ICP 13 - awais546/Big-Data-Programming-Hadoop-Pyspark GitHub Wiki
Big Data Prgramming Hadoop/Pyspark
GraphFrames
Introduction
This ICP is the continuation of the previous ICP-12 of GraphFrames. In this lab we extended our functionalities and implemented some complex algorithms using graphframes.
Tasks
The tasks to perform in this lab are as follows.
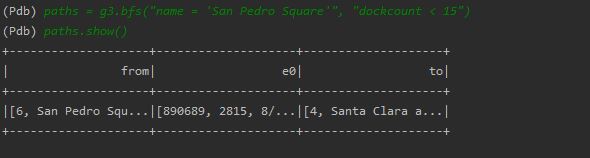
1. Import the dataset as a csv file and create data framesdirectly on import than create graph out of the data frame created.
To load the csv files in the data frame use the following command.
df_station = sqlContext.read.csv("Datasets\201508_station_Data.csv", inferSchema = True, header = True)
df_trip = sqlContext.read.csv("Datasets\201508_trip_data.csv", inferSchema = True, header = True)
To make a graphframe for the above made dataframes use the following command.
g2 = GraphFrame(df_station, df_trip)

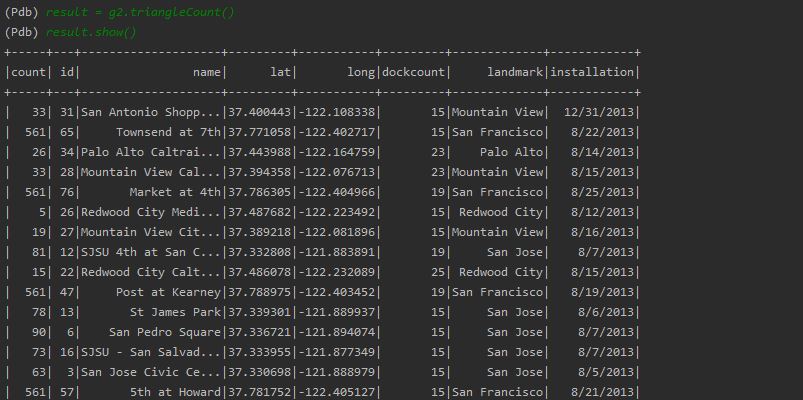
2. Triangle Count
To use the Triangle Count algorithm use the following command.
result = g3.triangleCount()
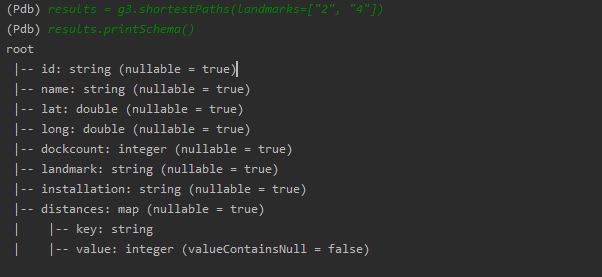
3. Find Shortest Paths w.r.t. Landmarks
In order to use this algorithm make sure that all data type of 'id', 'src' and 'dst' is string.
temp1 = df_station.withColumn("id", col("id").cast("string"))
The schema is as follows.
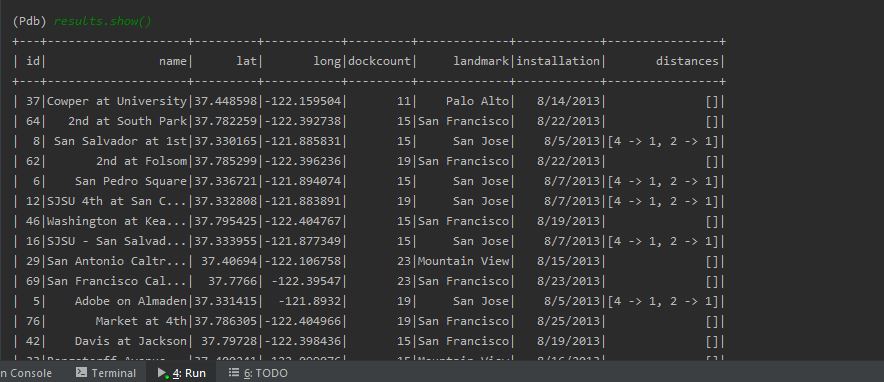
The output is as follows.
4. Apply Page Rank algorithm on the dataset.
Use the following command for Page Rank.
result3 = g.pageRank(resetProbability=0.15,tol=0.01)
Page rank gives us a graphframe.

The vertices are as follows.
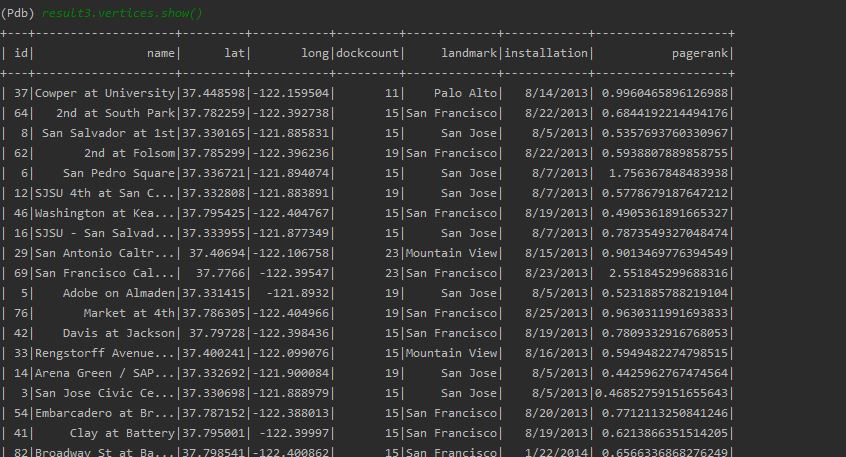
The edges are as follows.
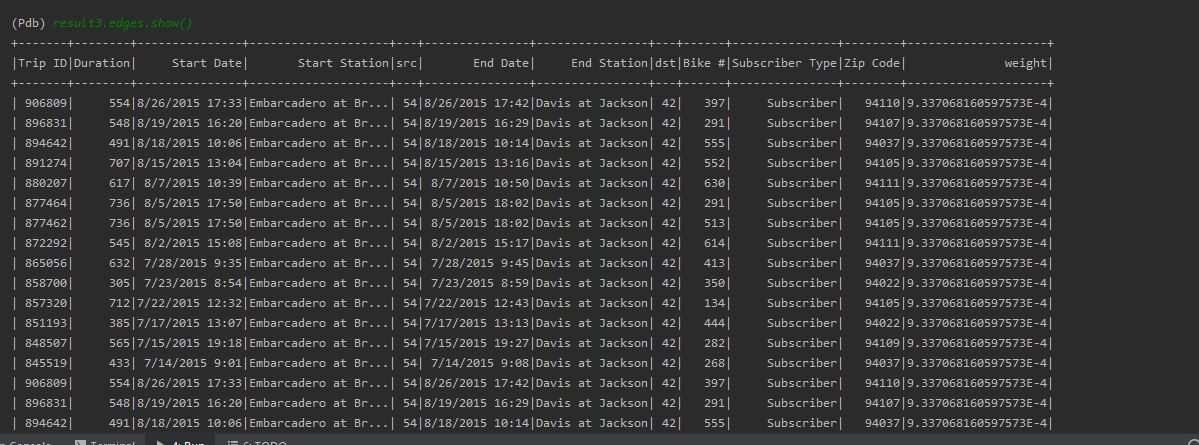
5. Save graphs generated to a file.
In order to save the graphframes we have to save the vertices and edges seperately.
g3.edges.write.parquet('saved_vertices')
g3.edges.write.parquet('saved_edges')
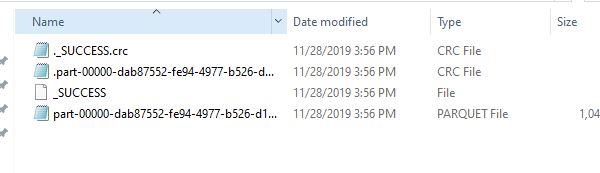
Bonuse Questions
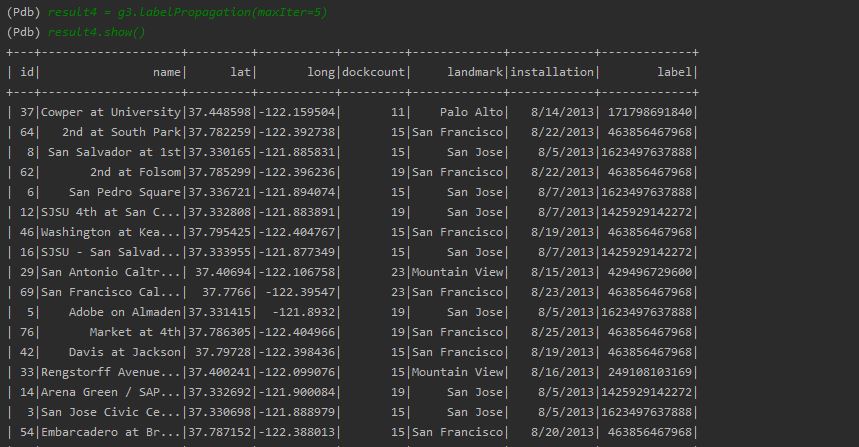
1. Apply Label Propagation Algorithm
Use the following command for label propagation.
result4 = g.labelPropagation(maxIter=5)
2. Apply BFS algorithm
In order to use BFS make sure the filter column names do not have spaces in it.