據下方流程便可解題:
- 將輸入的 paragraph 處理成小寫並去除標點
- 利用 insert 將單字加入字典樹
- 利用 ban 將指定單字出現次數設為零
- 利用 findMax 找到出現次數最多的單字
- 輸出結果
寫成程式碼如下:
from collections import Counter
import re
class Solution:
def __init__(self):
self.res = ''
self.maxcnt = 0
class TrieNode():
def __init__(self):
self.word = ''
self.cnt = 0
self.links = [None] * 26
def insert(self, r: TrieNode, s: str):
ptr = r
for i in s:
index = ord(i) - ord('a')
if not ptr.links[index]:
node = self.TrieNode()
node.word = ptr.word + i
ptr.links[index] = node
ptr = ptr.links[index]
ptr.cnt += 1
def ban(self, r: TrieNode, s: str):
ptr = r
for i in s:
index = ord(i) - ord('a')
if not ptr.links[index]: return
ptr = ptr.links[index]
ptr.cnt = 0
def findMax(self, ptr: TrieNode):
if not ptr: return
if ptr.cnt > self.maxcnt:
self.res = ptr.word
self.maxcnt = ptr.cnt
for i in range(len(ptr.links)):
self.findMax(ptr.links[i])
def mostCommonWord(self, paragraph: str, banned: List[str]) -> str:
root = self.TrieNode()
words = re.findall(r'\w+', paragraph.lower())
for word in words:
self.insert(root, word)
for s in set(banned):
self.ban(root, s)
self.findMax(root)
return self.res這樣寫的時間複雜度會是 O(N),N 為 max(len(paragraph), len(banned))
空間複雜度為 O(N),N = len(paragraph)