2023 AI ML - chanandrew96/MyLearning GitHub Wiki
** Use Anaconda to maintenance your Python Library to prevent library conflict **
Anaconda
Machine Learning
Dependency on Microsoft C++ 14.0
Microsoft C++ 14.0 Downlaod
Execute conda install libpython m2w64-toolchain -c msts2
(Conda required)
CSDN Discuss
Turi Create on Windows
- Enable Windows Subsystem via PowerShell command
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux - Install Windows Subsystem for Linux (WSL2)
- Found Ubuntu on Windows Store
Install Python on WSL
- Follow all the instruction & use the version provided
- Use Python 3.6/3.7 in virtual environment
Install Python on Ubuntu
How to Install Python 3.8 on Ubuntu 18.04
Some Keyword U Must Know
模型 (Model)
神經網絡 (Deep Neural Network)

深度學習其中一個元素
包含了:
- 輸入層 (Input Layer)
- 隱藏層/中間層 (Hidden Layer)
- 輸出層 (Output Layer)
參考資料
節點 (Neurons)
- 每一層當中會包含多個節點 (Stacked Components - Neurons),基於識別結果該節點會有不同的對應結果
- 輸入層 (興奮 Firing/靜息)
- 隱藏層/中間層
- 輸出層 (興奮度 - 用於對比不同節點的結果)
- 每個節點都內置了自己的狀態條件 (Positive: Threshold / Negative: Bias)
- 當結果減去Threshold或加上Bias後達到條件便會Fire該節點
- Bias在每層中都應保持一致
- 每個節點可以理解為一個"考慮因素"
輸入層 (Input Layer)
- 主要用於獲取輸入信息
- 輸入層只有一層但可有多個輸入點
- 基於不同的輸入,各節點會得到興奮/靜息的狀態
隱藏層/中間層 (Hidden Layer)
- 主要進行特征提取
- 會有多層處理,處理輸入層輸入的資料後應比輸入層的點少
- 每個節點對於輸入層的興奮有不同的接收權重 (Weight)
- 節點中會對不同的神經單元配給不同的權重,影響識別偏向
輸出層 (Output Layer)
- 主要對接隱藏層並輸出模型結果
- 經隱藏層處理後最後所輸出的結果,應有最少的點
- 根據隱藏層的興奮和權重回傳不同的興奮度
- 節點會對各個隱藏層節點配給不同的權重,影響輸出結果偏向
權重 (Weights)
- 等於敏感度
- 隱藏層不同的節點都有各自的權重
- 以權重判斷哪一個輸入較為重要 (當該輸入節點Fire時,最後的計算結果會因權重的大小改變)
- 調整權重以避免因不同的Noise影響識別結果
- 監督學習下,權重可以理解為損失函數/代價函數 (Cost Function),計算學習後預測值加上學習資料中偏差值(誤差)的平方
- 監督學習中就是透過學習資料減少模型預測的誤差
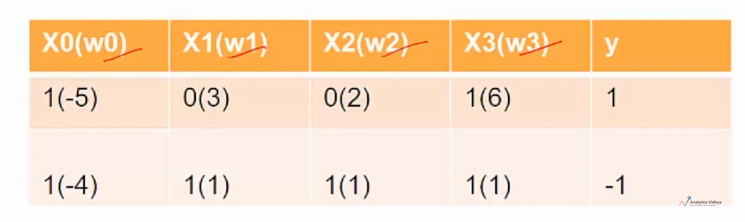
在上圖中,X0為Bias值,X1至X3為不同的輸入,W為不同的權重。當該輸入為正(1)時,該權重就會加至計算結果,當所有輸入加上(X1至X3)大於Bias(X0)時,該節點就會Fire/得到為正數的值
損失函數/代價函數 (Cost Function)
- 用於衡量模型是否合理
Activation Functions
用於改變計算結果

理論上計算節點的結果可以由"負無限"到"無限",但舉例我們用節點計算年齡時得出一個負數是不合理的(雖然我們仍可以這個數來介定該人是否年輕)
這個時候我們可以用ReLU function來把負數的可能刪去
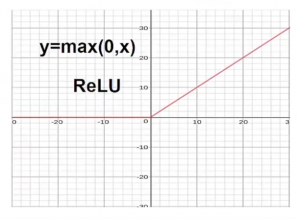
ReLU Function
- Activation Function的其中一種
- 用於去除負結果
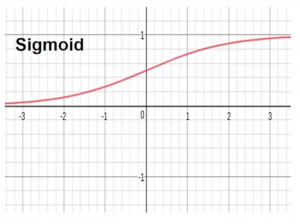
Sigmoid Function
- Activation Function的其中一種
- 用於限制結果介乎於0 - 1
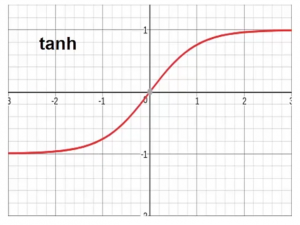
Tanh Function
- Activation Function的其中一種
- 用於限制結果介乎於-1 - 1
時序特征 (Time Series)
- 上下文信息
- 單詞多義時,一般的神經網絡只會參考訓練時較多出現的結果,但現實情況是需要看上下文信息分辨
時間線
- 可以理解為文字在文本中出現的時間
RCNN (Region-based Convolutional Neural Network)
參考資料
Tensor 張量
Tensor是使用統一類型的多維度矩陣(Multi-dimensional arrays with a uniform type),作為ML的基本單位
Tensor類近於NumPy的矩陣(Array),而NumPy只能於CPU上運行
Tensor無法進行更新(Update),只可以新建一個新的Tensor
在Program層面上Tensor相近於Object的存在
Scalar / Rank-0 Tensor
Scalar只儲存了單一值(Single Value),沒有軸線(Axes)
# Tensorflow
rank_0_tensor = tf.constant(4)

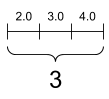
Vector / Rank-1 Tensor
Vector儲存一個列表的值(List of Value),有一條軸線(One Axis)
# Tensorflow
rank_1_tensor = tf.constant([2.0, 3.0, 4.0])
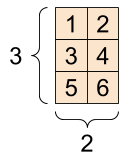
Matrix / Rank-2 Tensor
Matrix儲存帶有列表或值的列表,有兩條軸線(Two Axes)
# Tensorflow
rank_2_tensor = tf.constant([1, 2], [3,4], [5, 6](/chanandrew96/MyLearning/wiki/1,-2],-[3,4],-[5,-6), dtype=tf.float16)
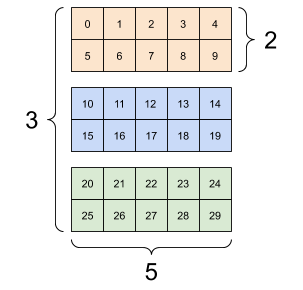
帶有多條軸線的Tensor
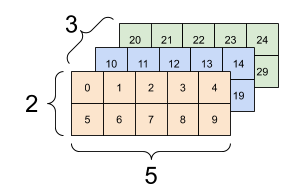
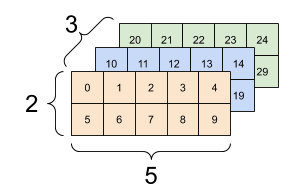
Tensor不限於兩條軸線,下面是一個3-axes Tensor的例子
rank_3_tensor = tf.constant([
[[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]],
[[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]],])
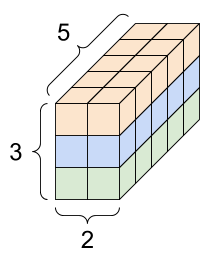
當Tensor帶有多於兩條軸線時,我們可以用不同的方式進行可視化
Tensor的運算(Basic Math)及比較(Ops)
我們可以基於Tensor作基本的運算和比較
Tensor 軸線排列次序 (Indexing)
TensorFlow使用與Python相同的Indexing方法
Tensor的軸線排列大多由全局排到本地(Tensor Axis ordering from global to local)就如下圖所示
根據不同的框架也有對應的功能可以調換軸線的排列次序
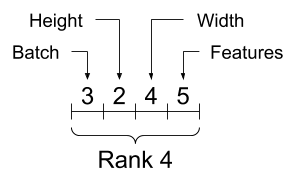
重塑Tensor形狀(Manipulating/Reshaping Tensor)
重塑Tensor時,新的Shape的元素總數量必須與舊有的相同
原則上新的Shape應該與舊有的大致相近如下圖
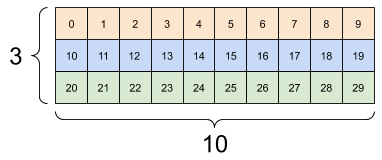
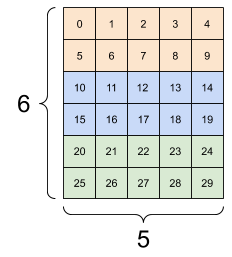
上面的結果可見重塑後每層的數據與舊有相同,重塑的只有單層的數據排列方法
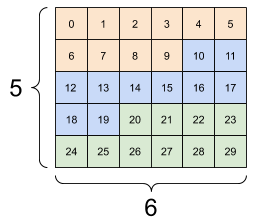
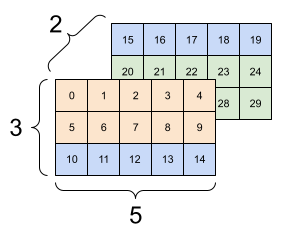

而上面的結果是一個不良的重塑結果,可見重塑後每層的數據來自不同的層級
為什麼和什麼時候我們需要重塑Tensor?
以下答案由ChatGPT提供
| Point | Descripiton |
|---|---|
| Compatibility | Sometimes, two tensors need to have the same shape or dimensions to perform certain operations. For example, when concatenating two tensors along a particular dimension, they need to have the same size along that dimension. 當我們需要對多個Tensor進行運算處理時通常需要它們有相同的Shape,所以我們需要重塑以繼續運算。 |
| Model requirements | Different machine learning models may require input tensors of different shapes or dimensions, depending on their architecture. Reshaping the input tensor to fit the model's requirements can improve its performance. 基於不同的模型所需求的Tensor Shape也有所不同,所以我們需要重塑以符合所需的Shape。 |
| Memory optimization | Reshaping can also be used to optimize memory usage. For example, if we have a tensor with a large number of elements but only need to perform operations on a small subset of them, we can reshape the tensor to only include the relevant elements. |
| Visualization | Reshaping can be useful for visualizing the data. For example, a 3D tensor can be reshaped into a 2D tensor for easier visualization on a 2D screen. |
Tensor和NumPy Array間的轉換
要將Tensor轉換為NumPy Array,我們可以使用np.array或tensor.numpy功能
np.array([YOUR_TENSOR])
[YOUR_TENSOR].numpy()
Tensor的型態(Shapes)
基本的Tensor要求每條軸線上的元素(Element)量相同以形成一個長方體
一些有關於Tensor的Shapes的概念
| Vocab | Description | TF Code For the Value |
|---|---|---|
| Shape | 每條軸線上的元素數量(The length/number of elements of each axes) | [YOUR_TENSOR].shape |
| Rank | Tensor裡面軸線(Axes)的數量 | [YOUR_TENSOR].ndim |
| Axis/Dimension | Tensor裡的軸線/維度 | [YOUR_TENSOR].ndim |
| Size | Tensor裡元素的總數 | tf.size([YOUR_TENSOR]).numpy() |
Uniform Type 統一類型 / DType
Tensor中可支援的類型在不同的框架下有少量分別,但大多都支援以下類別:
- floats / floating point
- strings
- complex 要查看不同框架下支援的類型可參考另一篇或各框架的官方文件
Tensor Reference
Introduction to Tensors
Pytorch 基本介紹與教學
神經網絡結構(Neural Network Architectures)
RNN
- 神經網絡的一種算法
- 隱藏層為循環結構
- 由於循環結構和時序特征,隱藏層的值在計算時會包含了上一個時刻(在隱藏層)的值
- RCNN保證了在後面的時刻必定會保留了前面時刻的信息
- 由於所有時刻都使用了同一個權重,減低了所使用的參數量
- 關於RNN所帶來的問題可參考【重温系列】RNN循环神经网络及其梯度消失 手把手公式推导+大白话讲解
LSTM (Long short-term memory)
- RNN的升級版,基本大多RNN都是使用LSTM
- 雙向(Bidirectional)LSTM可以得到前面和後面的信息,所以可以用下文推理,解決單向(Unidirectional)無法以下文推理的問題
- 梯度消失問題 (Vanishing Gradient Problem) 【重温经典】大白话讲解LSTM长短期记忆网络 如何缓解梯度消失,手把手公式推导
梯度消失問題 (Vanishing Gradient Problem)
參考資料
Transformer
- 神經網絡結構(Neural Network Architectures)的一種
- 表現比RNN好
- 三大重點
- Encoder-decoder 的架構
- 注意力機制 (Attention)
- Transfer learning
GPT (Generative Pretrained Transformer)
- 自然語言處理架構的一種
- 由OpenAI開發的深度學習模型
ChatGPT
- 基於GPT開發的ChatBot
- 使用了預訓練的GPT模型 Reference: ChatGPT自我分析
BERT (Bidirectional Encoder Representations from Transformers)
- 自然語言處理架構的一種
注意力機制 (Attention)
單向關係 (Unidirectional Relationship)
- 在說明兩個名詞間的互動時只能用單方面的動詞,如:
- Email Service "installed on" the server
- 如果需要達到"互動"的效果就需要加上多條情況,如:
- Email Service "installed on" the server
- Server "installed with" the email service
雙向關係 (Bidirectional Relationship)
- 在說明兩個名詞間的互動時不需要用多條情況說明該互動
單向/雙向關係參考資料
自然語言處理應用 (NLP - Natural Language Processing)
深度學習
框架:
- PyTorch
- TensorFlow
- JAX
HuggingFace
- 用於自然語言處理應用的主流工具
- 支援模型在不同的深度學習框架間轉換,主要支援:
- PyTorch
- TensorFlow
- JAX
Hugging Face Hub
- 用於存放已訓練好的AI模型
Hugging Face Library
- Hugging Face所提供的庫
- 三個常用的Library:
- Transformer
- Tokenizers
- Datasets