ICP 7 - awais546/Python-and-Deep-Learning GitHub Wiki
Python and Deep Learning
Introduction
In this lab we learned about one of the most important module of AI known as natural language processing. We learned the basic topics of natural language processing like tokenization, stemming, lemmatization etc. The library used for natural language processing in python is NLTK.
Tasks
The tasks performed in this lab are as follows.
- Perform tokenization and apply SVM
- Extract the text from the URL and save it in the text file
- Perform NLTK processes on the text
Tokenization and SVM
The dataset used for this is fetch_20newsgroups. In order to import the SVM model you can apply the following code. from sklearn.svm import SVC
By comparing the SVM model with naive bayes model we see that SVM performed better. The accuracy is shown in the following screenshot.

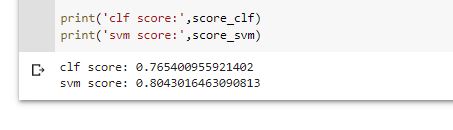
By changing the tdif vectorizer to bigram the accuracy of both the models have decreased as shown in the following screenshot.
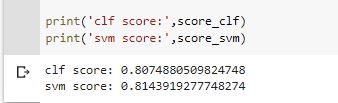
By adding the stop words argument as English we can see the the accuracy has increased more.
Extract text from URL
The texts from the url can be extracted using the Beautifulsoup4 library. The following code shows the method to extract and save it in the text file.
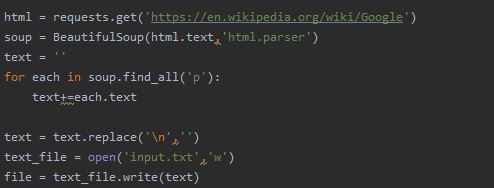
NLTK Operations
Tokenization
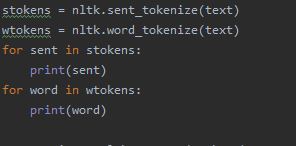
Tokenization can be performed using the following code.
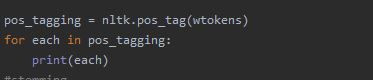
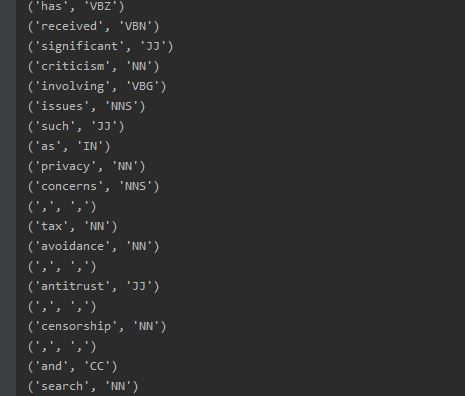
POS Tagging
To perform POS tagging use the following code.
Stemming
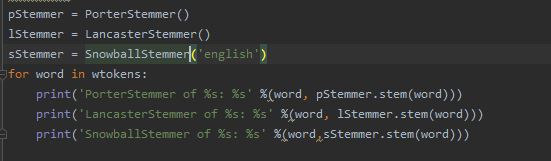
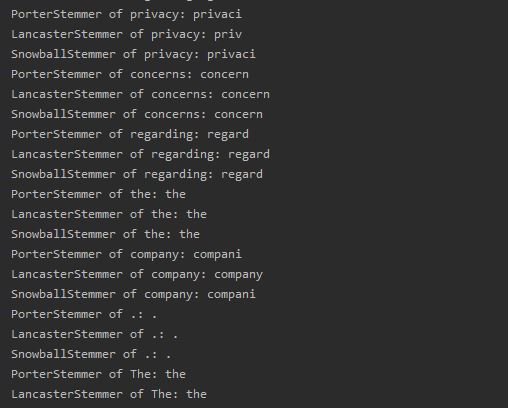
Three types of stemming is performed. The code is shown below.
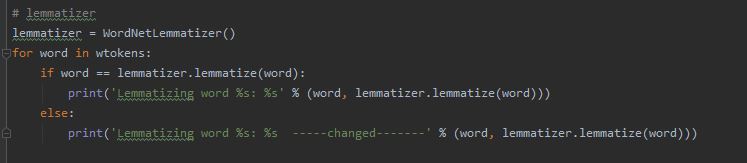
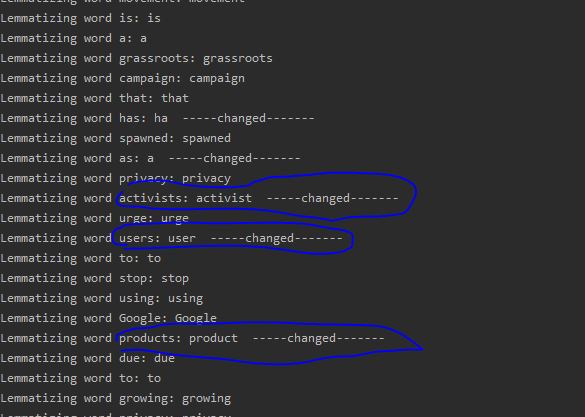
Lemmatization
Lemmatization can be performed using the following code.
Trigram
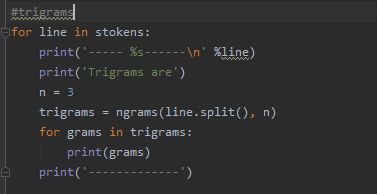
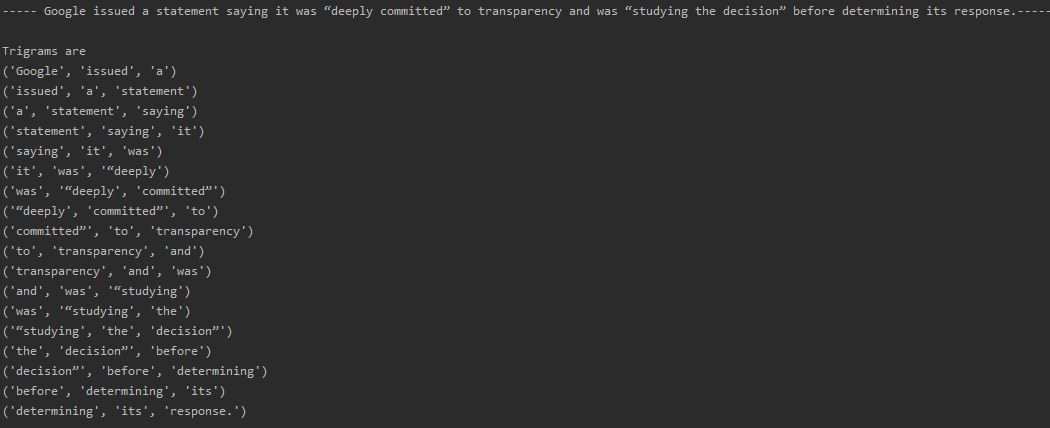
Trigram can be made using the following code. Trigram is applied on each sentence generated from the sentence tokenization.
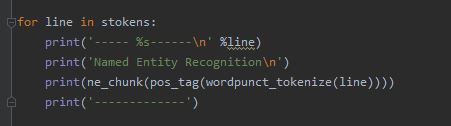
Named Entity Recognition
Use the following code for NER applied on each line of text.