ICP 3 - awais546/Big-Data-Programming-Hadoop-Pyspark GitHub Wiki
Big Data Programming ICP-3
Task
In this ICP the task was to multiply the two matrices using Map Reducer function.
In the code there are three classes and the names are as follows.
- MatrixMultiply
- Map
- Reduce
MatrixMultiply is the main class through which the job is created and the mapper and reducer functions are called by it.
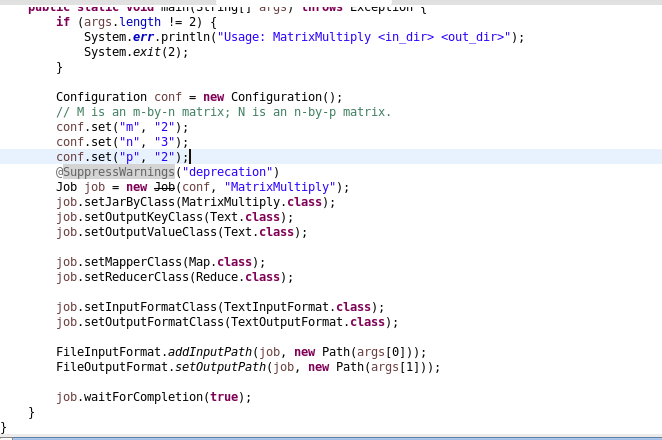
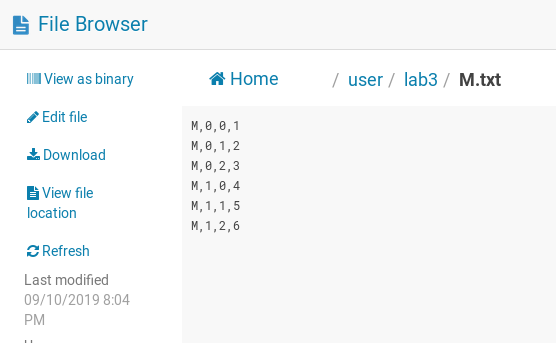
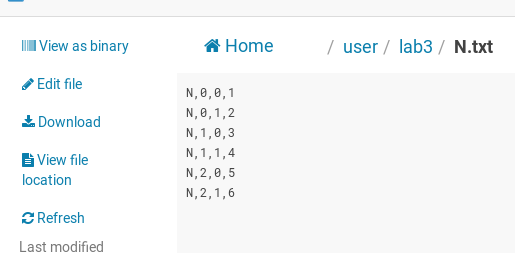
Input Files
There are two input files. Each input file contains one matrix. The M matrix is of 2x3 and N matrix is of 3x2.
Working
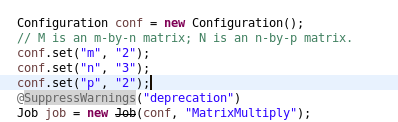
MatrixMultiply will get two arguments. First argument is the input directory containing the two text files. The second argument is the output directory in which our output file will be saved. We will create a configuration variable and will set some parameters inside it. We will set the values of rows and columns of our matrix in it. The screenshot below shows the setting of the configuration parameters.
Mapper function will get the input in the exact format which is present in the text files. The mapper function will pick up each line and split it on the basis of comma. After that it will create the key value pairs.
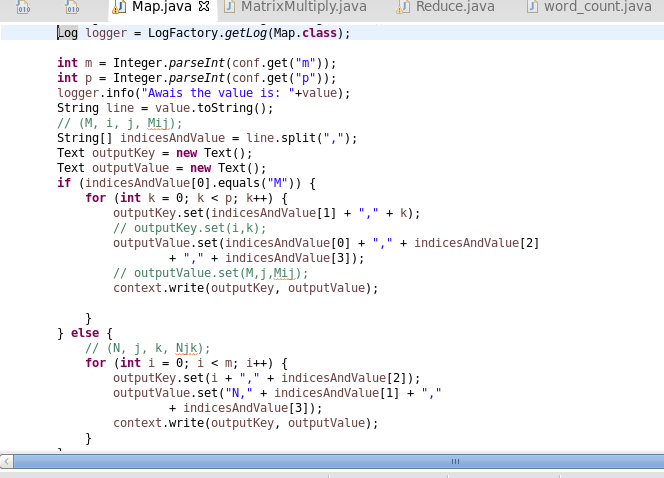
Shuffling is the process where it will take the keys values and convert it into keys and list of values by combining the values with same keys.

Reducer will take the keys and list of values and do the multiplication and corresponding addition which will give the final output having 2x2.
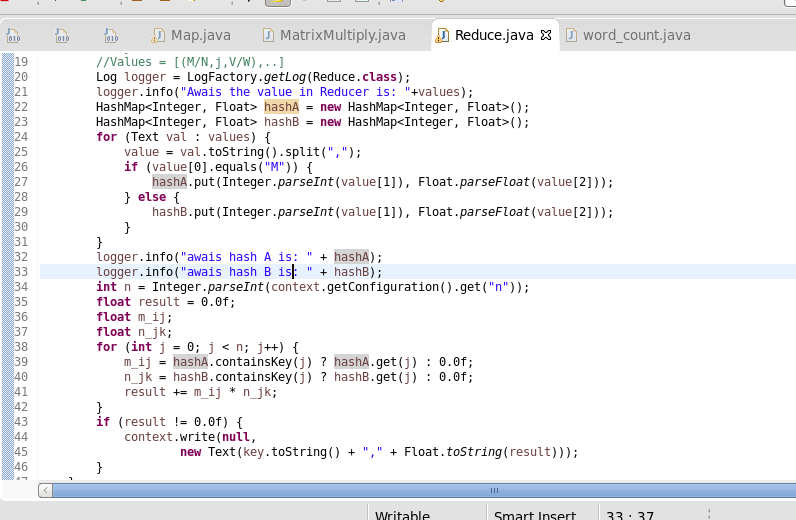
For Reference the go to the following link.
(https://lendap.wordpress.com/2015/02/16/matrix-multiplication-with-mapreduce/)