Detecting 3D objects in point clouds - camdenkr/EC601 GitHub Wiki
Detecting 3D objects in point clouds
What is a point cloud?
While a majority of computer vision tasks rely on 2D data, 3D data is a crucial element for many computer vision applications such as self-driving vehicles, autonomous robots, and virtual reality to name a few. The simplest form of representing this 3D data is with point clouds. Point clouds are a collection of points in a 3D space with no connectivity. Data may be paired with these points along with X,Y,Z coordinates such as RGB or luminance. A point cloud may be constructed using various methods such as LiDAR, LIDAR+RGB cameras, RGB-D cameras, or stereo cameras. [1][2] LiDAR has become an increasingly popular technology for 3D scanning. LiDAR data in its raw form is captured as a point cloud, while other methods will preprocess their data into point clouds. 3D object detection aims to be able to take this raw data form, either by processing it or reading it raw, and classify and segment the objects they represent.
There are various approaches to representing point cloud data including: voxel-based, point-based, frustrum-based, pillar-based, and 2D projection based. The various approaches may be grouped into two categories, point-based and all others which may all be categorized as "grid-based." [7]
Point based approaches directly use point clouds to process the data, such as PointNet discussed below. Voxel-based approaches transform the 3D point clouds into a 3D voxel grid, such as with VoxelNet described below. The use of voxel grids allows for the use of CNN-based approaches to 3D object detection from point clouds by providing them with structured representations. Voxel grids are "quantized, fixed-size point clouds" where each voxel (or cell) has specified coordinates and size within a 3D grid.[3] Each voxel cell can contain a scalar value or vector data. 3D convolution may then be used on the resulting voxel grid. However, voxel grids have the issue of being very sparse. Point clouds are already sparse to begin with and generated voxels may combine many points within a single voxel reducing the amount of data to give to a particular model. Voxel grids must also actively represent empty space whereas point clouds do not, increasing the amount of information needed to represent a single voxel grid, and the resulting computational complexity for an object detector.[4]
Frustrum-based approaches divide point clouds into frustrums, cones or pyramids remaining after being cut by a plane parallel to its base. Models crop point cloud regions into Frustrum-clouds, such as Frustrum PointNet. Pillar-based approaches organize the point clouds into vertical columns (pillars). This allows the process of grouping the points to be tuned along the x-y plane such as with PointPillars. Lastly, 2D Projection-based approaches reduce the dimensionality and therefore computing cost of 3D data by projecting 3D points onto a 2D using techniques such as front view, range view, and bird's eye view. Examples of models that use the bird's eye view scheme are ConFuse, and LaserNet++.[7]
3D Object Detection Model Examples
VoxelNet (2015) was one of the leading approaches to 3D object detection using voxel grids. It functions by computing probabilistic occupancy grids, where each voxel has a certain probability that it is occupied in space, i.e. that there is some object there.
VoxelNet's architecture consists of 3 functional blocks: a feature learning network, convolutional layers, and a region proposal network. The first functional block, the feature learning network, subdivides a point clouds into a 3D space, grouping points into voxels, randomly sampling points from voxels with more than a specified number of points to reduce computational complexity. They then use a chain of VFE layers, encoding point interactions within a voxel and enabling the final feature representation to learn shape information. The next block of convolution layers serves to apply 3D convolution to aggregate voxel-wise features. Lastly, the region proposal network takes the output from the previous block and maps a probability score and a regression map.[5]
One downfall to this system was that it assumed an upright position along the z-axis of the sensor, and therefore rotations would impact predictions on the object. To combat this, data augmentation was used by training the model on rotated voxel grids.[3]
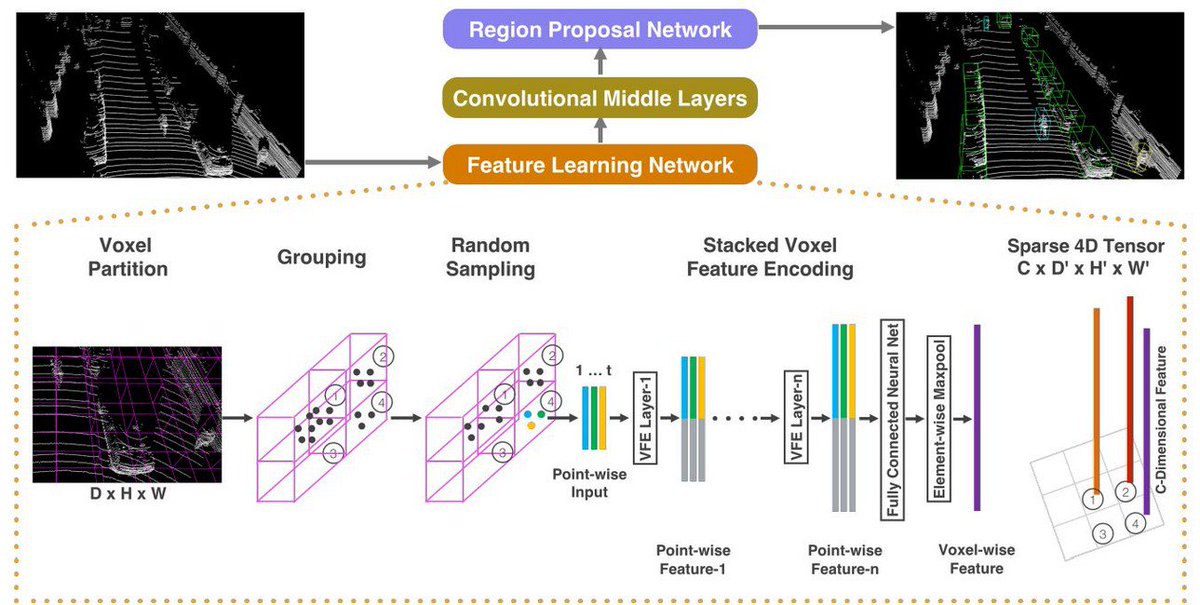
Figure 1: VoxelNet Architecture [5]
PointNet (2016) was developed as a method to use point cloud data directly. The goal of PointNet was to develop an architecture that could develop reasoning about irregular, non-uniform data without transforming it into something like a voxel grid which loses natural data. PointNet's system is such that its predictions are not impacted by scaling or rotating the points. It does this by using a symmetric function (one where the order of the inputs does not affect the outputs), max pooling.
PointNet's architecture consists of a classification network and a segmentation network. The classification network simply takes in a number of points as inputs, applies various input and feature transformations, and then aggregates the features by max pooling. The network will then output classification scores for each class. The segmentation network acts as an extension to the previous network, concatenating global and local features and output scores and predict per point labels.[6]
PointNet is currently available as an open source project available on Github at: https://github.com/charlesq34/pointnet. It uses the MIT open source license copyright in 2017. This allows the code to be freely used for almost any use as long as the original copyright license is present. While this Github hasn't been updated since 2019, there are many other projects that have been developed from the work done on PointNet. While the project only has 3 contributors, it has been starred 3,400 times and forked 1,200 times. The GitHub also contains detailed citation, installation, and usage instructions as well as a link to project website. [13]
Since PointNet was developed, PointNet++(2017) was developed to address the issue of PointNet's inability to capture local structures within a specific group of points. It does this by sampling points for local regions, grouping neighboring points based on distance, and encoding features within these regions using a "mini-PointNet."[3]
Figure 2: PointNet Architecture [6]
Since 2015, There have been various other models with the goal of providing high accuracy, real-time 3D object detection. Many use the KITTI object detection benchmark. The KITTI 3D object detection benchmark consists of 7481 training images and 7518 test images as well as their corresponding points clouds, and provides average precision of a given model, benchmarking it against other models. Other benchmarks include nuScenes, Waymo, and A2D2 benchmarks. Precision of different object detectors is generally modeled using mean average precision (mAP).
Various methods have been used to increase the performance of models on these benchmarks, ne of them being semantic point generation (SPG) (2021) which can produce state-of-the-art results with existing models such as with PV-RCNN. SPG addresses the issue of generalizing a 3D detector to different domains, where the environment varies and point cloud quality can deteriorate. An example of this addressed in the SPG paper is with PointPillars, where its precision drops 21.8 points when used on a dataset containing raining weather, causing missing LiDAR points. SPG attempts to address these missing points by generating semantic points to recover foreground regions while only adding "marginal complexity" to any given 3D detector. Generally, SPF will take a given raw point cloud, generate semantic points in predicted foreground regions using various methods, and then generate a new, combined point cloud to feed to a detector.[8]
Lastly, I will briefly describe a more state-of-the-art technique PV-RCNN (2019), or PointVoxel-RCNN mentioned earlier. The goal of this more recent model is to combine the advantages from both point-based (e.g. PointNet) approaches which have high computational complexity but more data and voxel-based (e.g. VoxelNet) approaches which have lower computation complexity but lose information. The key to PV-RCNN is how to combine the two approaches. PV-RCNN proposes to use a two-stage approach: a voxel-to-keypoint scene encoding which summarizes voxels into a small number of feature key points, and a point-to-grid Region of Interest (RoI) feature abstraction which aggregates a scene's key point features. By combining the advantages of previous models, as well as with other methods of improving data and detector accuracies, the accuracy and speed of object detectors is quickly evolving. [9]
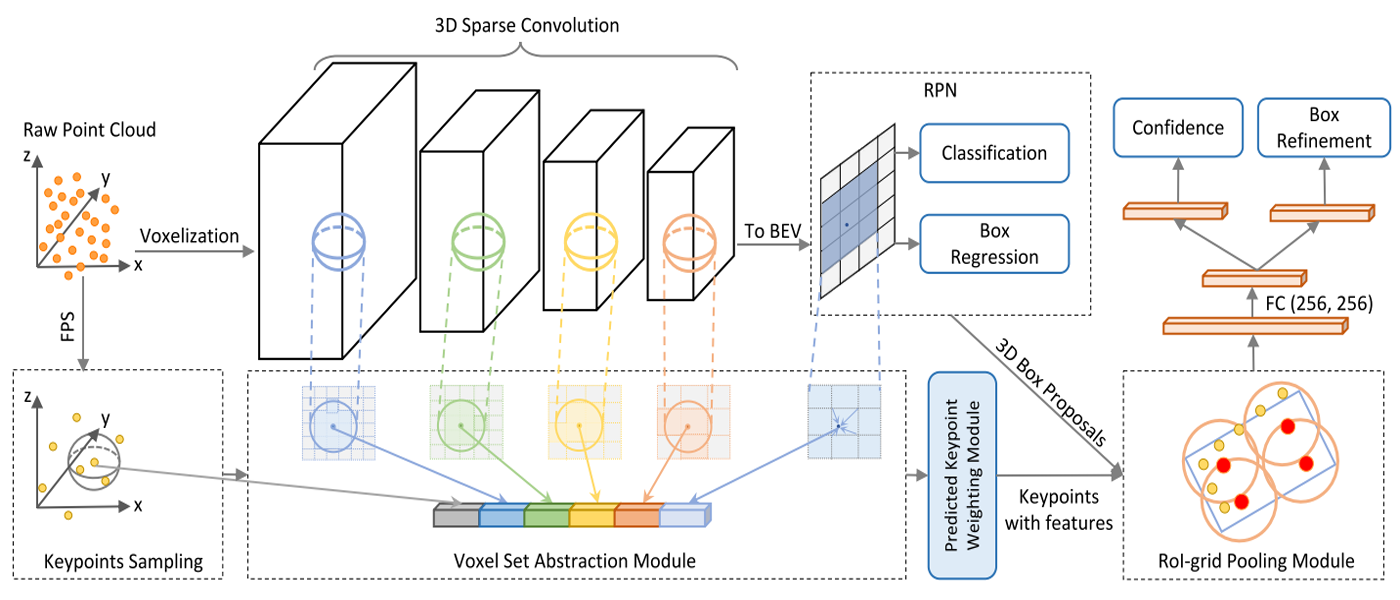 Figure 3: PV-RCNN Architecture [9]
Figure 3: PV-RCNN Architecture [9]
Why is it important?
The applications for 3D object detection in point clouds is endless. One of the biggest applications right now for detecting 3D objects in 3D space is autonomous driving. According the World Health Organization, on average, around 1.3 million people die each year on the road, and around 20-50 million suffer non-fatal injuries. Self-driving cars could greatly reduce the number of injuries and fatalities due to road accidents, but in order to do so, autonomous mapping of the area must be robust enough. [7] In addition, autonomous robots of all kinds have limitless applications from health care, aiding those with disabilities, performing tasks in warehouses, farming, and more. But, along with many technologies that had to be developed, an extremely important aspect that these robots need to have in common is an accurate perception of their environment. Warehouse robots need to know exactly here a box lies in space. Autonomous medical robots need to be extremely precise if they were to be used for autonomously performing medical procedures or surgeries. Autonomous driving must make decisions within milliseconds for where and how to drive when unforeseen circumstances. By being able to detect, classify, and segment objects using 3D data quickly and precisely, many tasks become more efficient and safer for the world.
Looking at Autonomous Vehicles
There are various approaches to detecting 3D objects for use in self-driving cars. Almost every company working on self-driving cars use LiDAR including: Uber, Waymo, and Toyota. Waymo uses an array of sensors including cameras, radar, and LiDAR to aid in gathering data about the space around the car. One issue with the introduction of LiDAR is its cost. While it is becoming more affordable, a single LiDAR device on a car reportedly would cost $10,000.[11] As such, Alphabet mass produces its own LiDAR technology, which it stopped selling to other companies this year. In defiance to all other companies using expensive LiDAR technology, the one company that has vowed not to use LiDAR is Tesla, arguably the most popular self-driving car company today. The Model 3 and Model Y have transitioned to camera-based vision alone, without even radar, dubbed Tesla Vision.[10] Each company researching autonomous vehicles uses a different set of neural networks and methods for gathering and representing data, and further research still needs to be done to create the optimal system of detecting 3D objects in space. A single multi billionaire dollar industry is reliant on figuring out the most precise and efficient ways of generating data from 3D space and detecting objects within it. Contrary to most of Tesla, in China, Baidu has developed self-driving platforms with Apollo, which is a very large open source project currently on its 6th version with over 18,000 contributions. The project is protected by an Apache License 2.0, which is very flexible with allowing others to use and redistribute the source code. Baidu also integrates LiDAR along with other cameras and sensors in its self-driving cars.[17]
Handful of Open Source Projects Links
A Tensorflow implementation of VoxelNet: https://github.com/tsinghua-rll/VoxelNet-tensorflow PointNet: https://github.com/charlesq34/pointnet PV-RCNN: https://github.com/open-mmlab/OpenPCDet VoteNet: https://github.com/facebookresearch/votenet Tensforflow implementation of PointPillar: https://github.com/tyagi-iiitv/PointPillars
There are many architectures easily available as open source projects. Some of them are from the orginial researchers such as with PointNet, and others are unofficial recreations of other projects, or even based off other open source projects.
Along with specific architectures that have been created and shared for use publicly, there have also been developments in aiding working with 3D data for deep learning applications, such as with PyTorch3D. PyTorch3D is an open source library developed by Facebook to aid in working with 3D data. It contains various data structures, operators, loss functions, and transforms for 3D data based on PyTorch tensors. PyTorch3D was an essential framework for developing Facebook’s Mesh R-CNN as well as C3DPO, which extracts 3D models from 2D annotations.[14][15] The PyTorch3D Github is currently active, with the latest commit being 2 days ago at the time of writing this. It also has 55 contributors and is starred 5,200 times. Pytorch3D’s open source license is the BSD License. As the project had its first release of v0.1.0 Jan. 23rd 2020, it is still relatively new and has been actively developed since. The BSD license allows for redistribution and use of the code or binary with or without modification as long as the redistribution of the code contains a copy of the license, and that the user of the code may not use Facebook or other contributors to promote derived products without their explicit consent. In other words, the license offers a lot of freedom for developers to use the framework so long as they include the original license.[16]
Citations
[1]https://towardsdatascience.com/deep-learning-on-point-clouds-implementing-pointnet-in-google-colab-1fd65cd3a263
[2]https://cleantechnica.com/2021/07/14/video-quick-look-at-point-clouds-from-tesla-neural-network-data/
[3]https://thegradient.pub/beyond-the-pixel-plane-sensing-and-learning-in-3d/
[4]https://openaccess.thecvf.com/content_cvpr_2018/papers/Yang_PIXOR_Real-Time_3D_CVPR_2018_paper.pdf
[5]https://arxiv.org/pdf/1711.06396.pdf
[6]https://arxiv.org/pdf/1612.00593.pdf
[7] Fernandes, Duarte & Monteiro, João & Silva, António & Névoa, Rafael & Simões, Cláudia & Gonzalez, Dibet & Guevara, Miguel & Novais, Paulo & Melo-Pinto, Pedro. (2020). Point-Cloud based 3D Object Detection and Classification Methods for Self-Driving Applications: A Survey and Taxonomy. Information Fusion
[8]https://arxiv.org/pdf/2108.06709v1.pdf
[9]https://arxiv.org/pdf/1912.13192.pdf
[10]https://www.tesla.com/support/autopilot
[11]https://towardsdatascience.com/why-tesla-wont-use-lidar-57c325ae2ed5
[12]https://www.youtube.com/watch?v=HM23sjhtk4Q
[13]https://github.com/charlesq34/pointnet
[14]https://analyticsindiamag.com/hands-on-guide-to-pytorch3d-a-library-for-deep-learning-with-3d-data/
[15]https://ai.facebook.com/blog/-introducing-pytorch3d-an-open-source-library-for-3d-deep-learning/
[16]https://github.com/facebookresearch/pytorch3d
[17]https://apollo.auto