Lecture 4 - bancron/stanford-cs224n GitHub Wiki
Lecture video: link
This lecture covers dependency parsing.
Syntactic structure - consistency and dependency
The basic unit of sentence structure is words: "the", "cat", "cuddly", "by", "door". These have a part of speech: "cat" is a noun, "by" is a preposition, "cuddly" is an adjective. "The" is a determiner: other words in this category include "an", "this", "that", "every". They have a "determinative" function of picking out which cat they are referring to.
We combine words into phrases: "the cuddly cat" is a noun phrase, "the door" is as well, and "by the door" is a prepositional phrase.
Phrases can combine into bigger phrases: "the cuddly cat by the door" is a larger noun phrase.
Linguists often represent sentences as context-free grammars.
Dependency grammar and treebanks
Constituency grammars
Phrase structure organizes words into nested constituents.
Lexicon:
N -> dog | cat | crate
Det -> a | the
P -> in | on | by | behind
V -> talk | walked
Adj -> cuddly | large | barking
Grammar:
NP -> Det (Adj)* N (PP)
PP -> P NP
VP -> V PP
- Tokens in parens are optional (0 or 1).
*is the Kleene star which means repeat the token any number of times, including 0.
Possible realizations of this grammar:
the cat
a dog
a large dog
a barking dog in a crate
a cuddly cat by the door
the large crate on the large table
talk to the cat
walked behind the crate
Dependency grammars
Around 2000, NLP people have moved to using dependency grammars. The idea is to take a sentence, and for each word, say what other words modify it.
Look in the large crate in the kitchen by the door.

Draw an arrow from the head to the dependent: the thing that modifies or specifies the head.
You might think that the preposition is the head of the prepositional phrase: "in the crate" headed by "in". But we're going to use dependency grammars which follow the framework of universal dependencies, a framework (created by the lecturer Manning) which gives a common dependency grammar over many human languages. Some languages use prepositions, others use case markings (genitive, dative, etc). So "in the crate" is treated like a case-marked noun.
Why do we care about syntactic structure? Human languages can communicate very complex ideas by composing words together into bigger units. The listener doesn't receive the syntactic structure directly - they just get a sequence of words. They need to be able to reconstruct the structure and hence the meaning of the sentence. In the same way, we need our clever neural net models to understand the structure of the sentence so that they can interpret the language correctly.
The structure (syntax) can change the meaning. Which sentences can be ambiguous depends on the details of the language, e.g. case markings, word orderings.
Syntactic ambiguity
Here are some syntactically ambiguous sentences in English:
- San Jose cops kill man with knife
- "The cops used the knife to kill" interpretation:
- kill -> cops
- kill -> man
- kill -> knife
- "the man had a knife" interpretation:
- kill -> cops
- kill -> man
- man -> knife
- "The cops used the knife to kill" interpretation:
When there is a prepositional phrase late in the sentence, it can be interpreted as modifying a noun phrase that comes before it, or a verb that comes before it. There are such attachment ambiguities in prepositional phrases throughout our sentences. But usually we have no trouble resolving them because our brains are very good at considering the possible interpretations and picking the one that makes sense in context. There are different ambiguities in languages besides English, e.g. in Chinese prepositional phrases are placed immediately before a verb that they modify, but they do have other ambiguities.
- Scientists count whales from space
- "there are whales in space" interpretation
- whales -> space
- "the counting happens in space" interpretation
- count -> space
- "there are whales in space" interpretation
This sentence has 5 prepositional phrases. We can attach the phrase to anything to its left, as long as there are no crossing edges (arrows).
- The board approved [its acquisition] [by Royal Trustco Ltd.] [of Toronto] [for $27 a share] [at its monthly meeting].
- approved -> acquisition
- Royal Trustco -> Toronto
- share -> acquisition
- meeting -> approved

Human language sentences are extremely ambiguous. If we have k prepositional phrases, the number of possible parses are given by Catalan numbers, an exponentially growing series which arises in many tree-like contexts. This is bad news if we want to calculate parses by enumerating them all.
Compare this to the grammars used in e.g. compilers: they are made to be unambiguous, or at worst resolve ambiguities by always choosing one parse tree over another. The question "what does this else clause modify?" is unambiguous to answer.
Coordination scope ambiguity
-
Shuttle veteran and longtime NASA executive Fred Gregory appointed to board.
- [Shuttle veteran] and [longtime NASA executive Fred Gregory] appointed to board.
- 2 people
- [Shuttle veteran and longtime NASA executive Fred Gregory] appointed to board.
- 1 person
- [Shuttle veteran] and [longtime NASA executive Fred Gregory] appointed to board.
-
Doctor: no heart, cognitive issues
- [No heart], [cognitive issues]
- No [heart, cognitive] issues
Adjectival/adverbial modifier ambiguity
-
Students get first hand job experience
- SFW interpretation
- hand -> first
- experience -> job
- experience -> hand
- Less SFW interpretation
- job -> hand
- experience -> job
- experience -> first
- SFW interpretation
-
Mutilated body washed up on Rio beach [to be used for Olympics beach volleyball]
- beach -> [big verb phrase] (normal interpretation)
- body -> [big verb phrase] (gruesome interpretation)
Practical uses
Knowing the syntactic structure of a sentence helps us with semantic interpretation and semantic extraction.
Here's an example from protein-protein interactions.

Dependency syntax postulates that syntactic structure consists of relations between lexical items (words), normally binary asymmetric relations ("arrows") called dependencies. Dependency grammars usually give the arrows a type with the name of the grammatical relation (e.g. subject, prepositional object, apposition, etc.) An arrow connects a head (governor, superior, regent) with a dependent (modifier, inferior, subordinate). Usually dependencies form a tree (a connected, acyclic, single-root graph).

One note: sometimes people draw the arrows the other way around. Tesnière (first person to do modern dependency work) had them point from head to dependent, so that is this course's convention. We also usually add a fake ROOT node so that every word is the dependent of exactly one other node.
Training modern NLP dependency parsers is dependent on annotated data, hand-annotated by human linguists, known as a treebank. This took off in the 1980s and '90s. One such is Universal Dependencies (the lecturer Manning's project).
Building a treebank seems a lot slower and less useful than writing a grammar by hand. But a treebank gives us many things. They are highly reusable. Many parsers, part-of-speech taggers, etc. can use it, as well as psycholinguistics projects, as opposed to a grammar written for one particular parser and never used again. They are a valuable resource for linguistics.
Treebanks also get broad coverage of language rather than covering a few intuitions. They naturally result in statistics and distributional information. And finally, they can be used as a way to quantitatively evaluate NLP systems.
Transition-based dependency parsing
Sources of information for dependency parsing:
- Bilexical affinities: e.g. the dependency [discussion -> issues] is plausible
- Dependency distance: most dependencies are between nearby words
- Intervening material: dependencies are ordered around verbs, and rarely span intervening verbs or punctuation
- Valency of heads: for a given head, how many dependencies on which side are usual. For example, in English a noun ("cat") often has a determiner ("the") to the left, but is unlikely to have one to the right.
A sentence is parsed by choosing for each word what other word (including ROOT) it is a dependent of. There are usually some constraints, such as having only one word as a dependent of ROOT, and the tree assumption (no cycles A -> B, B -> A).
And finally, the issue of whether arrows can cross (be non-projective) or not. A parse is projective if there are no crossing dependency arcs when the words are laid out in their linear order, with all arcs above the words. Here is a non-projective parse which is the correct parse for this sentence:

Typically dependencies are projective, so the sentences have a nesting structure (as you often see in context-free grammars), but most languages have some instances of non-projective dependencies. In English, you can shift modifying phrases and clauses toward the end of the sentence.
Dependencies corresponding to a context-free grammar tree necessarily must be projective, but dependency theory normally allow non-projective parses. One example is "preposition stranding", which creates (arguably ungrammatical) sentences which we nonetheless see. (The grammatical version would be "From who did Bill buy the coffee yesterday?".)

Methods of dependency parsing
- Dynamic programming: Eisner (1996) found a dynamic programming solution with complexity O(n^3) algorithm.
- Graph algorithms: create a minimum spanning tree for a sentence.
- Constraint satisfaction: edges are removed that don't satisfy hard constraints.
- Transition-based parsing, also known as "deterministic dependency parsing": use a transition system (think shift-reduce parsing as used in compilers) guided by good machine learning classifiers.
Greedy transition-based parsing
We parse sentences with a greedy transition-based parsers. We will parse sentences with a set of transitions (kind of like shift-reduce parsers) which works left to right, bottom-up.
The parser has:
- a stack σ, written with top to the right and starting with the ROOT symbol
- a buffer β, written with top to the left and starting with the input sentence
- a set of dependency arcs A and starting empty
- a set of actions
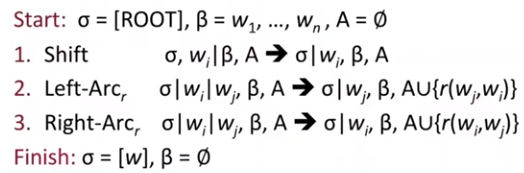
We start with a stack that just has the root symbol, a buffer with the entire sentence, and no arcs. At each point in time we can Shift, which moves the next word onto the stack, we can Left-Arc Reduce, or Right-Arc Reduce. Reduce takes the top two items on the stack, and makes one a dependent of the other. Left-Arc makes wi a dependent of wj, and Right-Arc makes wj a dependent of wi. The one that's the dependent disappears from the stack and we add a dependency arc to our arc set A. We typically also specify the grammatical relation connecting the two.
Example: "I ate fish"
σ: [root]
β: I ate fish
A: {}
The only option is to shift.
σ: [root] I
β: ate fish
A: {}
New we could reduce, making I a dependent of root, but that would be wrong because I is not the head of the sentence. Instead we should shift again.
σ: [root] I ate
β: fish
A: {}
Now we can do a Left-Arc reduce to make I a dependent of ate.
σ: [root] ate
β: fish
A: {nsubj(ate -> I)}
Next we should shift fish onto the stack.
σ: [root] ate fish
β:
A: {nsubj(ate -> I)}
And then we can do a Right-Arc reduce, meaning that ate is the object of fish.
σ: [root] ate
β:
A: {nsubj(ate -> I), obj(ate -> fish)}
And finally we can do a Right-Arc reduce to say that ate is the root of the whole sentence.
σ: [root]
β:
A: {nsubj(ate -> I), obj(ate -> fish), root([root] -> ate)}
Now we've reached the end condition: β is empty and σ has a single (root) element.
We've intuited how to do the right thing in this example, but in general how do we know which action to choose next? Naively exploring all of them will take exponential time. Hint: this is a machine learning class.
If we can write a ML classifier which can nearly always predict the next action given the state and buffer, we can build a greedy dependency parser which takes one word at a time and chooses the next action. This is linear in the length of the sentence rather than cubic (dynamic programming) or exponential (naive algorithm).
The classifier has 3 classes, or if you consider that there are ~20 relations R, 2|R| + 1 classes. The features are the top of stack word and its part of speech, the first word in the buffer and its part of speech, etc. You could do a beam search which keeps k good parse prefixes at each time step to improve performance. This model's accuracy is only a fraction worse than the best known ways to parse sentences. This very fast linear time parsing, with high accuracy, is great for parsing large corpora like the web.
Here's a way to do this with symbolic features. These indicators use conjunctions of 1-3 elements of the configuration, e.g.
s1.w = good && s1.t == JJ # the first word in the stack is "good" and is an adjective
s2.w = has && s2.t = VBZ && s1.w == good # the second word in the stack is the present tense "has" and the first word in the stack is "good"
The parsers have 1M - 10M features.
Evaluation
To evaluate a parser, the test set was hand-parsed in the treebank. We can write these dependencies as a set of arcs and a dependency type. Then the model will predict those same relations.
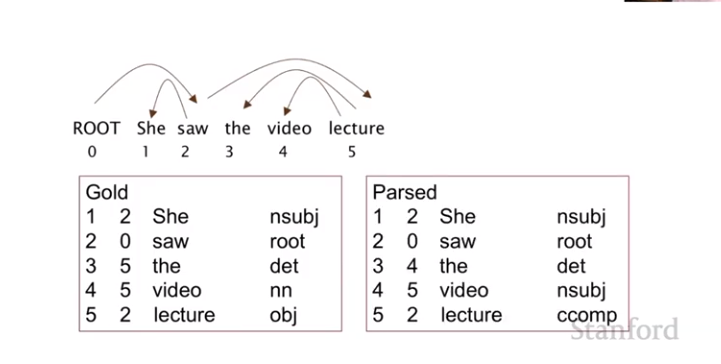
There are two evaluation criteria:
- Unlabeled accuracy score (UAS) - the arc (number in columns 1 and 2) is correct
- Labeled accuracy score (LAS) - the arc and the label are correct
In the figure above, the UAS is 80% and the LAS is 40%.