relu - cccbook/py2gpt GitHub Wiki
從 Sigmoid 到 ReLU
如果神經網路中只有線性層 (Linear) ,那麼整個網路就只能做線性分割問題,於是連 XOR 這個簡單的功能都會學不起來
因此神經網路得加上《非線性層》,才能變得更強 ...
傳統神經網路的非線性層,通常用 Sigmoid 函數,其圖形與公式如下
$$ \sigma (x)={\frac {1}{1+e^{-x}}} $$
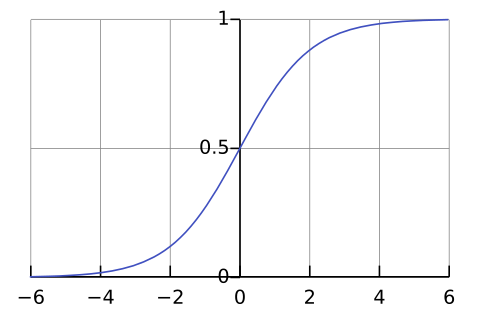
但是像 Sigmoid / Tanh 這類的函數,由於左右的斜率都很小,只有中間區域斜率稍大,這會造成神經網路經常落入《梯度消失》的窘境
這個問題讓神經網路通常只能有 3 層,超過 3 層就經常會因梯度消失而導致網路學習失敗。
後來在新一代的神經網路,也就是《深度學習》技術當中,通常會用 ReLU 這類非線性函數取代 Sigmoid, ReLU 的公式和圖形如下
$$ {\displaystyle f(x)={\begin{cases}x&{\mbox{if }}x>0\\ 0&{\mbox{if }}x\leq 0\end{cases}}} $$

結果發現,梯度消失的現象很少發生了
這個小小的改動,讓神經網路的可以連接很多層卻還能正確學習,於是導致了《深度學習》這個名詞的出現 ...
延伸
後來,為了避免 x<0 的時候梯度消失,又出現了 Leaky ReLU / ELU / GELU 等 ReLU 的變形函數
請參考