All From GPT part3 - ayushmathur94/Spark GitHub Wiki
Core Spark concepts such as Resilient Distributed Datasets (RDDs), DataFrames, Datasets, and Spark SQL are the building blocks of Spark applications.
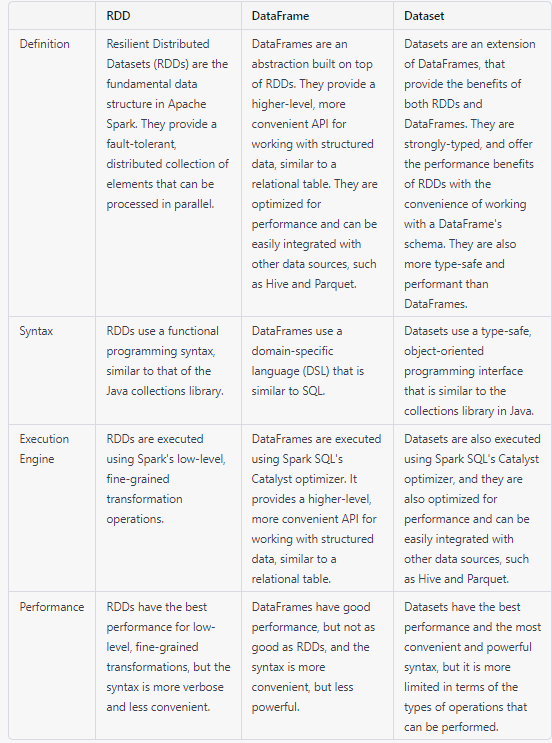
Resilient Distributed Datasets (RDDs) : RDDs are the fundamental data structure in Spark. They are a collection of elements that can be processed in parallel. RDDs are fault-tolerant, meaning that if a node fails, the data on that node can be recomputed from the data on other nodes. Here is an example of creating an RDD from a file in Java:
JavaSparkContext sc = new JavaSparkContext(new SparkConf().setAppName("MyApp"));
JavaRDD rdd = sc.textFile("path/to/file");
DataFrames : DataFrames are an abstraction on top of RDDs. They provide a higher-level API for working with structured data. DataFrames have a schema, which is a description of the data types and column names of the data. The schema allows Spark to optimize the execution of queries on DataFrames. Here is an example of creating a DataFrame from a file in Java:
SparkSession spark = SparkSession.builder().appName("MyApp").getOrCreate();
Dataset df = spark.read().json("path/to/file");
Datasets : Datasets are an extension of DataFrames. They provide the benefits of both RDDs and DataFrames: the performance of RDDs and the type safety and schema of DataFrames. Here is an example of creating a Dataset from a file in Java:
SparkSession spark = SparkSession.builder().appName("MyApp").getOrCreate();
Dataset ds = spark.read().json("path/to/file").as(Encoders.bean(Person.class));
In this example, Person is a custom Java class that represents the data in the file. The Encoders.bean(Person.class) method is used to tell Spark how to convert the JSON data to instances of the Person class.
Spark SQL : Spark SQL is a module for working with structured data using SQL. It allows you to express complex data processing tasks using SQL queries, and Spark will convert these queries to code that runs on the RDDs, DataFrames, or Datasets. Here is an example of querying a DataFrame using Spark SQL in Java:
SparkSession spark = SparkSession.builder().appName("MyApp").getOrCreate();
Dataset df = spark.read().json("path/to/file");
df.createOrReplaceTempView("people");
Dataset filteredDF = spark.sql("SELECT * FROM people WHERE age > 30");
In this example, a temporary table named "people" is created from the DataFrame, and a SQL query is executed to select all rows where the age is greater than 30. The result is a new DataFrame containing the filtered data.
The trade-offs between RDDs, DataFrames, and Datasets are:
RDDs provide the most flexibility, but require more code to handle the low-level details of data processing. DataFrames provide a higher-level API and improved performance, but lack the type safety of Datasets. Datasets provide the best of both worlds: the performance of RDDs and the type safety and schema of DataFrames, but they are only available in the Java and Scala APIs.
In general, it's recommended to use DataFrames or Datasets when possible, as they provide better performance and ease of use compared to RDDs. However, if you have specific requirements that cannot be met by DataFrames or Datasets, or if you need to perform complex, low-level operations on your data, then you may need to use RDDs.
DataFrames and Datasets are similar in that they both provide a higher-level API for working with structured data, but Datasets offer the added benefit of type safety and schema validation. This means that if you have a well-defined schema for your data and you want to ensure that your code is working with the correct data types, then using Datasets is the better choice.
In terms of performance, DataFrames and Datasets have similar performance characteristics. However, DataFrames are generally faster than Datasets when working with primitive data types, while Datasets are generally faster than DataFrames when working with complex data types.
In conclusion, RDDs, DataFrames, and Datasets are all powerful tools in the Spark ecosystem, and depending on the use case, one may be more suitable than the others. A 4+ years experienced developer should have a deep understanding of each of these concepts and should be able to choose the right one for a given use case, and should also be able to write Spark code in both RDD and DataFrame/Dataset API's.
RDD
Here are five simple examples of using RDDs in different scenarios:
1.) Loading data from a file: You can create an RDD by reading data from a file. This is the most common use case for RDDs.
JavaSparkContext sc = new JavaSparkContext(new SparkConf().setAppName("MyApp"));
JavaRDD rdd = sc.textFile("path/to/file");
In this example, the textFile method is used to read the contents of a text file and return an RDD of strings, where each string represents a line of the file.
Full class :
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class LoadData {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("MyApp");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD rdd = sc.textFile("path/to/file");
}
}
2.) Filtering data: You can use RDDs to filter data based on a given condition.
JavaRDD rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5)); JavaRDD filteredRdd = rdd.filter(x -> x > 3);
In this example, an RDD of integers is created using the parallelize method. Then a filter function is used to keep only the elements of the RDD that are greater than 3. The resulting RDD contains only the values 4 and 5.
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class FilterData {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("MyApp");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
JavaRDD filteredRdd = rdd.filter(x -> x > 3);
}
}
3.) Transforming data: You can use RDDs to transform data by applying a function to each element.
JavaRDD rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5)); JavaRDD transformedRdd = rdd.map(x -> x * 2);
In this example, an RDD of integers is created using the parallelize method. Then a map function is used to multiply each element by 2. The resulting RDD contains the values 2, 4, 6, 8, and 10.
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class TransformData {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("MyApp");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
JavaRDD transformedRdd = rdd.map(x -> x * 2);
}
}
4.) Aggregating data: You can use RDDs to aggregate data by applying a reduce function.
JavaRDD rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5)); int sum = rdd.reduce((x, y) -> x + y);
In this example, an RDD of integers is created using the parallelize method. Then a reduce function is used to sum up all the elements of the RDD. The resulting value is the sum of 1 + 2 + 3 + 4 + 5 = 15
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class AggregateData {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("MyApp");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
int sum = rdd.reduce((x, y) -> x + y);
}
}
- Grouping data: You can use RDDs to group data by a key.
JavaPairRDD rdd = sc.parallelizePairs(Arrays.asList(new Tuple2("A", 1), new Tuple2("B", 2), new Tuple2("A", 3)));
JavaPairRDD> groupedRdd = rdd.groupByKey();
In this example, an RDD of Tuples is created using the parallelizePairs method. The Tuples contain a string and an integer. Then a groupByKey function is used to group the elements of the RDD by the string key. The resulting RDD contains a Tuple that has a string key and an iterable of integers, that is all the integers of the same key are together.
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class GroupData {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("MyApp");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaPairRDD rdd = sc.parallelizePairs(Arrays.asList(new Tuple2("A", 1), new Tuple2("B", 2), new Tuple2("A", 3)));
JavaPairRDD> groupedRdd = rdd.groupByKey();
}
}
All of these examples demonstrate the basic operations that can be performed on RDDs: loading data, filtering, transforming, aggregating, and grouping.
In each of these classes, the main method contains the code for the corresponding example. You can run them by creating a jar file and submit that to Spark cluster or you can run them on a standalone mode on your local machine.
give me example of how to load multiple csv files present in one hdfs directory to one dataset
Here is an example of loading multiple CSV files present in one HDFS directory to a single Dataset in Java:
SparkSession spark = SparkSession.builder().appName("MyApp").getOrCreate();
// Define the schema for the CSV data
StructType schema = new StructType()
.add("name", "string")
.add("age", "integer")
.add("city", "string");
// Read all the CSV files from the directory
Dataset df = spark.read()
.schema(schema)
.csv("hdfs://namenode:8020/path/to/directory/*.csv");
// Optionally, you can also filter out specific files using a glob pattern
//Dataset df = spark.read()
// .schema(schema)
// .csv("hdfs://namenode:8020/path/to/directory/file_*.csv");
In this example, the read method is used to load all the CSV files in the specified directory. The schema method is used to define the schema for the CSV data, which is required for loading the data into a Dataset. The csv method is used to specify the directory containing the files. And the * is used to load all the csv files present in that directory.
You can also use a glob pattern to filter out specific files, for example, you can use the pattern file_*.csv to only load files that start with file_.
Please note that you need to replace the hdfs path with the actual path of directory containing csv files and also you need to have hdfs configurations in your classpath to run this example
also you need to have hdfs configurations in your classpath to run this example . what are exact configurations required for this if running in yarn cluster ?
When running in a YARN cluster, you will need the following configurations in your classpath to read from HDFS:
hadoop-common: This library contains the common utilities that support the other Hadoop modules. hadoop-hdfs: This library contains the HDFS client classes. hadoop-client: This library contains the client classes for the Hadoop Distributed File System (HDFS) and the Hadoop YARN framework. You will also need to configure the HADOOP_CONF_DIR environment variable to point to the directory containing your Hadoop configuration files. This is where the core-site.xml and hdfs-site.xml configuration files are located.
Additionally, you may need to configure the following properties:
fs.defaultFS: The HDFS Namenode URI. It should be set to hdfs://namenode:8020 yarn.resourcemanager.address: The YARN Resource Manager address. It should be set to the hostname or IP address of the YARN Resource Manager. yarn.application.classpath: The classpath for running YARN applications. It should include the Hadoop libraries and any additional libraries needed by your application. You can set these properties in the code or you can set them in the yarn-site.xml file
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>resourcemanager-host:8032</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value>
</property>
This configuration sets the classpath for running YARN applications and includes the necessary Hadoop libraries as well as any additional libraries that your application may need.
It is worth noting that, for a more robust and flexible approach, you can use a dependency management tool such as Maven or Gradle to include the necessary dependencies in your project, this will automatically download all the required jars from maven repository and adding them to classpath, making sure that all dependencies are met.
how to connect hdfs with java spark code in cluster mode
To connect HDFS with Java Spark code in cluster mode, you will need to configure the HDFS connection properties in your Spark code and set the HADOOP_CONF_DIR environment variable.
Here is an example of how to configure the HDFS connection properties in your Spark code:
// Create a SparkConf object
SparkConf conf = new SparkConf().setAppName("MyApp");
// Set the HDFS configuration properties
conf.set("fs.defaultFS", "hdfs://namenode:8020");
conf.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
conf.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName());
// Create a SparkContext object
JavaSparkContext sc = new JavaSparkContext(conf);
To set the HADOOP_CONF_DIR environment variable, you will need to add the following line of code to your Spark code before creating the SparkContext:
System.setProperty("HADOOP_CONF_DIR", "path/to/hadoop/conf");
This will set the environment variable to the directory containing the Hadoop configuration files.
In addition to this, you also need to make sure that all the required Hadoop libraries are available in the classpath of the Spark job. You can achieve this by including the required libraries in the classpath of the Spark job when running it, typically this is done by adding them to the classpath of the cluster manager (YARN, Mesos, etc.)
You can also use a dependency management tool such as Maven or Gradle to include the necessary dependencies in your project and adding them to classpath.
Please note that these configurations and libraries are required for the Spark job to connect and interact with the HDFS cluster.
ok now give me combined code for above sample and also extending code functionality to read a file from hdfs
Sure, here is an example of a complete Java Spark code that configures the HDFS connection properties and reads a file from HDFS:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class ReadHDFSFile {
public static void main(String[] args) throws Exception {
// Set the HADOOP_CONF_DIR environment variable
System.setProperty("HADOOP_CONF_DIR", "path/to/hadoop/conf");
// Create a SparkConf object
SparkConf conf = new SparkConf().setAppName("MyApp");
// Set the HDFS configuration properties
conf.set("fs.defaultFS", "hdfs://namenode:8020");
conf.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
conf.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName());
// Create a SparkContext object
JavaSparkContext sc = new JavaSparkContext(conf);
// Create a Configuration object
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://namenode:8020");
// Create a FileSystem object
FileSystem hdfs = FileSystem.get(configuration);
// Read the file from HDFS
Path filePath = new Path("hdfs://namenode:8020/path/to/file");
everytime do i have to give hdfs://namenode:8020/ before path to file
No, you do not have to always include the hdfs://namenode:8020/ prefix before the path to the file. This prefix is only necessary if you have set the fs.defaultFS property to a different value than the default one hdfs://localhost:9000.
In the example code I provided earlier, the fs.defaultFS property is set to hdfs://namenode:8020, so the full path including the prefix hdfs://namenode:8020 is required when creating the Path object.
However, if the fs.defaultFS property is set to the default value of hdfs://localhost:9000, you can simply provide the path to the file without the prefix.
Path filePath = new Path("/path/to/file");
Please note that you should use the correct path of your namenode and also the correct path of the file you want to read, the code I provided is just an example, you should replace it with the correct values for your cluster.
what is the role of core-site.xml and hdfs-site.xml ? At which path we keep them and do we have to configure them somewhere so that java spark job code can use them
core-site.xml and hdfs-site.xml are configuration files that are used by Hadoop to configure the HDFS and the Hadoop Common services.
core-site.xml contains the configuration settings for the Hadoop Common services such as the HDFS Namenode and the Hadoop Job Tracker. It typically contains settings such as the HDFS filesystem URI, the HDFS block size, and the HDFS replication factor.
hdfs-site.xml contains the configuration settings specific to HDFS, such as the location of the HDFS Namenode, the HDFS data block size, and the HDFS replica placement policy.
Both files are typically located in the $HADOOP_CONF_DIR directory, which is usually located under the Hadoop installation directory. For example, in a typical Hadoop installation, you would find these files in the $HADOOP_HOME/etc/hadoop directory.
To make these configuration files available to your Spark job, you will need to set the HADOOP_CONF_DIR environment variable to the directory containing these files before creating the SparkContext.
System.setProperty("HADOOP_CONF_DIR", "path/to/hadoop/conf");
You can also set the path of these configuration files to the classpath of your application so that spark job can use these files.
By setting the HADOOP_CONF_DIR environment variable, Spark will automatically use these configuration files when connecting to HDFS.
It's worth noting that you can also use the programmatic configuration way to set these properties, you can set these properties in your code, such as:
conf.set("fs.defaultFS", "hdfs://namenode:8020");
This will set the default filesystem to be hdfs and the namenode to namenode:8020, this way you don't need to set HADOOP_CONF_DIR or include core-site.xml and hdfs-site.xml files in the classpath.
In summary, core-site.xml and hdfs-site.xml are configuration files that are used by Hadoop to configure the HDFS and the Hadoop Common services. core-site.xml contains the configuration settings for the Hadoop Common services and hdfs-site.xml contains the configuration settings specific to HDFS. These files are typically located in the $HADOOP_CONF_DIR directory, which is usually located under the Hadoop installation directory. To make these configuration files available to your Spark job, you will need to set the HADOOP_CONF_DIR environment variable
so if iam setting conf.set("fs.defaultFS", "hdfs://namenode:8020"); , i dont need to set System.setProperty("HADOOP_CONF_DIR", "path/to/hadoop/conf");
That is correct, if you set the HDFS properties programmatically in your Spark job code, you don't need to set the HADOOP_CONF_DIR environment variable.
By setting the fs.defaultFS property programmatically, Spark will use that value instead of looking for the configuration files in the HADOOP_CONF_DIR directory. This way you do not need to set the HADOOP_CONF_DIR environment variable or add the core-site.xml and hdfs-site.xml files to the classpath.
It's a good practice to provide the required properties programmatically rather than relying on the Hadoop configuration files, this way you have more control over the configuration of your Spark job and you can easily switch between different HDFS clusters.
what is the content of HADOOP_CONF_DIR
The HADOOP_CONF_DIR environment variable is used to specify the directory that contains the Hadoop configuration files. The content of the HADOOP_CONF_DIR directory typically includes the following files:
core-site.xml: Contains the configuration settings for the Hadoop Common services such as the HDFS Namenode and the Hadoop Job Tracker. hdfs-site.xml: Contains the configuration settings specific to HDFS, such as the location of the HDFS Namenode, the HDFS data block size, and the HDFS replica placement policy. yarn-site.xml: Contains the configuration settings for YARN (Yet Another Resource Negotiator), the resource manager in Hadoop. mapred-site.xml: Contains the configuration settings for the Hadoop MapReduce framework. workers: A file that lists the hostnames of the worker nodes in the Hadoop cluster. hadoop-env.sh: A shell script that sets up the environment for Hadoop, such as the JAVA_HOME and HADOOP_HOME environment variables. Additionally, it also contains some other files that are specific to the Hadoop version you are using and the specific configuration of your cluster.
It is worth noting that, in some cases, the HADOOP_CONF_DIR directory may also include additional libraries and resources that are required by the Hadoop services.
HADOOP_CONF_DIR sample value
The value of the HADOOP_CONF_DIR environment variable is the file system path to the directory that contains the Hadoop configuration files. The exact path will depend on your operating system and the location where you have installed Hadoop.
Here are a few examples of possible values for HADOOP_CONF_DIR:
On a Linux machine, if you have installed Hadoop in the /usr/local/hadoop directory, the value of HADOOP_CONF_DIR would be /usr/local/hadoop/etc/hadoop. On a Windows machine, if you have installed Hadoop in the C:\hadoop directory, the value of HADOOP_CONF_DIR would be C:\hadoop\etc\hadoop. On a Cloudera distribution, the value of HADOOP_CONF_DIR would be /etc/hadoop/conf Please note that these are just examples, the actual path of Hadoop configuration files depends on how and where you installed Hadoop on your system.
You can find the location of these files by running the command hadoop classpath on your command prompt, it will give you the path of configuration files.