Lecture 11 - bancron/stanford-cs224n GitHub Wiki
Lecture video: link
This lecture covers question answering. The guest lecturer is Danqi Chen ([email protected]).
Question answering
The goal of question answering (QA) is to build systems that automatically answer questions posed by humans in natural language. The earliest QA systems dated back to the 1960s.
There are many types of QA problems that can require different techniques. A system may build on information sources such as a text passage, all Web documents, knowledge bases, structured databases, tables, images, etc. The question type could be factoid vs non-factoid, open-domain vs closed-domain, simple vs complex/compositional, etc. The answer type may be a short segment of text, a paragraph, a list, yes/no, etc.
There are many examples including Google search and Alexa. Another example: IBM Watson beat two Jeopardy champions in 2011.
In the deep learning era (as of 2021), almost all state-of-the-art question answering systems are built on top of end-to-end training and pretrained language models.
This lecture will mostly focus on how to answer questions based on unstructured text.
Knowledge-based QA can answer questions over a large database. These solutions convert the question into a logical form, then execute it against the database to give the final answer.
Visual QA, another class of problems, answers questions based on images. This requires an understanding of both the question and the image.
Reading comprehension
Reading comprehension means comprehending a passage of text and answering questions about it.
- (P, Q) -> A
Why do we care about this problem? It's useful for many practical applications. Reading comprehension is an important testbed for evaluating how well computer systems understand human language. Wendy Lehnert 1977: "Since questions can be devised to query any aspect of text comprehension, the ability to answer questions is the strongest possible demonstration of understanding."
Many other NLP tasks can be reduced to a reading comprehension problem.
One example is information extraction. Given a paragraph about Barack Obama, ask "Where did Barack Obama graduate from?" This could be parsed as (Barack Obama, educated_at, ?).
Another example is semantic role labeling. Given one sentence, figure out who did what to whom. "UCD finished the 2006 championship as Dublin champions by beating St Vincents in the final." Who finished something? -> UCD. What did someone finish? -> The 2006 championship.
Stanford question answering dataset (SQuAD)
This was collected in 2015 and consists of 100k (passage, question, answer) triples. Large-scale supervised datasets are also a key ingredient for training effective neural models for reading comprehension.
The passages are selected from English Wikipedia, usually 100-150 words. The questions are crowd-sourced. Each answer is a short segment of text (span) in the passage. This is a limitation - not all the questions can be answered in this way.
SQuAD still remains the most popular reading comprehension dataset; it is "almost solved" (as of 2021) and the state-of-the-art exceeds the estimated human performance.
There are two evaluation metrics: exact match (0 or 1), and F1 (partial credit). For development and testing sets, 3 gold answers are collected, because there could be multiple plausible answers. We compare the predicted answer to each gold answer (stop words and punctuation are removed) and take the maximum scores. Finally, we take the average of all the examples for both exact match and F1 to get the overall score. Estimated human performance: EM = 82.3, F1 = 91.2.
Example:
- Q: What did Tesla do in December 1878?
- A: {left Graz, left Graz, left Graz and severed all relations with his family}
- Prediction: {left Graz and severed}
- Exact match: max{0, 0, 0} = 0
- F1: max{0.67, 0.67, 0.61} = 0.67
Neural models for reading comprehension
How can we build a model to solve SQuAD? N.B. we are going to use passage, paragraph and context, as well as question and query interchangeably.
- Input: C = (c[1],...,c[N]), Q = (q[1],...,q[M])
- Output: 1 <= start <= end <= N. (A span in the passage.)
- N ~= 100, M ~= 15
There are two kinds of neural models that have solved this problem well. The first is a family of LSTM-based models with attention (2016-2018). The second is finetuned BERT-like models for reading comprehension (2019+).
Recall the seq2seq model with attention that we've been learning about. Some important changes:
- Instead of source and target sentences, we have two sequences: a passage and a question. The lengths are imbalanced.
- We need to model which words in the passage are most relevant to the question (and which question words).
- Attention is the key ingredient here, similar to which words in the source sentence are most relevant to the current target word.
- We don't need an autoregressive decoder to generate the target sentence word-by-word. Instead, we just need to train two classifiers to predict the start and end positions of the answer.
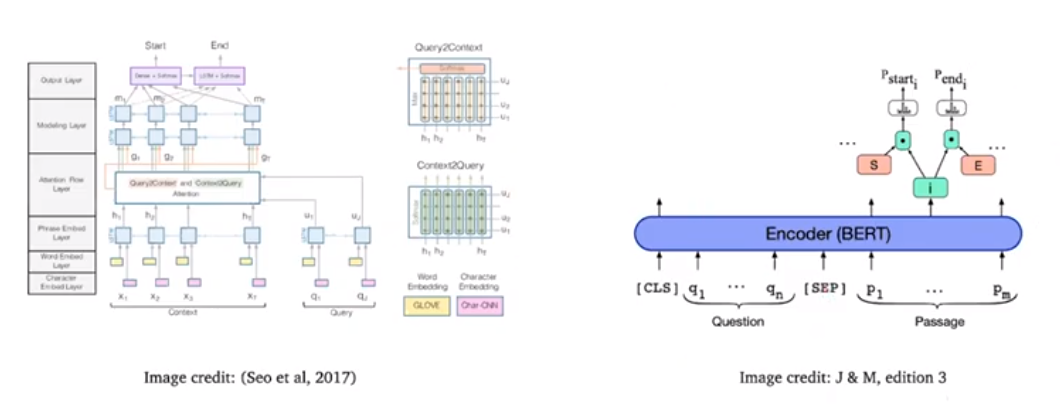
BiDAF: the Bidirectional Attention Flow model

Embed layer
First look at the bottom three Embed (encoding) layers, Character Embed Layer, Word Embed Layer, and Phrase Embed layer. We will use a concatenation of the word embedding (GloVe) and character embedding (convolutional neural network over character embeddings) for each word in the context and query.
Then use two bidirectional LSTMs separately to produce contextual embeddings for both tho context and query.


We need this to be bidirectional to capture both the left and right context.
Attention layer
The next layer is the Attention layer. It captures the interaction between the context and the query.
There are two types. The first is the context-to-query attention: for each context word, choose the most relevant words from the query words.

The second is the reverse, query-to-context attention: choose the context words that are most relevant to one of the query words.

First, we compute a similarity score for every pair (c[i], q[j]) from the embed layer by concatenating c[i], q[j], and their elementwise product.
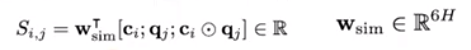
Calculate the context-to-query attention (which words are more relevant to c[i]). Take the softmax of the similarity matrix S[i,j] over all the question words. Then take the weighted combination of the attention score α[i,j] and the question score q[j].

Finally calculate the query-to-context attention (which context words are relevant to some question words). For each row S[i,j], compute the softmax over all context words to get β[i], how important this context word is to the question. Then take the weighted combination of β[i]c[i].

Q&A. (The answers are not very good, as Manning seems to agree.)
Q: Why is context-to-query and query-to-context not symmetric? A: The final goal is to find a span in the passage - we want to find the question attention, not the context attention. For the context words, we want to find which context words are relevant or irrelevant.
Q: Is there a reason why we use both query-to-context and context-to-query attention - could we use just one? A: It works better using both.
Q: How did we come up with this complicated expression for g[i]? A: We tried a lot of things and this worked well.
Q: In the query-to-context attention, why do we do a max inside the softmax? A: We are trying to measure importance of context word w.r.t. some question word. If the number is very low after taking the max, this number isn't very relevant.
Modeling layer and output layer
Modeling layer: pass g[i] to another two layers of bi-directional LSTMs. The attention layer is modeling interactions between the query and the context. The modeling layer is modeling interactions within context words.

The output layer is two classifiers prediction the start and end position. First we concatenate g[i] and m[i], and take the dot product with w[start] with each vector in the context and apply the softmax, to get the probability that position i is the start position of the final span. For the end position, we do something similar but first pass m[i] to another bidirectional LSTM to get m'[i].
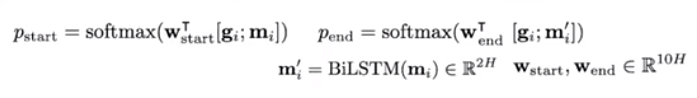

Performance on SQuAD
This model achieved 77.3 F1 on SQuAD v1.1. Without context-to-query attention this drops to 67.7 F1; without query-to-context attention it drops to 73.7 F1; without character embeddings, it drops to 75.4 F1.
Here's a visualization of attention:

BERT for reading comprehension
Recall that BERT is a deep bidirectional Transformer encoder pretrained on large amounts of text (Wikipedia + BooksCorpus). It is pretrained on two training objectives: Masked Language Model (MLM) and Next Sentence Prediction (NSP).
We can formulate the problem where the Question is Segment A, the Passage is Segment B, and the Answer is two points in Segment B.
[CLS] How many ... have ? [SEP] BERT ... large

h[i] is the output from the BERT encoder.
All the BERT parameters (e.g. 110M) as well as the newly introduced parameters h[start] and h[end] (e.g. 768*2 = 1536 params) are optimized together for the loss. It works amazingly well. Stronger pretrained language models can lead to even better performance, and SQuAD has become a standard dataset for testing pretrained models.
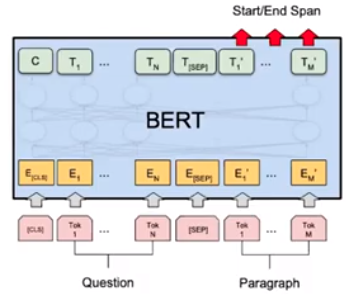
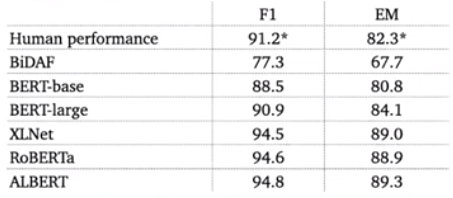
Comparison between BiDAF and BERT models
The BERT model has many more parameters (110M or 330M) vs BiDAF's 2.5M parameters. BiDAF is build on top of several bidirectional LSTMs while BERT is built on top of Transformers (no recurrence architecture and easier to parallelize). BERT is pretrained while BiDAF is only built on top of GloVe (and all the remaining parameters need to be learned from the supervision datasets).
Pretraining is clearly a game changer but it is expensive.
Are they really fundamentally different? Probably not.
BiDAF and other models aim to model the interactions between question and passage.
BERT uses self-attention between the concatenation of question and passage = attention(P, P) + attention(P, Q) + attention(Q, P) + attention(Q, Q).
(Clark and Gardner, 2018) shows that adding a self-attention layer for the passage attention(P, P) to BiDAF also improves performance.
Q: can we do well with a transformer that isn't pretrained? A: it does work, but we probably can't build a model as big as 110M parameters. There is a model QANet from Google which isn't pretrained - it outperforms BiDAF but is not as good as BERT.
Can we design better pretraining objectives?
Yes. The speaker worked on SpanBERT. This proposed two ideas:
- Masking contiguous spans of words instead of 15% of words randomly.
- Using the two end points of the span to predict all the masked words in between = compressing information of a span into its two endpoints.
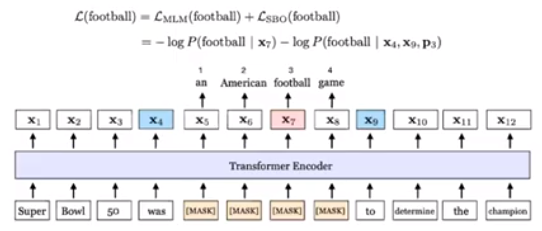
We want to use x[4] and x[9] from the figure above to predict all the words in the span.
Is reading comprehension solved?
We have already surpassed human performance on SQuAD. Does that mean that reading comprehension is already solved? Of course not! The current systems still perform poorly on adversarial examples and examples from out-of-domain distributions.
Adversarial examples:

Systems trained one dataset failing to generate to other datasets:

Open-domain question answering
This is a different problem from reading comprehension. We don't assume a given passage.
Instead, we only have access to a large collection of documents (e.g. Wikipedia). We don't know where the answer is located, and the goal is to return the answer for any open-domain questions. This is a much more challenging but more practical problem. (Open-domain is contrasted with closed-domain systems that deal with questions under a specific domain such as medicine or technical support.)
Chen et al., 2017 Reading Wikipedia to Answer Open-domain Questions (this lecturer).
There is a Document Retriever and Document Reader component. The retriever retrieves a set of documents that may be relevant, and the reader reads through all the documents to find the answer.
- Input: a large collection of documents D = D[1], ..., D[N]; and Q.
- Output: an answer string A
- Retriever f(D, Q) -> P[1], ..., P[k]. K is predefined (e.g. 100)
- Reader: g(Q, {P[1],...,P[k]) -> A. This is a reading comprehension problem.
In DrQA:
- Retriever = A standard TF-IDF information-retrieval sparse model (a fixed module)
- Reader = A neural reading comprehension model that we just learned
- Trained on SQuAD and other distantly-supervised QA datasets.
- Distantly-supervised examples: (Q, A) -> (P, Q, A)
We can train the retriever too
Joint training of the retriever and reader. Each text passage can be encoded as a vector using BERT and the retriever score can be measured as the dot product between the question representation and passage representation. (Leet et al., 2019. Latent Retrieval for Weekly Supervised Open Domain Question Answering.) However, it is not easy to model as there are a huge number of passages (e.g. 21M in English Wikipedia).
Dense passage retrieval (DPR) - We can also just train the retriever using question-answer pairs. Trainable retriever (using BERT) largely outperforms traditional IR retrieval models. (Karpukhin et al. 2020. Dense Passage Retrieval for Open-Domain Question Answering.)
Large language models can do open-domain QA as well
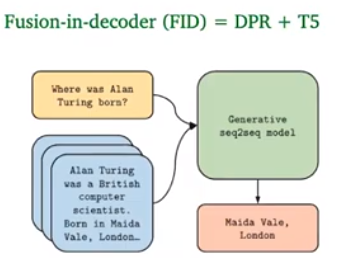
Open-domain QA without an explicit retriever stage. Take a pre-trained LLM T5, and fine-tune.
Maybe the reader model is not necessary either
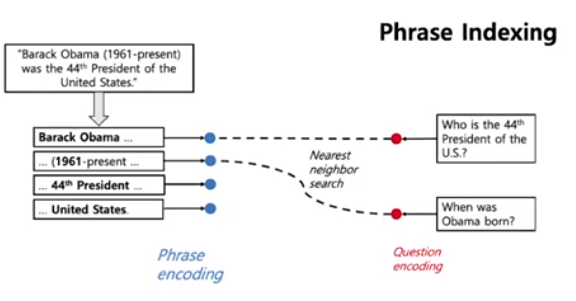
It is possible to encode all the phrases (60 billion phrases in Wikipedia) using dense vectors and only do nearest neighbor search without a BERT model at inference time.
Dense retrieval and generative models
Recent work shows that it is beneficial to generate answers instead of extracting answers.