ml forex stock algo trading - andyceo/documentation GitHub Wiki
This is the lecture notes for the YouTube playlist
Source: Machine Learning and Pattern Recognition for Algorithmic Forex and Stock Trading: Intro
Link in video's description: Machine Learning and Pattern Recognition for Algorithmic Forex and Stock Trading
Hello and welcome to my tutorial on machine learning and programming for the use of Forex or stock trading and analysis with the programming.
We're going to be using the Python programming language specifically Python 2.7. We're gonna be using Python mainly for its user-friendliness plus it's my programming language of choice, but it also makes a good teaching programming language.
The purpose of the series is to teach you some of the principles to machine learning backtesting statistical analysis and some programming, not to influence your trading decisions. This is my verbal legal statement. This video series is for educational purposes only, and is not an offer or suggestion to deal with any financial markets. How you use this information is completely your responsibility, and I'm not to be held liable. okay, sounds good.
Our goal here is to use very basic machine learning principles to locate actionable trading rules within stocks or Forex. Now I say basic for two reasons.
One, I'm gonna do my best to keep things purposely pretty basic, both mathematicians and stock traders alike. Tend to use big words to purposely make things sound more special than they really are, or maybe make themselves feel better, uh-huh. You're not gonna really find any tie here or at least I'm gonna do my best to keep it simple.
Two, we're going to be doing most of these things by hand. The idea here is to help you all grow in all of those fields mentioned above. There's plenty of pre-made packages for things like support vector machines and neural networks. The problem here, in my opinion, is this doesn't actually teach you anything and it leaves no room for innovation.
Now, using basic machine learning principles to find the algorithm, that's going to be our first step, and that's usually the step most people finish on whether or not they use machine learning. The next question is not only to backtest the algorithm you've found, what's actually going to end up happening is: we're going to wind up with a quote-unquote "live trading algorithm", which basically means it's going to change over time, it will be a dynamic algorithm.
We're also going to do the next, in my opinion, very important step. That's the backtest that method that was used to find that algorithm. So what I mean by this is the following. It's with statistical certainty that if you look at a data set that you can find the best fit line, right? That's nothing special. We see this all the time when someone said: "hey look what I found! You know, here's this back tested strategy and it makes X amount of money!" That's no good, right?
The true test is the forward test, the test on unseen and unaccounted for data. Therefore, if you've created a sort of quote-unquote algorithm to define or derive the best trading strategy, then that algorithm used to find that strategy, right? The method to find that strategy must also have worked in the past against its quote unquote theoretical or actual literal future results, right? So you should also test that strategy against data you've in theory not seen, so you can't actually backtest that method itself. And this is basically to decide whether or not it would have worked to use that method in the past to find an algorithm that you would have also done some back testing on. Anyway, if you're just looking at the data set you found the best algo for that, you know, including the backtesting, that's really cheating, and the likelihood of that algorithm continuing app out in the future is statistically unfavorable.
So, now that we've swallowed that pill, let's go ahead and get all the tools and things that we'll need to do this. So first we are on sentdex.com, which is my website, and all we're here for mostly is a file. I do suggest you guys take a peek around, but that's not what we're here for, I'm not trying to sell you all anything.
What we're going to look for is the zip file. I've got two files located within that zip file and to find that you're gonna go to sentdex.com/GBPUSD.zip, hit enter and that should download a zip file and that zip file is going to contain two files within it. And these are the two files that you'll find: the first files GBPUSD Forex ratio for one day (GBPUSD1d.txt), and the other file the GBPUSD ratio for one month (GBPUSD1m.txt). Obviously you are need to extract this. Once you've extracted it you can open up either of these, so, open this one, and you'll find yourself looking at one day is worth a forex data. I didn't cheat you guys or give you guys nothing to work with. This is actually, as you can see, 62Mb of data. It's bid-ask tick data for this Forex ratio, so it's pretty good data to train on to start with. The next file is a one month of the month May, so you've got a now, you've got a month's worth which is, actually, just over one point one point six million lines here so a lot of lines to work with and a lot of data to work with. So it should be pretty fun to use them. The reason why I split them up is every time we're trying to work with, at least, develop this program using only you know hundred thousand lines versus one million lines is gonna make a sizable difference so that's why we're going to do it that way.
Now back to all the other things that we need. We're going to need a few more things just besides this Forex data, of course. And I also want to stress that even though we are using Forex data, you can do these principles that we're going to go through, can be used obviously for stocks as well. So don't feel like if you're looking to do this with stocks that this isn't going to work out for you.
Now the next most important thing are quite possibly more important than even the tick data is that we go ahead and get Python and we're going to be looking for the Python 2.7. So to get Python go to python.org, then go to download and what you're want to download is not 3.3, you want 2.7.5 and depending on what operating system you have is going to be what you download. If you do have a 64-bit operating system I highly suggest that you download the 64-bit version of Python.
Next we have matplotlib. It is also... well first you get there with matplotlib.org then you will go well it used to be up here but I guess they've moved it on me right here downloads, and then here you get the downloader and again you're going to want to match the download of what version of Python you downloaded or your Windows. Again, I recommend 64-bit if you have a 64-bit system on. If you did download a 64-bit Python you must.
Subsequently, you're also going to need numpy. Now if you followed my rules and you've got a 64-bit version of Python maybe you're wondering why you get a 64-bit version of Python I've said this quite a few and/or quite a few times in most of my videos. The reason you get 64-bit verses 32-bit is because 64-bit has no memory limit... well, it has one but it's huge. 32-bit programs and applications are limited to 2gb of RAM usage maximum. So naturally if you have a relatively large file sizes you're going to max out that 2Gb of RAM pretty easily. That's why I recommend 64. But you'll be able to get through this entire tutorial series and you'll even be able to do some pretty cool stuff even with that two gigabyte limit so don't run away if that's you.
So if you did do that the next thing we need is numpy. What Python allows us to do is program. matplotlib is a package that works with Python that allows us to do graphing. And numpy is a helpful little tool for doing mathematical calculations. To get numpy if you followed everything up to this point and you do have 64-bit, you're going to need to go to this link here. I'll put all these links in the description especially this one, so it's harder to find or at least read (http://www.lfd.uci.net/~gohike/pythonlibs, not working now). What we want here and what this website is is it's a bunch of 64 that's a bunch of installers and it just includes 64-bit versions of a lot of packages that don't naturally or natively offer 64-bit installers so a good example of this is numpy which find here I use a Ctrl-F and type out numpy it's about halfway down the page, and again there is the installers here. If you do have only windows like a 32-bit you can also use the install link here or you can go to like sourceforge.net, I believe, and you can get the other numpy source code or the Installer depending on what kind of computer you're on.
So obviously, you know, if you've got like a Mac or something or if you're on like a Linux distribution something like that you can get in whatever but in the end just make sure you've got Python 2.7, matplotlib and numpy. When you're all done and you've installed all of these things you should be able to go to your Start bar and pull up the python command line. It'll probably be black and not like this but you can customize it so that's just why mine's white. Anyway you should be able to type these following things:
import matplotlib
import numpy
If you can't do those two things like if you go import and you actually spell a numpy right but this and you get this something has gone wrong so if you're having any trouble installing or you've got some sort of error going on feel free to post a comment below and I'll try to help you guys out.
So that's going to conclude the introduction to what we're going to be getting into and hopefully you guys are excited and as always thanks for watching thanks for your support your subscriptions and it's all next time.
@TODO: read youtube comments for that video. All others comments are read already.
Machine learning in any form, including pattern recognition, has of course many uses from voice and facial recognition to medical research. In this case, our question is whether or not we can use pattern recognition to reference previous situations that were similar in pattern. If we can do that, can we then make trades based on what we know happened with those patterns in the past and actually make a profit?
To do this, we're going to completely code everything ourselves. If you happen to enjoy this topic, the next step would be to look into GPU acceleration or threading. We're only going to need Matplotlib (for data visualization) and some NumPy (for number crunching), and the rest is up to us.
Python is naturally a single-threaded language, meaning each script will only use a single cpu (usually this means it uses a single cpu core, and sometimes even just half or a quarter, or worse, of that core).
This is why programs in Python may take a while to computer something, yet your processing might only be 5% and RAM 10%.
To learn more about threading, you can view the threading tutorial on this site.
The easiest way to get these modules nowadays is to use pip install.
Don't know what pip is or how to install modules?
Pip is probably the easiest way to install packages. Once you install Python, you should be able to open your command prompt, like cmd.exe on windows, or bash on linux, and type:
pip install numpy
pip install matplotlib
Having trouble still? No problem, there's a tutorial for that: pip install Python modules tutorial.
If you're still having trouble, feel free to contact us, using the contact in the footer of this website.
Finally, you will need: Forex Tick Dataset For This Tutorial
The plan is to take a group of prices in a time frame, and convert them to percent change in an effort to normalize the data. Let's say we take 50 consecutive price points for the sake of explanation. What we'll do is map this pattern into memory, move forward one price point, and re-map the pattern. For each pattern that we map into memory, we then want to leap forward a bit, say, 10 price points, and log where the price is at that point. We then map this "outcome" to the pattern and continue. Every pattern has its result.
Next, we take the current pattern, and compare it to all previous patterns. What we'll do is compare the percent similarity to all previous patterns. If their percent similarity is more than a certain threshold, then we're going to consider it. From here, maybe we have 20-30 comparable patterns from history. With these similar patterns, we can then aggregate all of their outcomes, and come up with an estimated "average" outcome. With that average outcome, if it is very favorable, then we might initiate a buy. If the outcome is not favorable, maybe we sell, or short.
For visualization, here's an example: pattern recognition tutorial
{kind=link}
In the above example, the predicted average pattern is to go up, so we might initiate a buy.
This series will not end with you having any sort of get-rich-quick algorithm. There are a few known bugs with this program, and the chances of you being able to execute trades fast enough with this tick data is unlikely, unless you are a bank. The goal here is to show you just how easy and basic pattern recognition is. As long as you have some basic Python programming knowledge, you should be able to follow along.
The next tutorial: Quick look at our data
In this video, we are looking at and displaying the data that we are working with, and matplotlib.
Source: Machine Learning and Pattern Recognition for Algorithmic Forex and Stock Trading: Intro
Tutorial page: Quick Look at our Data
Hello and welcome to part two of machine learning and pattern recognition for use with stocks and forex trading. Now you might not realize it, but you've actually just made a huge accomplishment already, and that's that you're viewing part two.
You look at a lot of series on the internet especially tougher ones. It's usually at least a 25-40 percent drop off between part 1 and part 2, right, so you've already taken the initiative and you're already ahead and probably what's going to turn out to be of at least 25% of everyone else. So congratulations on being serious! If you continue devoting some time, soon you'll be in that top 1 to 5% and you'll have some cool new skills.
Also to give you a bit of a teaser: you're only just a few videos away from coding pattern recognition. They'd find something like this: this blue line is the patterning question and all these other lines are historical patterns that followed a closed pattern to this one and then what we'll end up doing is predicting the future results based on these past pattern results. Definitely something to be looking forward to, that's really only a few videos away.
The first thing that we really want to do is going to plot out the data that we have, so we can actually see what we're working with and see what our goals are.
Also be useful just to get comfortable with matplotlib we're going to be using at. So what we're going to run through is: opening up this data and looking at the data that we have first.
So we're going to need a few imports and that's going to be:
import matplotlib
and then we're going to go ahead and import some other stuff even though we've imported the
full matplotlib we also want to import various things as specific things, so we're also going to do:
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
import matplotlib dates as mdates
Finally we're going to
import numpy as np
Now we're going to do a function is going to be graphRawFX() and under here we're going to have a numpy open up this text file and create numpy array for us. So we're going to say:
date, bid, ask = np.loadtxt('GBPUSD1d.txt', unpack=True, delimiter=','
converters={0: mdates.strpdate2num('%Y%m%d%H%M%S')})
This is going to load up any text file you have. It can also do arrays even though it is called loadtxt() and the text we want to load up is going to be GBPUSD1d.txt. So if you got those files that I got or you got you can download from sentdex.com. If you take the zip, unzip it and there's two there should be two text files in there, one is GBPUSD one day and one is GBPUSD one month. Make sure both of those text files are in the same directory as this script. So not to folder the both text files. So if you just have the folder it's not going to find it, so you would need to put the folder in front. so just keep that in mind. I'm going to say unpack=True, and the delimiter of this file is a comma, and the converters (this is so we can convert a datestamp to plotting dates) and that's going to be the zeroth element, so the first element in there, and so let me just pull up the file real quick. This is our gbp/usd one day text file so you've got the datestamp and then bid-ask and here we can see year and then 05 is the month, 01 is the day and then hours minutes seconds. So we come back over here and our converters is going to be the zeroth element, wow do we want to convert this? use mdates and then we're going to use strpdate2num so strip date to num, and then in parentheses you give it the format that this is in, and you do it with percent and then a character that denotes whatever that is. So first we'll do %Y that's for a full year, then we do %m%d, so: month, day in number format; then %H for hours, %M%S. That's the whole thing. If you've had dashes or something in a date you would also put those in there, but again, we don't really have that it's just a straight stamp. So that's the conversion that we must make.
And come down here.. now the next thing we want to do is plot this: so we're going to define the figure that we're going to plot on and our figsize will be ten by seven:
fig = plt.figure(figsize(10,7))
Next, we're going to do a ax1 equals plt.subplot2grid(), and within here the grid we'll make is just a forty, forty, size we'll start the plot at the zero, zero, rawspan for 40, and colspan also equal forty:
ax1 = plt.subplot2grid((40, 40), (0, 0), rowspan=40, colspan=40)
If I'm going too fast at this point for you guys as far as defining how to make this chart then I highly suggest you check out the Python charting tutorial. I've got a whole series on all this stuff and it goes and way further depth than this. So if you do feel like you're lost, I highly suggest watch that, otherwise just kind of copy what I'm doing because honestly this part is not the main part of this series. We are just trying to display the data and we will continue displaying data. But this isn't really integral to the entire understanding of machine learning.
The next thing we want to do is to plot a date and bid:
ax1.plot(date, bid)
Then also we want to plot the date, ask:
ax1.plot(date, ask)
Then what we want to do is format the x-axis so it's in like date format, right? So:
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d %H:%M:%S'))
Date format: now you can choose anything you want so let's make this date a little bit prettier than it wasn't on the first time around, so: %Y-%m-%d %H:%M:%S.
Next the other thing we're going to do is:
plt.grid(True)
and
plt.show()
It's going to be kind of an ugly looking x- and y-axes ticks but you'll get what I'm saying in a minute so let's just bring this up and so run it, after you've saved of course.
It should pop up for you guys now and here is the data. There's a couple of things that are just kind of ugly about this data, right? You've got the date stamps are kind of running over each other, and the values over here are kind of being like converted because they have a lot of zeros and stick data and this data goes way past a pip, right? I think it goes to places past a typical pip.
Anyway this is our data, this is a one day of bid-ask tick data. The only really thing I wanted you guys to see is that it's, you know, we've got a fairly volatile day and overall at least on this day the data is rising but I believe in overall, true overall, we could bring up that data and I believe overall and for the month of May it was actually falling.
I got this error because it never we misspelled date formatter... Anyway that's the basic chart, that's the basic data that we're going to be dealing with and one of the interesting things about bid-ask... let me bring it back up again real quick... as you can see, the gap or this what's known as a spread and you can almost see pretty much every time the spread gets wide right it's either going to fall or go up right? Volatility is pretty much attracted to that spread which makes sense.
If more people like less people are willing to sell and that gap starts why not well it's probably the case that the stuff is going to go up or down same thing when it's crunches up right like here you've got scrunch up and like there's really no gap here because everyone's like chasing it, right? So there's also some pretty cool stuff that you can do with spread. However, we're not really going to be dealing with spread at least in the initial videos, we're going to be dealing with price change but the option is there for spread. In the next video I'm going to show you one more thing about spread and then we're actually going to continue on moving away from spread or at least moving without spread. But spread is definitely something you'll want to consider in the future if you do decide to go down this quant trading route.
So anyways that's going to include the second video in the third video let's we're going to at least show you a few more things about charting and we'll put up an interesting graph with spread and then from there we'll begin working on some patterns, setting up those and then the machine recognition of those patterns definitely some cool stuff to look forward to. If you're not subscribed I highly suggest you subscribe. Not going to release the series all at once so they'll just be coming out as I end up making the videos so if you're subscribed you should get something in your email or something that tells you that "hey I've got another video" or you can just keep checking back. Anyway that's going to include the video as always.
Thanks for watching thanks for all the support and subscriptions and until next!
In this video, we are briefly taking a closer look into the bid-ask spread before diving into pattern recognition.
Source: Machine Learning and Pattern Recognition for Stocks and Forex Part 3
Tutorial page: Basics
What's going on guys?! Welcome to part three of machine learning and pattern recognition for use with stock in forex trading, where we left off and we're just graphing up our data. There's a few ugly parts to the data so we're gonna fix those things, and then one more thing I'm going to show you is just another representation of that spread because, again, I feel guilty because I'm pretty sure we're gonna leave spread out of this entire series so just want to point out spread to you before we end up going down this really really long path that probably won't ever get back to spreads, so anyway let's go ahead and do some stuff with this plot and then we'll be on our way.
So the first thing that we did really only change we made to just the raw plot, right? I guess, we changed the figure size, and then we did the dates, but we haven't really done anything else. So there's a couple other things that we probably ought to do and just for displaying this kind of tick data, the first thing that we're going to do is once we've arranged this date. The next thing that I think we ought to do is kind of curve or angle the date so we can go:
for label in ax1.xaxis.get_ticklabels()
label.set_rotation(45) # 45 degrees
Next thing that we really want to do is fix member on the y-axis. How it was like, I don't know, the numbers right? it was doing like a +1.whatever we kind of want that to go away since that just looks ugly there's no reason before what we kind of want to see these decimals. So because it does that for us for a good reason, so most of the time you don't really care about really long decimals, but in this case this is one of those times where we do care. So what we're gonna do is do:
plt.gca().get_yaxis().get_major_formatter().set_useOffset(False) # turn that to false so it doesn't do that to us
So now let's just see where we are real quick and make sure we didn't do anything wrong or typo. It's highly likely that I type typos it's hard to type and talk. Sure enough I did: I put a comma right here so you'd dot if you were actually following me make sure you put that dot there and I get this stupid air I did that. Now let's try again see if we've got any other errors... Yeah, we didn't! okay so here's what we got right now obviously the dates kind of thing go out there, but again this is really just one day where the data, so doesn't matter too much. Plus if you see down in the bottom right where you cover you can see the time and the value so it's not a huge deal, but I'll show you guys how to fix that just in case you care. So anyway we close out of that that's looking good for now. Let me hit this gonna give me an error... okay so to make space for the bottom what we can do is use this subplots_adjust():
plt.subplots_adjust(bottom=.23)
Again, that's another thing that's covered pretty well in that other video. It's pretty much all of this stuff. If you want to know more about formatting charts, you can check that out. But again, that's not really the focus of this tutorial since I've already covered it, so I don't want to cover the same stuff especially for the people who have already watched those other videos.
So the last thing I really want to do is show you guys a representation of that spread and so if you did watch the other video, it'll be a lot like how we did volume, right? So what we're going to do is we're gonna say:
ax1_2 = ax1.twinx()
ax1_2.fill_between(date, 0, (ask-bid), facecolor='g', alpha=.3)
And what I wanna fill between? Date first then zero, that's like the minimum that it will fill under and then ask - bid. (Ask price) - (bid price) - otherwise known as the spread.
ax1_2.plot(date, (ask-bid))
ax1_2.set_ylim(0, 3 * ask.max())
Then we'll just give it a face color of green and an alpha of 0.3. And that should be it. We show a pretty decent looking chart at this point so save that and run it.
Obviously if you're not totally new to Python to run the function. You gotta type in you know graphRawFX() and enter.
You can actually see this down here is the spread size basically. You can see some cool stuff with that spread size. Anyway, just something I wanted to show you guys since we did have bid-ask tick data here that you can do with that data.
So anyway we're going to close out of this out. That's going to conclude the third video in the machine learning for Forex and stock trading.
In the next video we're going to start building up our pattern finder, so we're going to go through the text file and start looking for patterns.
As always thanks for watching and thanks for your support of subscriptions and until next.
NOTE: local graph is not the same as in the video: local version have no some kind of histogram effect for the spread.
This video has us beginning to build our comparison ability, which will be used in pattern recognition. This part could be done in a logarithmic fashion, but we're going to try to keep things as simple as possible!
Source: Percent Change: Machine Learning for Automated Trading in Forex and Stocks Part 4
Tutorial page: Percent Change
Hello everybody and welcome to part 4 of machine learning for Forex and stock trading analysis! Now that we've seen our data let's actually talk about our goals, what we want to do here. Generally with machine learning everything is going to boil down to actually machine classification. So with quant analysis gentlemen the first few things that you're taught are these quote-unquote "patterns": head shoulders teacup whatever else silly names that they've got... There's tons of these patterns, so what's a theory behind these patterns?
Well, the idea is that prices of stocks or forex ratios are a direct reflection of psychology of the people trading. So the traders, either people or computers (I guess you wouldn't want to call it totally "psychology" but maybe the variables that built up to make that pattern), so the people or computers they're making decisions based on a bunch of these variables and the theory is when the same variables present themselves again you'll get a similar pattern. So you'll get a repeat of actions that create that similar pattern and then the outcome as well is likely to be very similar. The further we move away from that pattern, the higher likelihood of similarity of the outcome changing, but you don't have to move too far away from the pattern, really, you just need to move far away enough for you to actually execute a trade and that's all you really need. And, really, with quant analysis, algorithmic trading or on automatic trading that really doesn't need to be too far out since the computer can actually execute the trade pretty quick faster than you will be able to. At least our initial goals are:
-
Create a machine learned batch of what will end up being quite possibly millions of algorithms and the results, which is going to be used to predict future outcomes compared to the outcomes in the past of these exact same algorithms. Now obviously as time goes on we can cut out some old algorithms if you don't want to use the same algorithm from years ago, or you might not want to or maybe you want to weight it differently. But as you're going to find out as we get through this, there's a whole bunch of options that we can do. So we're going to kind of put them on the table. We won't get too in-depth, otherwise, we would never make progress, but, you can imagine.
-
Actually test this basic theory. So the beauty of machine learning is this notion of what's called data snooping. Data snooping is basically like making new inferences after looking at your data, so with machine learning data snooping is actually built-in. On the other side, if you don't really look too in-depth into what machine learning is actually doing, you might actually accuse it of: "Well, that's just machine learning and that's no good", right? But what you're missing is that data snooping is not only built-in, but it's actually accounted for. It's really great.
So our whole system here is really built on the inference of pattern recognition, not the algorithms itself, so if patterns changed in new data, that's actually already built in and is done by programming, that's done before we've even seen the results. This allows researchers to actually get the best of both worlds, while avoiding some of the pitfalls of data snooping.
So what this is going to let us do is it allows backtesting to actually serve a really truthful and accurate purpose. If our machine learned live algorithm passes the backtest in every sense of the word: using historical data and only using historical patterns is it still accurate as we move forward?
If the answer to that is actually "yes", then it's highly likely to continue performing well in the future as well, because it's actually the machine learned patterns that are paying out, not the exact pattern as it were profitable at the time. So really it's confirming the hypothesis. We have an actual reason why we think this might work: we're going to put it in action and if it does confirm, that it actually confirms the hypothesis.
That's what we're really looking for, unlike finding like some sort of mathematical equation for no reason. You just kind of kept flipping around variables until you found one and backtesting it and: "Holy moley we got great results! This is going to make me bank!" No, that's unlikely.
What we're going to do is take a range of data in succession. To start, we keep it really simple and so simple that it literally will be stupid, but we're going to do it. We create a pattern with that data. The sense of the reason why I say it's stupid is we're going to use a range of 10. Don't forget we're using tick data, so a range of 10 in this tick data is really under most likely to be less than 10 seconds of a timeframe.
Most people aren't going to have bid-ask tick data, they're going to have more like bar data: open, high, low, close data and it might be for one minute open, high, low, close, something like that, but not everyone is going to have this bid-ask tick data, but if you pay for it, you can actually get that data stream, anyway, beside the point there bright chance be too short of a range, but luckily, something like this, same thing with percent similarity which we'll find out way later on, and even the time length, all of this stuff can be machine learned to find the best of everything at the time.
And again, it's not data snooping, it's just built in the machine, there's no new programming that will take effect, it will just continue and continuously not only find the best patterns, but it will find the best lengths of pattern to care about, how long of a timeframe do we care and how similar will we require these patterns.
Not in this video, otherwise we would literally not do anything in this video, probably a few more videos away we'll get it in a little bit more detail about why that matters and why we want to find out how close. Wouldn't we want like a 100% match of patterns and all this stuff? And, no, the answer really is quite firmly "no".
We're going to take this range of data in succession and create a pattern with it, and the way that we're going to do it is with percent change. We want to normalize the data as best as we can, so that we can use it everywhere, even if the price has changed that pattern. So if you just had a pattern of let's say $100, on $1, on $3, on $2 that pattern if you required it to be like that: when it matched the $10 and $10 and twenty cents or whatever that pattern once I just said, it wouldn't match even though it graphically it would be identical.
So we want to normalize that data. The preferred method properly normalize data is to do it logarithmically, but what we're going to do is to use percent changes to keep it as simple as possible. And the next thing to consider is how we're going to do this percent change now? The way that we're going to do it is a forward percent change from starting point. This means the longer that the pattern is, the more likely the end is to be less similar than the beginning, but the actual direction in movements of the pattern will be very similar. So this can be useful since some patterns might take more time to react to a movement than others and we want to build up, in my opinion, to be most accurate.
But what we actually want is for the end to predict the future, and so if you wanted the end to be more accurate you would do a reverse percent change. So from the last point, what is the percent change the point #9 to point #8, 7, 6 point, whatever. Or you could do a point to point percent change and really make some stuff pretty stringent. If you do point to point percent change you run the risk of that pattern doing some pretty wild, like it can be very different visually even though you might not think, so it can wind up going in a completely different direction. So I don't think we want to do that.
Now, anyway, like I said before, all this stuff can be changed there's already a lot of variables and trust me, when it comes to variables we're going to be very, very busy. Some of them, luckily, can be machine learned very easily, the other ones can be machine learned very difficult.
Forward starting point: this means that first we need to store a bunch of patterns in the percent change format. In reality and in our backtest, that will actually mimic this, your patterns can only obviously come from the past, so when we do backtest it we won't be able to be like: "Well this pattern from May, 1 looks a lot like this pattern on May 8th!" Hey, you can't do that! So then what we do is compare the current pattern to similar patterns in the past using this percent change, and, again, this can be done logarithmically, but it might be better that way, the goal here is to keep things as simple as possible. And then what we can do is if when we find similar patterns, we can look at what was the outcome of those similar patterns in the past.
So let's actually code something now. The first thing we need a code is a percent change function. We could do this by hand every time, but we're going to be doing a lot of percent change, so it would just make sense to go ahead and shorthand this for ourselves, so we'll want to do this.
So we're going to define percentChange() and in the parameters we want a start point and a current point, from what to what are we going to do percent change to:
def percentChange(startPoint, currentPoint):
return ((currentPoint - startPoint) / startPoint) * 100
Percent change is: ((new - the old) / the old) times 100. I see people do a different form of percent change and it really bothers me and there's good reason for it sometimes but not now.
The next thing that we want to do is actually program a function that is going to use percent change and just go through everything and make all these percent change patterns. That's what we're going to be doing in the next video so you're welcome for a percentage change and a bunch of talking! Anyway, hopefully that sounds interesting to you guys hope you guys are excited for the future videos.
As always, thanks for watching!
Welcome to part 4 of machine learning for forex and stock trading and analysis.
Now that we've seen our data, let's talk about our goals.
Generally, with machine learning, everything boils down to actually: Machine Classification.
With quant analysis, generally the first few things you are taught are "patterns" Head and shoulders, teacup, and whatever else.
So what is the theory behind these patterns? The idea is that the prices of stocks or various forex ratios are a direct reflection of the psychology of the people trading, ie: the traders (either people or computers) are making decisions, based on a bunch of variables. The theory is that, when those same variables present themselves again, we get a repeat of actions that creates a similar "pattern," then the outcome as well is likely to be similar, because the variables are almost the same.
So what we're going to do here is
-
Create a machine learned batch of what will end up being millions of patterns with their results, which can be used to predict future outcomes.
-
Test this.
You may have learned a few simple patterns, but everyone knows these. What if you could know every pattern in history? Pretty hard for you to remember them all, but not too hard for a computer.
Our entire system is really built on the inference of pattern recognition, so if patterns change due to new data, that's really built in and is done by programming that was done before results.
This allows backtesting to actually serve a very truthful and accurate purpose. If a machine learned live algo passes the back test, it is highly likely to continue performing well in the future, not because it passed a back test, but because our hypothesis and entire model passed the backtest... unlike finding the best algo at the time and backtesting for great results.
With that, what we will do is take a range of data in succession, and create a pattern with it. How we're going to do this is going to be with % change.
We want to have the data normalized as best we can, so it can be used no matter what the price was. We're just going to use a succession of % change for it.
To start, we'll do forward percent change, from starting point. This means, the longer the pattern, the more likely the END is to be less similar, but the actual direction of the pattern will be more similar. This can be useful, since some patterns might take more time to react than others, and we want the build up to be most accurate, but we might actually prefer the end to be more accurate in the future, so we could do reverse percent change. We can also do a point-to-point percent change as well. Trust me, when it comes to variables, we're going to be very busy.
Now what that means is first we just need to store a bunch of patterns, in their percent change format.
Then, what we'll do to compare patterns is how similar the % changes are.
def percentChange(startPoint,currentPoint):
return ((currentPoint-startPoint)/startPoint)*100.00
This video has us beginning to build our comparison ability, which will be used in pattern recognition. This part could be done in a logarithmic fashion, but we're going to try to keep things as simple as possible!
Source: Finding Patterns: Machine Learning for Automated Trading in Forex and Stocks Part 5
Tutorial page: Finding Patterns
Hello and welcome to part 5 of machine learning for the use of algorithmic trading, where we left off from a this percent change function. We haven't actually tested this percent change function. One of the main issues with this is going to be that it's not going to be willing to work with whole numbers and give us a decent output so for example let me just show you:
percentChange()
...talking about Python's 2.7 integer division, import division or add decimal point...
... fixing percentChange() function with float and adding decimal point...
Now the next thing that we want to do is actually make this pattern finder so what we're gonna call it is actually a patternFinder() I know you can see that name coming I try to choose really weird names.
Now the first thing that we need to do is where are we going to look for these patterns. Well probably the best place to look will be in the file so let's just go ahead and: put date, bid, ask = ... to global variables.
Also keep in mind now that we've moved this if we decided to manipulate these variables at all down here we would need to global <variable>. Just keep it in mind. As long as you don't manipulate the variables themselves it'll be fun.
So, patternFinder(). First thing we want to do is let's simplify this, because as you probably starting to see weird. As we go on, there's gonna be a lot of variables here. And as long as we continue on with bid-ask kind of prices, it's going to get really really messy and we might not ever actually finish this series. So the best thing for us to do is to just make it a simple average of the average line. To do that we do: avgLine = (bid+ask) / 2.
This is just going to average bid and ask, so to give us perfectly the middle spot of between bid and ask. Now you can see we've thrown away spread and why I just wanted to point it out to you guys initially, because we're not going to be touching spread for quite a while if at all.
Next, we're going to look for patterns in here and then, as we look for all these patterns, the next thing we want to do is: for every pattern we find we want to know what the outcome of that pattern is.
So with that we're gonna to say: x = len(avgLine). After we find that pattern, we're gonna look 20 to 30 patterns into the future, we're going to look for the range of between 20 and 30 and we're gonna average the outcome, like between 20 and 30 what's the average price. So from there we'll get the average outcome between 20 and 30 and this is the average number in the future that we can kind of hope to achieve.
If it only hits like this number for split second, we won't want to call that the outcome. So, instead, we're gonna take a range of numbers, average them and say: "okay, this is the outcome". Because of that, we're gonna look also 30 digits in the future and we're gonna use x as like a counter so I guess before I do what I was going to do I'll show you why.
Next thing I want to do is: y is going to be the starting points that we use. So y=11. Even though I really think it ought to be 10, I will just call it 11 just to be safe and just ignore the first point. Next: while y < x:. The reason why we're going to add a while loop is we're going to make it into a counter, every pattern will do plus one and log that pattern, while y is greater than x. Now you can understand why: because we're going to make this into a counter, eventually, we're gonna hit the length of average line and then when we go to look for what happened in the future, it's not going to be available. That's why we need to throw in a minus 30 here: x = len(avgLine) - 30.
Make sure you do that: x equals the length of average line minus 30, so it will stop at the minus thirtieth x basically. That way we can still look into the future.
In the loop we want to say: p1 = percentChange(avgLine[y-10], avgLine[y-9]). Starting point is avgLine[y-10], end point is avgLine[y-9].
So for every point (along this way like p1 will just be literally point 1 in this pattern), so for every point along the way the starting point will remain the same (as I said we could change this but for now we will not) and so this y-10 will always be the same. But, we're gonna change the ending part. The easiest way to do this is, since we have 10 points and a lot of this will be the same, we'll just paste. ...copy and paste p1, editing p index and end point in percentChange()... Now so that's point 1, 2, 3 etc.
The next thing we want to do is we want to say what is the outcome range.
And that's going to be average line and the range of outcomes is y+20 all the way to y+30 so basically the the 10 numbers between, whatever y is at the time, plus 20 all the way to y plus 30, so this produces an array of 10 points: outcomeRange = avgLine[y + 20:y + 30]
Then what we want to do is what's our currentPoint = averageLine[y]. Not really need this in the future but we'll use that for now and just for printing out function.
Now we want to average the outcome of this, so for now we'll just print that out, an we're going to use lambda to do this. If you don't quite follow I do have a tutorial on lambda. Otherwise, just copy what I do, it's just a really quick way for us to average:
print(reduce(lambda x, y: x + y, outcomeRange) / len(outcomeRange))
It's basically adds everything together so for every x and y it's just gonna add them together within outcomeRange and then divide it by the length of the outcomeRange, otherwise known as average.
Next, print currentPoint, little spacer and then print p1, p2, p3, p4, p5, p6, p7, p8, p9, and p10. And finally do we have sleep? No. So go up to the top and import time. If you're gonna copy me: I'm just gonna make something that pauses with sleep, so we'll do time.sleep(whatever).
This is basically the storage of one pattern. If we leave this like this y will always be less than x and we will just get a bunch of the same pattern. So what we need to do at the end of this function, and I shall put it before the sleep, just put y += 1. This just is a shorthand way to add one to the variable y.
Let's go ahead and save this and let's run patternFinder() and see if everything is worked. It should take a second to load on start because it's loading up GBPUSD1d.txt into your RAM and creating these arrays. So that's being loaded into your memory, so every time you load it's going to take some time, and that's why we global this variable because otherwise if you put it like, maybe, down here, it would be doing that a lot.
Anyway, more on that later, excites another thing that we'll run into in a little bit, so we want to run is patternFinder(), enter. And sure enough, basically, what we've done is
we've printed the outcome first so the outcome you can actually see the outcome is slightly higher than the current point that we're on. Even though this is just really it's a pattern. In theory this pattern is a pattern of profit for in the tone of... not even a full pip, like a half a pip.
Anyway we can see here: minus a tiny percent, minus a tiny percent, minus, minus, minus... might actually a lot of minus percentage. But anyway in the future we can see that after all of these little minus percentage and if you plot this up, it would make a pattern of some sort. We can see in the future it does produce a half a pip, or a little bit less, but basically you have a pip and so a little bit of money, but, anyway that's one pattern.
Now what we're gonna want to do is begin a whole storage of all of these patterns and then we can start to compare against patterns. Anyway, that's the storage of a single pattern, and in the next video we'll continue building of this.
As always thanks for watching thanks for all the support and subscriptions and until next time!
Lecture 06. Pattern Finding and Storing: Machine Learning for Algorithmic Trading in Forex and Stocks Part 6
In this video, we are finding and storing patterns to be later used in the pattern recognition.
Source: Pattern Finding and Storing: Machine Learning for Algorithmic Trading in Forex and Stocks Part 6
Tutorial page: Storing Patterns
Hello and welcome to these sixth part in the tutorial series of machine learning applied to stocks and Forex! Where we left off? We were making this patternFinder() basically and we printed it out. We're not actually saving the pattern or anything, so now what we actually want to do is begin saving this pattern. So what we want to do is: come up here and create an empty global array, actually 2 empty global arrays. First one we want is patternAr = [] for pattern array. That'll be empty for now. What this is going to do is as we run patternFinder(), every pattern will get stored into the pattern array.
Subsequently the next thing we're gonna do is create a performance array performanceAr = [] where we store the outcome which was an average of in the future in the next twenty to thirty points what was the average price at the time, so we're calling that the outcome, so we're also going to store that to that performance array and in these two arrays each value in the array will have the same index number as its partner.
Now you might think well why aren't we making a dictionary out of this? And it would have been nice to make a dictionary or you can make like a multi-dimensional array or something otherwise known as a dictionary, usually... But the issue with the dictionary is what we really needed was the key to be the pattern array, because what we're gonna do is: when we find a pattern, we find a similar pattern and then we wanted to compare that pattern and see what the outcomes were. But the issue was you can't have an array as the key. If you have no idea what a dictionary is, don't worry about it, I guess, but for anybody that does know what a dictionary is probably wondering why we're not doing that. So, you can have an array as the key to the dictionary, it would have to be the performance value, but you can't, this is the kicker! You can't have an identical key in the dictionary. You can have identical values, you could have different keys equal the same thing but you can't have identical keys. So you stick, when you go to define that key you would overwrite the most like the other key, and the problem with this is you would be overriding possibly better results like a more accurate pattern might end up getting more overwritten. Anyway it would be a huge mistake to do it, so we're not going to do that, we're just going to make two arrays.
So change the name patternFinder() to patternStorage(), because actually soon we'll actually make a pattern finder and that'll make more sense to call it pattern finder. That's what it doing, it's storing patterns.
Usually in something like machine learning type of script or a script that's doing a lot of calculations you want to have processing time: patStartTime = time.time(), so that will store whatever time it is currently and then, at the very end of this script: patEndTime = time.time() And then at the end we'll subtract the two. Thus you can find out how long took the storage of patterns, so this way you can start to find inefficiencies in your script.
...then, create avgOutcome in try / except block...
Reason why we do this is with doing a percent change of a percent change and so this can give us especially... well I won't get into the maths, but well you can wind up with a negative infinity percent change. So in case of exceptions, just in case, we've type out something and then also if this does happen, we'll just say the avgOutcome=0.
Remember how this basically the average outcome created: a number with the digit of that outcome was. That's no good, we need it to actually be a percent change as well. Again, we need to normalize everything. Probably this is the most accurate representation of using percent change or a logarithm: futureOutcome = percentChange(currentPoint, avgOutcome). Keep in mind the average outcome can be zero, so that gives us a possibility of a division by zero and also all kinds of interesting stuff.
...change the percentChange() to correctly calculate the cases from negative startPoint to positive startPoint. Examples: percentChange(-10, 20)=300, percentChange(10, -20)=-300...
You need those absolute value bars (abs() in this case) but it's basically what absolute value bars does and written that. We need that there as well because we will have percentChange() using a negative numbers when we compare... not only future outcome can have it but then also when we're start comparing formula or comparing patterns we're going to see in a lot.
We need to append the pattern to this patternAr, also we need something that's like pattern. So while y < x: we start with an empty pattern, and then do pattern.append() and we need to start appending all this pattern, obviously need to append it in the order. Now we've got a pattern appended one to ten, so it made an array, so this pattern is now an array of percent changes and now, we need to do patternAr.append(pattern) Subsequently, performanceAr.append(futureOutcome).
Just to make sure we've done everything these lengths ought to be the same. so we'll print the length of patternAr, print the length of performanceAr and then also we want to print the time it took to store these patterns: print('Pattern storage took:', patEndTime - patStartTime, 'seconds'). Save that and run this and make sure we are indeed storing patterns and it will only store all the patterns found in one day, but, I believe, that was already like... I forget how long that this file is, but it's a pretty long file, so should have quite a few patterns.
So we found 61971 patterns, 61971 outcomes to those patterns and the storage of all of those patterns, the time it took to run through this entire file took 2.12 seconds so if you were to use fresh data and run through the month, that would be 30 days we take about a minute, in theory, to do it all, probably, a little bit less, we can talk about that later.
Sure enough looks like we've stored all of these patterns. We've done it successfully, so our pattern storage works. Actually we could test this and say: patternAr[5], and see pattern of percent change in array, 5 and then our performanceAr[5] print the outcome of that array and it's a positive.
Conclude this video on the pattern storage function here. In the next video what we're going to do is creating our pattern recognition. We're going to: store all the patterns, find the most recent pattern and then find previous patterns that are very similar to the current pattern. I'm going to make another function, and it's going to be our actual pattern recognition function. Hopefully that sounds interesting to you guys.
As always, thanks for watching, thanks for the support, the subscriptions and until next!
-
Question: I have a question that I must have missed watching the videos. On line outcomeRange = avgLine[y+20:y+30], why did you choose 20 and 30. Our first pattern is avgline[1:10], and the performance or avgOutcome is the percent change of our currentPoint or avgLine[10] to the average of avgLine[30:40]. Why do we compare so far into the future? Or why wouldnt we check for percentage change of the next 10 elements?
- Answers: You're free to choose what you want. The reason I chose it: It's y, which is the last point, plus 20 points out, to 30 points out. Then we average this to find the average "outcome" price. The idea to compare it to the average of where price ended up after our pattern, in a time frame where a trade could plausibly be executed. It's possible somewhere along the lines I chose bad numbers. I literally programmed this series as I went, which is discussed in the end a bit more in detail. Feel free to change things as you see fit, there are a lot of variables to play with in this series, and I just arbitrarily picked values. Hope that helps.
-
Question: So length of the pattern and how far in the future can be adjusted to find the best possible combination. Thanks a lot, it is a great tutorial.
- Answer: To name a few, yep. In the end quite a few of the variables are discussed. Glad you are enjoying the tutorial! Was a lot of fun making it and worked out better than expected.
- Authors' CPU is i7 3930k.
-
Question: Is the stored patterns same as features in ML jargon?
- Answer: The stored patterns are more like featuresets, and each % change is a feature.
In this video, we are are locating the latest pattern, in order to compare it to the previous ones for pattern recognition.
Source: Current Pattern: Machine Learning for Algorithmic Trading in Forex and Stocks
Tutorial page: Current Pattern
Hello and welcome to these seventh video in the tutorial series of machine learning for use with stocks and Forex algo trading! We were storing a whole bunch of patterns into an array and basically into memory and now we actually begin the pattern recognition part of this, basically, what is our current pattern that we have right now.
Make another function def patternRecognition(). Here we're going to make an empty array patForRec = [], which basically stands for "pattern for recognition". What is the pattern in question?. For this, make a bunch of variables and it's going to be cp for current pattern, cp1 = percentChange(avgLine[-11], avgLine[-10]) for current pattern for 1, basically. Again we use our percent change calculation, which this rely on the average line. To determine our current position within the pattern, we can use negative indexing. By using -1, we refer to the last element in the array. Similarly, if we used -11, it would point to the tenth-to-last element. So, our starting point is -11, and the current point is -10. For others cps, we copy and change that string like: cp2 = percentChange(avgLine[-11], avgLine[-9]), etc. The percent change will be calculated from a specific point, following a kind of backward format here. Starting from this point -11, the values are as follows: 1, 2, 3, 4, 5, 6, 7, and so on. The percent change will be determined using the same format as our pattern storage. Now, store this so patForRec.append(cp1) and copy-paste with changes. Better way to do this with a for loop or a while loop but again we're trying to keep this pretty simple.
Just to make sure we did everything right do. print(patForRec). Save that and run this pattern recognition function. avgLine is not defined. Move avgLine from patternStorage() to global.
This is our current pattern in question. In the next video, our focus will be on comparing this pattern with previous ones stored in our memory. Stay tuned for that!
As always thanks for watching!
- sentdex comment: Personally, I am more of a fundamental investor myself. I just enjoy programming and machine learning. This whole series here doesn't use sentiment analysis at all. For my website, that is pure sentiment, and that is my main focus in business. As for books, I don't know. Quant traders are an elusive bunch. The ones that make money don't talk much about how they do it. The way I personally learn is to be like a sponge and absorb all i can, mostly from online documents. Best wishes!
-
Question: why did we subtracted 30? in this code
x = len(avgLine)-30-
Answer: For a given current point
y, he want to use the pattern of 10 previous points (fromy-9toy) to predict the future outcomes (pointy+20toy+30). He usex = len(avgLine)-30so that the while loop does not go over the total length of the data.
-
Answer: For a given current point
-
Question: why we have taken y=11 is it fixed?
- Answer: Since he consider the pattern of 10 previous points of a given current point, he picked the starting y=11 so that it has exactly 10 previous points
Lecture 08. Predicting outcomes with Pattern Recognition: Machine Learning for Algorithmic Trading p. 8
Using previous pattern outcomes to help us begin to predict future outcomes.
Source: Predicting outcomes with Pattern Recognition: Machine Learning for Algorithmic Trading p. 8
Tutorial page: Predicting outcomes
Hello and welcome to... NO SUBTITLES
Totally dedicated to compare patterns. All the good things are simple: for the pattern of fixed length, we do percentChange() for every nth element and get the abs() of it, so no matter we compare currentPattern vs knownPattern or vice versa. Then, do the avg for all the points similarity and that's it.
Source: Pattern Recognition: Machine Learning for Algorithmic Trading Part 9
Tutorial page: More predicting
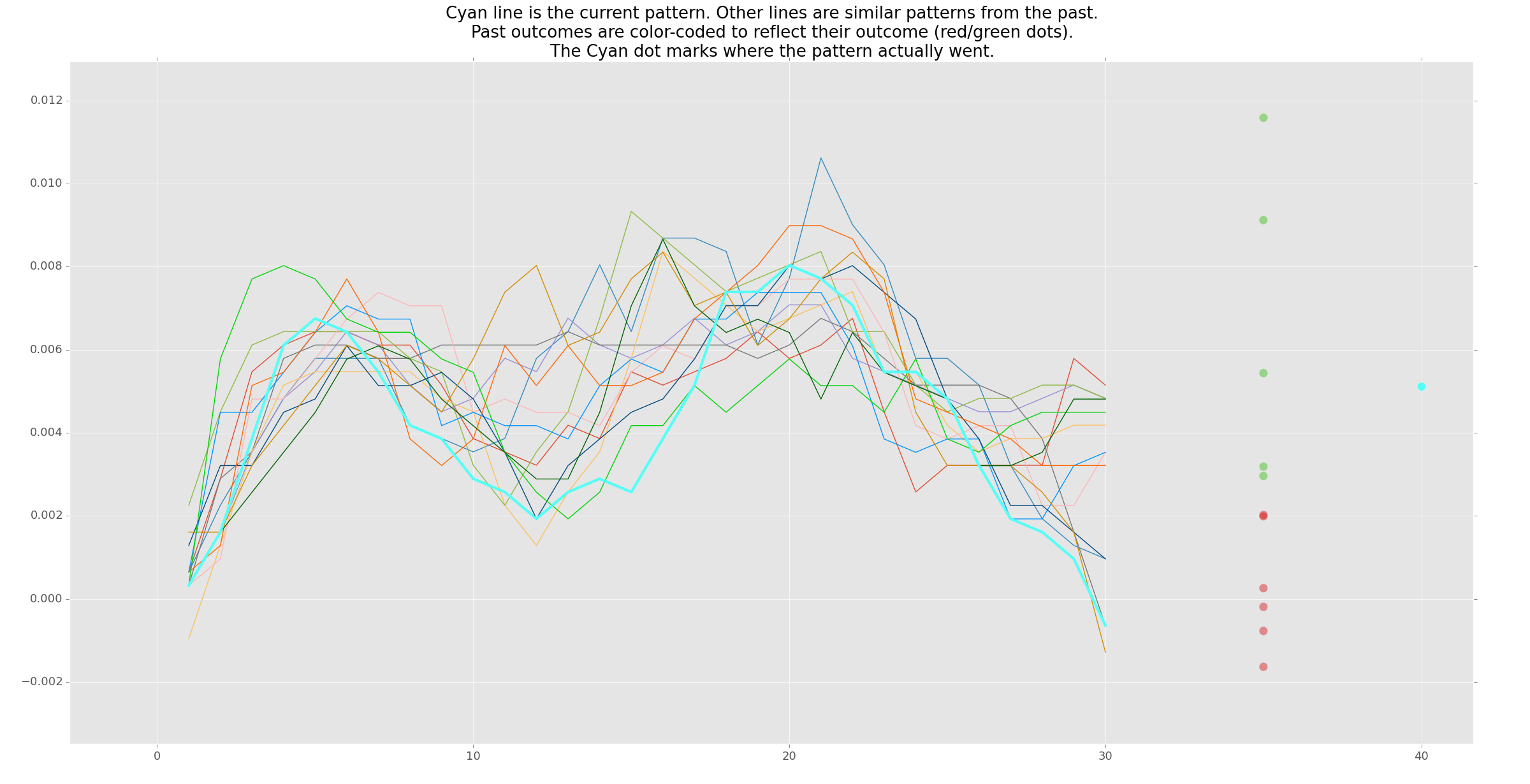
Welcome to the 9th edition of our machine learning course on pattern recognition for algorithmic trading in stocks and Forex. Upon analyzing the most recent pattern, we have determined that its the most likely outcome is a drop. As we look through the patterns we could tell that they were at least somewhat similar just by looking at the numbers. By visually examining the patterns, we can observe that they are somewhat similar, which is evident from the numerical data.
First, obviously, we're going to plot them up with matplotlib here. We have 10 digits basically (pattern consists of 10 points), so x axis or x variable will always be just 1..10: xp = [1,2,3,4,5,6,7,8,9,10] (do it right after we print out the predicted outcome). Next thing we want to have is a figure and so we'll just say: fig=plt.figure(). This is just kind of makes up a figure for matplotlib to plot upon. Next, plot the pattern given for recognition: plt.plot(xp, patForRec). Next, plot the matched pattern: plt.plot(xp, eachPattern). That's it for plotting basically, the only thing we need to do is bring it up with plt.show(). Save that and run this.
We can see very similar lines, close the chart out, this it brings up another chart and this will bring up to the point I mentioned earlier how the beginning is more likely to be more similar than the end. On the chart we can see the result of these lines is slightly different. This line could in theory come back up and further match this but it hasn't more just comparing this pattern. So anyways that one wasn't too sexy, but the next one chart show patterns very close, especially on the end. And continue keeping track of your outcomes and patterns. Now you can display them visually. There's none matched pattertns with above or equal 80% similarity, we can see where the threshold was somewhere between 70 and 80.
So that's going to conclude the ninth video. In the next and tenth video what we're going to be doing is actually lengthening this pattern. Obviously really like the ten plots is just a bit too short for a pattern. Obviously it depends on your timeframe, our timeframe is very, very zoomed in it's a high granularity and so it might make sense to look at longer term patterns or at least a bit longer of a pattern. Instead of 10 points to consider let's consider 30 points and do the same thing that we've done and plot that up. Example of one with 30 points: as you can see it's a similar line a lot more variables in the line and then there's an end divergence here which again is fairly likely using the method that we're doing.
As always, thanks for watching, thanks for all the support, the subscriptions and until next!
-
Hi nice videos :) quick Q when you plot the graphs we see the start is more similar than the ends? (you mention divergence etc) I see why your program does it this way. Would it not be better to look up and compare your patterns in reverse ? so the endings (points on right) are the most similar ? I think the last points are more relevant than the older ones (on left) NO!! ? please explain why you do it this way.
-
Question: is the y-axis pips and the x-axis the amount of points we are looking at? also, does the graph show us that once a pattern is found, GBPUSD usually turns down (declines)
- Answer: The x axis is the plot # in the pattern, the y axis marks % change, not pips.
Lecture 10. Increasing Pattern Complexity: Machine Learning for Algorithmic Trading in Forex and Stocks
In this tutorial, we increase the pattern complexity, ie: increase the pattern length for pattern recognition.
Source: Increasing Pattern Complexity: Machine Learning for Algorithmic Trading in Forex and Stocks
Tutorial page: Increasing pattern complexity
Hello and welcome to the 10th machine learning for use of Forex and stock algo trading automated trading or just plain analysis or just learning to do machine learning! We were plotting up our similar patterns on a matplotlib so we can see them visually, and we said that we wanted to extend our pattern lengths that we're going to look for, and we're going to be looking for a bunch of patterns, not just on the end patterns, eventually, we do need to backtest this.
First, change a couple things here in our percentChange() of formula. It's possible to arrive at a zero percent change, then to calculate the percent change from zero to a point will be problematic for us if that occurs, as we not only expand the length of our pattern, but also we're going to run through all of the patterns. The chances of us hitting something like that is actually pretty likely.
Normally we don't really care if the percentageChange() was zero. What we do care is when we do a percentageChange() of a percentageChange() that yielded a zero that's going to be very hurtful to us so we never want to throw with zero percent change we need something. We're just going to return 0.0000000001, basically zero but we can actually work with this number. So let us solve a few of our issues. Obviously this is not a perfect math but that is the best way to handle a negative infinity when the percentage change of a percentage change of zero comes into question.
...fixing patternStorage() to work with 30 points instead of 10 points...
...fixing currentPattern() to work with 30 points instead of 10 points...
...fixing patternRecognition() to work with 30 points instead of 10 points...
Since we've made the pattern much longer how sim of 70 across one pattern is basically probably not going to happen, very unlikely, that to hit that let's just drop this to 40 just for ease of actually finding a pattern before we start building the backtest, so 40.
Let's go ahead and save this and run and see what the heck we get. Probably you see that our old pattern is right here as well just in case you don't notice.
Conclude this video. In the next video we're going to begin building up our actual backtesting, or running through old data. We were only comparing that most recent plot as being as if the last plot in our data set. However, if we want to back test data, we can do that as well starting at the first plot and then running through each plot as if we were comparing or running through future data. So as we continue getting more plots we're comparing to only the previous plots not the future plots. {maybe plot==point}
So that's what we're going to do in the next videos is actually run through the dataset as if it was reality and start building, saving up that each new pattern it finds, and seeing how long it takes to do this (and you'll see that initially it's very quick), and as we continue getting more and more data and more and more patterns stored the memory, that's when we start actually being taxed or RAM starts to get taxed as that array grows. But anyway, that's what we're gonna start doing the next video is beginning to build the back tester. And really it's quite call it backtester, we're testing against old data, but it's actually better than a backtester. It's really like backtesting the forward test or something I don't know. Anyway that's what we're going to be doing in the next video.
As always, thanks for watching, thanks for the support, for the subscriptions and until next time!
-
Question: Hi and thanks for the tutorial series, great work! Based on the code I've seen so far I assume this would be the correct way to define x and outcome_range: #assume pattern_size to be 10 or 30 min_peek = 20 x = len(avg_line) - (min_peek + pattern_size) outcome_range = avg_line[y + min_peek:y + min_peek + pattern_size] Would this be correct?
-
Question: I'd like to point out that since you are not changing the outcome range, the value of x should remain the same. So, it should still be "x = len(avgLine)-30".
-
Question: Hmmmm i dunno about returning that percentChange as
0.000000001. I think It would be more accurate to just change the startPoint to the closest to 0 value before dividing by it, i'm trying sth like this: stPoint = startPoint if startPoint != 0 else 0.00000000000000000001. Cause with this percentChange formula of ours, the currentPoint can be 0, and it would yield more accurate results, if it would stay 0. What you guyz think? -
Question Hmmm and i think the simularity is not done entirely correctly. If we think about it conceptually 100% - would mean that the numbers are completely the same, where 0% would mean that the numbers are completely different. Now doing 100.00 - {the percentChange} is inaccurate similarity check, cause the percentChange might be more than 100% so then the similarity would be a minus, which conceptually means wat? Its SUPER different? :D . I think the more proper way would be: instead of substracting just from a hundred we should substract from the percentChange of the lowest point and the highest point(in the patternArray , and maybe in the patternArray and the current array?), cause conceptually in the array those would be the actually completely different values. And then in the if 'howSim > ' we would not be checking by a constant number, but by the actual percentage of the completely different value percentChange(the min max points percentChange) like
howSim > minMaxPercChange*0.7. Wat you guyz think? -
Question yikes! p19,p20,p21,p22..... you do a lot with sliding windows over sequences so far...perhaps having a static "window_size" var somewhere and relying on something like:
def window(seq, n=2): """Returns a sliding window (of width n) over data from the iterable. s -> (s0,s1,...s[n-1]), (s1,s2,...,sn), ... """ it = iter(seq) result = tuple(islice(it, n)) if len(result) == n: yield result for elem in it: result = result[1:] + (elem,) yield resultto yield sliding windows of the iterable. then building/storing/analyzing/comparing your patterns with something like:
for i, (w, avg) in enumerate(zip(window(self.avg_line, n=self.window_size), self.avg_line)): # XXXEither way, awesome series! I'm having a lot of fun going through it.
Lecture 11. Pattern Recognition and Outcome: Machine Learning for Algorithmic Trading in Forex and Stocks
Here, we are beginning to compile the past historical patterns that we are comparing to, and taking their eventual outcome for use in future predictions.
Source: Pattern Recognition and Outcome: Machine Learning for Algorithmic Trading in Forex and Stocks
Tutorial page: More on Patterns
Hello and welcome to the 11th machine learning pattern recognition for use with algorithmic automatic trading and with Stocks and Forex! We were just basically looking at the most recent pattern in our data and looking at all the previous patterns in the data and showing the similarity and predicting the outcome. Now that we've done this right, clearly at least visually looking at our pattern recognition, it works pretty well, I mean it's not the best but it works. So we know the pattern recognition works, so we're done. Now we want to know or at least begin to figure out does this even matter. Now we need to go back in time and act as if we were running this in reality. The way that we're going to do this and really recognize new patterns and then see if that actually works.
...cut global patern variables and go down of the script and paste them here...
Basically we want to run through this data as if it was new data so we don't want to load all of the data at the same time. Each time we want to add one plot to the data and then run through and be like: "ok did we know any similar patterns to this current most recent quote-unquote pattern" and go from there. We do this with while loop. Then couple of things that we need to do: dataLength = int(bid.shape[0]) - we need to know where should
the while loop stop. The way we can do this is with bid.shape[0] (so don't forget bid is just part of this numpy array that's defined earlier), because you can not do len(numpy_array). It returns a finicky funky number and convert it back to integer.
Next, where do we want to start. First of all if you started at point number one, there would be no previous data and no way to make a pattern on that data. So since we start at 30 really we must start at 30, but we're probably not going to find it well, we won't find any similar parents because won't have anything to consider. So say toWhat = 100: to what point from the begining we are going to consider.
we'll make a while loop here: while toWhat < dataLength: and basically run the whole program in loop. Create empty arrays inside loop: patternAr = [], performanceAr = [], patForRec = []. Obviously it makes them empty right now but then it starts storing the patterns. Each time we add one data point it clears the patterns and redoes them with patternStorage(); currentPattern(), patternRecogntion().
Efficiency wise bad idea that's going to be very hard on our processing, especially as data length gets longer. You can work around that. That can be fixed very easily. But for the simplicity, and also I don't mean to spoofing everybody this epic machine learning application, either. I'm just trying to teach you machine learning. I'm just pointing that out as well that is going to be a problem area as you start to expand and learn more patterns, but it doesn't have to be a problem, so keep that in mind.
Add toWhat += 1 to make loop not to run infinitely. If it finds any similarities (we have howSim>=40), if anything is found it will plot it up.
Next, make this application stoppable otherwise it will never stop and just continue running through: moveOn = input('press ENTER to continue...'). Save that and let's run.
Just literally hit and hold enter until we find a pattern. It might take a little bit to find its first pattern. Found a pattern similar plots it up for us. Close out of this hit enter again wait till we find another pattern. Sometimes (especially as you get deeper) obviously a very similar pattern plus one point is going to be fairly similar, so once you find a similar one, chances to find a bunch of them.
Now that brings up a point is it brought up a bunch of similar patterns for that exact one pattern. Why we plot them on a different chart? Makes kind of nonsense, so in the next video we show, how to plot them all up on the exact same graph so we can view it all, all the same charts visually.
That way as we build this backtesting we can see visually how it is, and then we can take it one step further, and plot that. Don't forget we have a predicted outcome a percent change so we can plot that percent change. As you can see like here, I found it pretty good positive outcome for that pattern. So with this pattern that we found the predicted outcome is positive. We literally plot those predicted outcomes as well. Since we do know what the future outcome was both on those patterns and also in reality, we can plot that and then we can find out. We can go to the next bit of data and not really the next range of data and we can find out: were we wrong or were we right.
So that's what we're going to continue working towards and getting closer and closer to finding out whether or not this is even of any use at all. But no matter. What you've actually learned is pattern recognition. As we continue we'll be able to find out how useful this is, and then also we're going to start getting pretty deep into some questions of variables and stuff to look forward to.
As always, thanks for watching thank you for your support, subscriptions and until next time!
From YouTube comments: this seems more like a pattern fitting method rather then machine learning.
Lecture 12. Displaying all Patterns Recognized: Machine Learning for Algorithmic Trading in Forex and Stocks
In this video, you are shown how to display all of the patterns at the same time, to make comparing visually easier. Plus it makes for pretty pictures...for all you graph and data lovers out there.
Source: Displaying all Patterns Recognized: Machine Learning for Algorithmic Trading in Forex and Stocks
Tutorial page: Displaying all patterns
Hello everybody and welcome to the 12th machine learning and pattern recognition for stocks and forex trading. We were generating a similar pattern on the chart and now what I would like to do is kind of mesh them all together. If it had maybe five similar patterns, we would have to run cycle through five charts. Let's go ahead and display it all on the exact same chart.
First thing in patternRecognition(): toWhat=37000, that should give us a good amount of data to start with. Next thing: howSim >= 70 and set flag patFound = 1, then comment out printing, the set patFound = 0 flag on top of the function before loop as by default there is no pattern found. Then plotPatAr = [] to store patterns to plot and then comment out old plotting, we were actually just plotting it every time, instead, let's just append this to pattern array, that will plot all at the same time once we have all of them together. If it did find a pattern, we plotPatAr.append(eachPattern): we want to go ahead and append that pattern. Then, do if patFound == 1: inside the patternRecognition() but outside the loop, and then let's remake the plotting stuff.
First, fig = plt.figure(figsize=(10,6)) and then iin for loop, plot all the patterns on the same plot, then after loop, plot the original pattern. Save that, run it and wait for it to store the data to the memory.
Really interesting then since we got so many lines here, now as you can see they kind of follow the similar like almost like at the bottom. There's a few that kind of branch off, but you can at least see that they a fair close each.
But now the next question: change howSim from 70 to 75: howSim >= 75
So you recall the first one, here's the second one. Now, that we've required not 70 but 75 percent similarity, so we have quite a few less lines than we had before. Keep in mind as you just barely wiggle that percentage there, you have drastic changes in similar patterns found, which can really go both ways as far as how much that helps or hurts you. But we'll be talking about that in a little bit, so, anyways, that's going to conclude a video 12 and just displaying all of the similar patterns on the same chart that we're running through the one at a time kind of stuff and then pretty soon we'll be running this into displaying not only this but the actual outcomes that truly did happen and then eventually back testing everything. So, anyway, that's going to conclude part 12.
As always, thanks for watching, thanks for your support, your subscriptions, until next time!
Lecture 13. Variables in Pattern Recognition: Machine Learning for Algorithmic Trading in Forex and Stocks p. 13
This video discusses the already many variables that need to be considered in our pattern recognition and how we use it.
Source: Variables in Pattern Recognition: Machine Learning for Algorithmic Trading in Forex and Stocks p. 13
Tutorial page: Variables in patterns
All righty everybody! Time to gather our thoughts and plant our feet. So far we've only done a very few basic things here, so it might seem like we've only just barely left the beach. But the reality is, if we turn around, we realize we're actually in very deep waters already, and we are very far from the beach. Let's consider the current situation.
We actually already have a lot of variables and these are going to need to be accounted for. We not only have explicit variables, we actually have these implicit ones as well. Our explicit variables are: a percent change as pattern recognition, so, how are we actually recognizing patterns, what we've used percent change. This could be obviously other things, we could use a logarithm to do something like this, and there's a whole lot of other things that we could do to recognize patterns, we've just happened to have chosen percent change for its simplicity.
Number two. To dive deeper into that percent change we've done start point to end point percent change, as compared to point by point or end to start percent change. Point by point could possibly give us look different looking patterns but the lines themselves would be closer together in theory, and then an end to beginning percent change would give us kind of the opposite of what we have here. If you look here we've got very close starting points, but as we get to the very end, we have very wide, I mean it's almost probably three times as variable as the beginning. If we were to reverse this, in theory it would be reversed, and therefore the end of the pattern would be more similar and it could be argued that it was more likely for the end to continue, to be more predictive or accurate in its prediction than in this format. But at least in my opinion, theoretically, I would argue that, really, they're the same pattern. The only difference is this one has been reacting quicker, right? So I don't really think it makes a huge difference, but, anyway, it is something on the table.
Number three. We're using a fix pattern length of 30 pieces of data. We could do 31, we can do 20, we could do 30,000, we could do any number, and probably a good number would be anything between ten and a thousand, since we are doing tick data here. So keep that in mind: pattern length.
Next, we're using a fixed value, or weight, of these patterns, no matter how old or fresh these patterns are. If we're getting this pattern, we're comparing it to a pattern that we actually found. I mean in this case, we are only using one day's worth of data. But in most cases, you would probably be looking at years worth of data, and you would want to be comparing your current data, or your current pattern, of years of patterns. But would you value a pattern from two years ago the same as you would value a pattern from like a week ago? Probably not, but maybe. But it is something to put on the table and right now we're validating them exactly the same.
Five. We are looking 20 to 30 points in the future to decide on the outcome. We're just averaging the outcome from 20 to 30 points in the future. Basically enough time to have executed a trade and held it for a few seconds and then maybe sold that trade. So, is this 20 to 30 points in the future truthful? Should we make it a wider range? Should we make it further in the future, shorter in the future? All those things could be switched up.
The next thing we have is similarity required for the patterns to be a quote unquote match. As I showed you, you have a huge difference between 70% accuracy required and 75% accurate accuracy required. Number six is quite possibly one of the worst variables to have, because we could require not only 71 72 73, we could require 71.123456789... You could have a million decimals, you could have a trillion decimals, so in this sense our number six you can say an infinite number of possibilities for the number 6. So that one's the hardest one but luckily there is an answer for machine learning.
Moving on we have an implicit variable that I haven't really talked about too much yet, but that variable is opportunity versus accuracy.
Usually in machine learning to typically find the best scenario that we can, especially in the case where we might have literally an infinite number of scenarios, it's much like how a company finds the best price for their product. Profit margin matters, but the amount sold matters as well. A very cheap price is going to sell a bunch of units presumably, but a profit per unit sold will be much less than if we had a higher price per unit. But that higher price per unit would result in fewer sales. So you've got to make this nice balance, you've got a way opportunity here, which would be the volume of possible trades, much like the amount of units sold, compared to the accuracy, which is how often we're actually correct with our prediction, which is more like profit margin. Even though that might not sound like profit margin, but since you might have, let's say 60% accuracy, and a very high volume of opportunities compared to 80% accuracy and low volume so then you've got a percentage profit margin.
So consider following. If you found an algorithm that will earn you $2 a trade and it is 85% accurate (very appealing!), with this your allotted an opportunity to deploy this tactic 600 times for 600 trades. That means you're going to at 85% you'd be successful with 510 of those trades. You would also lose 90 of them. So 510 successful trades at $2 a trade is $1,020, 90 unsuccessful trades at $2 a trade means you've lost $180, so your total profit in this scenario is 840 dollars.
Let's consider another situation. You still earn $2 a trade if successful, but we, actually, we've dropped: we're only 70% accurate. That said with that 70 percent accuracy, it's a loser algorithm, and gives you way more opportunity, you get 1800 trades this time. So this means out of 1800 trades at 70% accuracy you get 1260 successful trades for 2520 dollars in profit. This also means 540 trades are not profitable so you let you lose 1080 dollars. But your total profit in the end is 1440. Now compared to the old 840 that's much better.
So the above example, even though it might sound like well that was a lot more trades for such a small movement and accuracy, that wasn't really an under exaggeration. You just saw in the previous video how big of a change the move from 70 to 75 made. If we move from 70 to 85, I can demonstrate it to you, but there's a high chance that the chart may not appear correctly. Therefore, it is likely that we won't be able to fully visualize the data. This could potentially underestimate the opportunities for change. Also you lose comparable patterns, the patterns that are actually very comparable. So not only you lose opportunity, I think you're sacrificing accuracy as well, at the same time.
That's a huge wrench to throw into the equation, because, obviously we have an infinite number of variables, because, again, we could require something like 72.552251252551 accuracy, it's just unlimited. And you quickly find that you've got like an unlimited number of variables times another unlimited number of variables times another... So where do you even start? Accepted method, when it comes to machine learning, and navigating your way through infinity, is to continue adjusting in the same direction variables, that are producing and increasing performance, so as you tinker with a variable and performance is going up exponentially, you continue your tinkering with that variable, until performance drops. Then you know you've found a decent balance point. That said, as time goes on, it's very likely for all these variables to change, as volatility might change, the overall economy and whatever. You're going to notice that the variables themselves in the perfect balance is also changing.
That's what a machine learning is for, and this is kind of the downside to the idea of a neural network, which is most closely what we're doing here, if you do a neural network, huge neural network is the most accurate of probably even support vector machines.
But until you can do the computation of that huge a neural network, it's not the best method. Here, at least for our needs, so far, everything that we've done, even though python is slow, it can be done in like C with a decent computer but we will talk on that a little bit more in depth in a future video.
Definitely, required video, I realized we didn't do any programming, but you have to be made aware of where we stand at the moment, as far as what we're doing and what this means, what the implications of what we're doing are, and all of the variables that are coming into play already, that a few of which have unlimited variance to them.
So with that, I'm going to conclude the video 13 and in 14 we'll continue back on with programming and having a lot more fun and creating even more variables.
As always, thanks for watching, thanks for the support, for subscriptions and until next time!
Alright everyone, time gather our thoughts, and plant our feet.
So far, we've only done a few very basic things, so, it may seem like we've only just barely left the beach, but, the reality is, we're in very deep waters already. Let's consider the current situation.
We have a lot of variables already which will need to be accounted for. Not only do we have explicit variables, we also have implicit ones.
Our Explicit Variables:
-
Percent change as pattern recognition.
- this could be other things as well.
-
Start point to current point % change.
- as compared to point-by-point, or end to start.
- point by point will give us differing looking lines visually,
- end to beginning will give us end points that are more accurate.
-
Fixed pattern length of 30
-
Fixed value, or weight, of patterns, no matter how old or fresh they are.
-
Looking 20-30 points into the future for the outcome. Truthful? Smaller or wider?
-
Similarity required to bring pattern into consideration.
Implicit Variables:
Opportunity vs Accuracy.
In machine learning, the way we typically find the best scenario, is much like how companies find the best price for their products. Profit margin matters, but amount sold matters too! A very cheap price will sell many units presumably, but profit per unit will be less than a higher price per unit, which would result in fewer sales.
Here, we must also weigh opportunity, which is the volume of possible trades/much like the amount of units sold, comparing this to Accuracy, which is how often we're correct, which is much like the profit margin (since you might have a 60% accuracy in high volume opportunities, compared to 80% in low volume).
Consider:
You find an algorithm that will earn you $2 a trade, with 85% accuracy, very appealing. With this, you're allotted an opportunity to deploy this tactic 600 times, or for 600 trades.
This means, at 85%, you will be successful with 510 of those trades, and lose 90 of them.
510 successful trades @ $2 a trade is $1,020
90 unsuccessful trades @
A total profit of $840.
Let's consider another situation, which earns you the same $2 a trade if successful, but only has 70% accuracy. That said, it is a looser algorithm, thus giving more opportunity, and you get 1800 trades.
This means 1260 trades are successful, for $2520 profit.
This also means 540 trades are not, for $-1080 meaning total profit of $1440.
Now, the above example is actually more likely an under exaggeration. You will find as you loosen up the requirements, even by tiny degrees, opportunities added are usually exponential, so opportunity will go up very quickly as we adjust things, but, eventually, the return in profit will not match the risk. The goal is to find the perfect balancing point. As such, this is a very important variable to keep in mind.
Luckily for you, all of the above variables are capable of being machine learned!
If you consider the unlimited allowance of pattern length, and unlimited degree of comparison (since we can say we require something like 72.5522512525% accuracy)... you will find quickly that the combination of variables is unlimited... so where do we even begin?!
Generally, the accepted method with machine learning for finding the best combination of variables is to recalculate and continue following the path that is showing growing improvement with each step. As long as return on "change" continues growing, then you should continue. It's often compared to finding the quickest path down a mountain, like a rolling ball might. So long as you keep going down (improving) you keep moving variables in that direction until you stop going down, then change some others.
Lecture 14. Past outcomes as predictions: Machine Learning for Automated Trading in Forex and Stocks p. 14
Using past outcomes as predictions from our pattern recognition.
Source: Past outcomes as predictions: Machine Learning for Automated Trading in Forex and Stocks p. 14
Tutorial page: Past outcomes as possible predictions
Hello and welcome to the 14th machine learning and pattern recognition for use with stock and Forex algorithmic and automated trading! Where we left off? Ah, we was making some of you guys cry, probably, with all variables and issues that have already been arisen, but in this video we're going to continue a dredging on. And what I'd like to do in this video is since we're plotting all of the patterns on the exact same plot ,what would be cool, is if we plotted those patterns outcome. Every pattern that we put into storage, we also stored the outcome of that pattern. What would be cool is if we plotted the outcome of that pattern, and then you can see visually kind of what is the prediction like where will this line go. That's what we're going to do in this video is we're gonna actually plot it out visually to see where the line is predicted to go and then, obviously, eventually back test.
In the graph part where if patFound == 1:, let's get the outcome. First get index number of the pattern in storage: futurePoints = patternAr.index(eachPatt), because that
should match the exact index number of the outcome of that pattern in the outcome array. Do plt.scatter(35, performanceAr[futurePoints], c=pcolor, alpha=.4). We're going to make the x 35, just so it's not like way off the chart and distorts things, just understand that this isn't a perfect representation of the actual chart, but it will give us the idea of the prediction. The y is going to be that performance array at index futurePoints, that will yield the performance: performanceAr[futurePoints]. We colored these dots and color coded it, so green if that prediction was a good one in red if it wasn't. So, if it is greater then we're predicting a rise, if it is not greater then we're predicting a fall. alpha=0.4 because, just in case a couple plots are overlapping each other, or right on each other, or at least close to each other we'll be able to tell that visually. If they didn't have an alpha it would be solid and so if two plots were almost right over each other you would miss it, you wouldn't realize that was the case, so for our visual help and since we're making this for a visual representation it would just help. Save and run.
So this is what you should have gotten. So here is the pattern in question, and then here are the dots and keep in mind this is obviously distorted a little bit, so if we were to just look at the pattern itself (zoom in), now you kind of understand that okay. So when you get home (zoom out) it looks like a flat lawn pattern.
We can see the predictions, and as you can see some of these dots did indeed overlap each other, so it almost gives you the idea of the intensity. If you did the math it's most likely this is a positive prediction.
We've plotted out visually at least the prediction. What would be nice is to plot out reality, where did this actually go. Then we could also plot out the average prediction as well, so where is the average point about to be and where did it actually happen. Then, we can see if we want to actually continue on with this strategy.
Conclude video number fourteen. This time we just displayed our predictions. It's looking good, we've got clearly a positive prediction, hopefully the outcome is positive. That's what we're gonna be working on the next few videos and as well as the true outcome versus the true prediction and then eventually we'll be actually back testing this stuff to see if it's worth our time and energy to continue, because there are actually some more things that I haven't even brought up in the last video and I'd said I'd leave that, I didn't want to heat you guys with too much stuff. That's it for this video.
As always, thanks for watching, thanks for your support, your subscriptions and until next time!
-
Question: I was reviewing the code and I think this line:
if performanceAr[futurePoints]> patForRec[29]:should be changed into this one:if performanceAr[futurePoints]> 0:. I think it should be so asperfromanceAris the array of percent changes from the last data of the "historical pattern" to the average of the future ten points considered in calculating the performance. So it gives already the performance of the "historical pattern" which has been classified as similar to the present pattern. The original code line seems comparing the future performance of the "historical pattern" with the percent change of the present pattern from the beginning till the end of it.. Please let me know whether I am missing something.-
Answer: I agree, the performanceAr is calculated as the %change from
eachPatt[29] - Answer: He does this because you would only enter into a position once the machine has recognized the pattern, ie the end of the pattern. That way your return would literally be the difference in percent changes from the prediction to the end of the pattern (because they are both percent changes)
-
Answer: I agree, the performanceAr is calculated as the %change from
- Question: I think you should be changin "outcomeRange = avgLine[y+20:y+30]" to be "outcomeRange = avgLine[y+30:y+70]" since we now work with 30 points not only 10
-
Question: Harrison, please help my understanding. Where you check if predictions were good and color code red or green in following line:
if performanceAr[futurePoints] > patForRec[29]:ok, my thinking ispatForRec[29]is basically the most current return over last 30 intervals andperformanceAr[futurePoints]is a return overavgLine[y+20:y+30](some 10 intervals) . Why compare these two returns to each other. I'm thinking we want to know if certain pattern leads to returns, but it looks like you check if last 30 intervals of data set has better returns than some other interval in data set. please help my understanding. Thanks!!
Lecture 15. Predicitions From Patterns: Machine Learning and Pattern Recognition for Forex and Stock Trading
This video covers the basics of making future price predictions based on the outcomes of the previous patterns.
Source: Predicitions From Patterns: Machine Learning and Pattern Recognition for Forex and Stock Trading
Tutorial page: Predicting from patterns
Hello everybody and welcome to part 15 of machine learning and pattern recognition for the use with stocks forex automated trading algorithm! Where we left off? We were playing a chart and it gave all the predictions basically in the form of red or green and also where they were on the chart and now the next thing that we would like to do is let's actually plot out the actual outcome, because we are going back in data we do have the information to tell us what the true outcome was.
First, create allData = ((bid+ask)/2) (it is allData as we want to look into the future) in main section. Then, go right before we start plotting the other stuff and add realOutcomeRange = allData[toWhat+20:toWhat+30]. Next, reduce it, in other words, average it: realAvgOutcome = reduce(lambda x, y: x + y, realOutcomeRange) / len(realOutcomeRange) (note that it calculated exactly as in patternStorage). Then, do realMovement = percentChange(allData[toWhat], realAvgOutcome), we wanted a percent change, since our graph is a percent change chart but it's a percent change of something of the last point so just keep that in your mind. Them, plot that real movement: plt.scatter(40, realMovement, c='#54fff7',s=25). As it not on top of everything else, we're going to put this at an x of 40. Again, just like the other video, this isn't drawn to scale now, because, like the actual patterns themselves are being drawn to scale, but as far as like the predicted outcome and the future outcome the real outcome and all this stuff that we're going to plot, it shouldn't matter to you but just in case someone is like "hey what?". I just don't want to distort the chart there's no reason to put it out that far, because it's just strictly visual representation and it's like a prediction kind of stuff. So, x is 40, y is realMovement, color to the same color as that line (that makes sense, where is the actual ending of this line?), sighs is 25, really big dot of 25. Save that, run that.
This is a pretty ugly chart...[talking about charts, first time charts are differ]
Now, let's proceed to count these dots. Our objective is to determine the accuracy of the prediction. To achieve this, we will calculate the average intensity by considering both the most intense drop and the most intense rise. This will provide us with a realistic perspective. To simplify the analysis, we will compare the ratio between the red (fall) and green (rise) dots. This will serve as the basis for our prediction. In the next video, we will plot a prediction dot to help us make a decision on whether to proceed with creating a full back tester or not. Anyways that's going to conclude video 15.
As always, thanks for watching, thanks for the support, the subscriptions and until next time!
Using previous pattern outcomes to help us begin to predict future outcomes.
Source: Average prediction pattern recognition Machine Learning for Algorithmic Trading
Tutorial page: Average outcomes as predictions
Hello and welcome to part 16 of pattern recognition for algorithmic trading! Where we left off? We were drawing patterns, drawing or plotting the predicted outcomes, and color coding them, either green for up or red for down, and then we were also plotting the actual outcome. I forgot to mention on the last video the some of you might notice that perfect "zero zero" comes across here yet we still have some green ones underneath zero zero and some red ones you know continuing already in the negatives, and you might notice that well actually what's happening is here is the blue dot and the Reds are below the blue dot the greens are above the blue dot or the cyan line rather, and so that's really all this happening there so it's not it's not percent change a you know this here is percent change, but it's actually a pattern of percent changes, so it's not quite the same anyway if that was confusing anybody I just wanted to mention that I had somebody asked me about that.
Let's go ahead and plot the average of all of these quote unquote predictions.
Let's rerun the code and check for any errors. If there are no errors, we should see a visually appealing chart that displays patterns, predicted outcomes, average predicted outcomes, and actual outcomes. This is quite exciting!
Upon running the code, we observe that the first chart is rather uneventful. As expected, since we only have one predicted outcome, the average predicted outcome matches the actual outcome, which is an increase. We can consider this a successful prediction.
Moving on to the next chart, we have a more informative visualization with numerous plots. As anticipated, there are significantly more green (increase) predictions than red (decrease). The average prediction correctly indicates an increase, which aligns with the actual outcome. So far, we have achieved two successful predictions. Let's continue and see if we can find any incorrect predictions.
After hitting enter to proceed, we encounter another chart. It exhibits a similar pattern, albeit cut off at the end. As expected, the prediction is accurate, mirroring the previous chart. At this point, things are looking promising, indicating the potential for a backtest in the future.
In the next video, we will delve deeper into backtesting and discuss its implementation.
As always thanks for watching, thanks for the support, for the subscriptions and until next time!
This video discusses some of the performance issues with the program.
Source: Machine Learning and Pattern Recognition for Algorithmic Trading p. 17
Hello everybody welcome to the 17th machine learning for the use of automated trading and algorithmic trading! Where we left off? We were drawing that plot up, we made the predictions of basically our past patterns, where did they go, and then we saw where it really went and where our prediction was and whether or not we were right or wrong. So far we've been right every time. I don't suspect that it will always be the case, but pretty nice and is certainly helpful enough to get us to push forward. So now we need to consider it a few things though. We really need to back test this. Now, that said if you played with the data enough, you realize that in its current form plot to plot or point to point, even if you don't plot, is very slow. So just running through storing patterns, comparing patterns at every plot with our current processing time, a fullback test of this one month of this kind of tick data that we have, this interest second kind of stuff, if you do the math will land you at about one year of processing time. Now there's there's quite a few viable solutions to fixing that problem.
The issue of our processing is really mostly because Python is a single threaded nature. So natively Python simply is a linear programming language so it's not capable of what's called parallel programming so can't do multiple calculations at the same time right you can do threading quote/unquote threading with Python but natively you really can't so anyway so there's a few thats the issue and there's a few solutions so here are a few solutions.
one. you can leave Python and you could get Java or C or C something right and or you can just simply you keep Python but call up C for the pattern kind of stuff right so you for this you can either do that or you can even use something like scythe on or Jai thon which is kind of like the meshing of Python and either Java or C
two. you can simulate the threading on your own and so I'll show you guys an example of this towards the end here so what you can do like let's say for example your average processing time is 20 seconds so what you would need to do then since we have inter second data you would really need to pull up 20 Python windows and for every second you perform your calculation in that Python window and then everything just convenes in a similar database right a shared database and in this sense that's as good as as threading as you can hyper threading or or parallel programming as you'll get natively with Python and this isn't really that bad of a method it's just if you're just you have to account for that 20-second delay but the benefit here of course is that after a month you're not you know when you're backlogged right so so there's that
number three you can use CUDA. CUDA is a way to utilize your GPU or your graphics card for processing now obviously you're going to need it what's called a CUDA enabled processor otherwise basically meaning NVIDIA GPUs usually higher-end NVIDIA GPU to do this and if you are interested you I might actually do a video or a few videos on doing this kind of thing in the future but again you will need an Nvidia CUDA enabled GPU and
therefore we could also change the timeframe of the data right honestly we probably don't need to be using intra second tick data. You can probably do this with really just even just a little bit better at one minute open high low close data right using the closed numbers, and that would cut down our data significantly, right 60 times smaller. So that would be pretty helpful it would cut down on the amount of patterns in the timeframe has. Well, it's really not the size of the file right 50 kilobytes or 50 sorry it's 50 megabytes I think for the one month that's not too bad once it's read into memory but the problem is the amount of patterns that makes, and yeah it's just a ton of patterns so anyway, obviously processing time is a bit of an issue.
Now the next thing that we can kind of consider though is not only can we do some of the things above, we can also for one only load in the full list of data once instead of loading it in every times right now we're doing it every time just to fully simulate an unknown scenario but that wouldn't you wouldn't really need to be the case you could you know run in store patterns only once every day, like once a day, and do it and that way you were only sacrificing a few minutes or you can do it even once a week right so the markets do closed, so you can do that. now and also really in this entire script here there's a lot of things that we can do to clean it up so there are definitely a lot of things that you can do as I kind of mentioned earlier I'm mostly I'm here to kind of teach you the theory and the principles and show you that it does indeed work not really here I mean people get paid large very large salaries to do this kind of thing and so I'm not really looking to do that for you, so anyway unless you want to pay me a very large salary then we can talk. so there's ask now anyway so back test I think is an option we definitely want to do it but we should probably thread this back test and because one I mean I think after looking at her data from the visual results we can see that 1) for sure pattern recognition part is working and 2) it does appear to be successful right in predicting the future outcomes. so we definitely want to back test it. so we need to build something to actually back test this so so what we want to do is do that and then what I what I think we'll do is after we build this to back test it. I'll show you the results I will just write it myself you can also thread it also it's very simple to do it . so at least in the way that I'm doing it so we'll thread it and then you can actually see the results I ran for about 800 it'll be about 900 to 1000 results each one and then add it up would be 8,000 results how accurate were we every step of the way.
so pretty interesting stuff going forward and in the next video we'll be setting up the back testing and then I'll show you the results of that back testing. Anyway concluding this video.
As always, thanks for watching!
- Question: Hi, I have been following your videos with great interest and find them quite useful. On the topic of performance management, you didn't mention the map-reduce paradigm for distributing the processing of the data. Is there any reason for that ?
-
Question: I ve been following your entire tutorial. Great stuff. On that one, you don t mention multiprocessing when about trying to be more efficient to analysis all the patterns. Is there a reason for that ?
- Answer: Just wasn't one of the things that popped up in my head at the time. That is indeed another option, thanks for bringing it up.
-
Question: How would I go about making the change from tick data to minute, 5-minute, or even 15-minute?
- Answer: Resampling. There's a tutorial for that: https://pythonprogramming.net/resample-data-analysis-python-pandas-tutorial/
Lecture 18. Preparing back-test: Machine Learning and Pattern Recognition for Algorithmic Trading p. 18
In this video, we set up the back-testing for our pattern recognition and predictions.
Source: Preparing back-test: Machine Learning and Pattern Recognition for Algorithmic Trading p. 18
Hello everybody welcome to part 18 of machine learning for the use of algorithmic trading! Where we left off? In the last video I just bringing up more variables and more problems with as we continue on this journey together. But we left off with the idea that let's go ahead and actually do some back testing and see if it's really worth our time. because some of those hurdles coming up we need to decide whether or not it's worth our time and energy to continue. Let's begin building the back test.
the first thing that we really want to do in this back test is we don't need to be displaying graph anymore so the first thing we want to do is get rid of all this graphing stuff. So everywhere we see something that's related to drawing your graph we're just going to comment it out.
So the first spot if pat pat found equals one - comment that out. Next part or well comment come at the figure part out don't come at if pat found anyway um come at that part out next comment out this plot here comment out plot here. Continue scrolling comment out coming out comments out come in town comment down. And that should comment out everything, because we're not calling um oops where have I gone we're not calling graph FX so we don't need to comment this stuff out that should be everything that we're graphing.
now the next thing that we want to do is we want to develop a back test. To do the back test we need a few things right we need to know are we accurate or not and then also we need to store that kind of like an array right or keep track of it right do we were we accurate or not yes or no and then as time goes on how many samples have we done and then... but how many times we accurate divided by how many samples we have and boom you've got yourself in a percentage accuracy.
So let's begin building for that. So looking at this a few of the things that we could stand to move are the following we can move... I'm still thinking now we want average law in there but we can take out let's just take out pattern storage and we can run that once all the way through so we didn't have to do that every time if we wanted we could take out and move a few things instead of running it every time that would kind of help processing time I can't release out if I really want to do that but if you did you can move some of these things out to be global and then so like if you did you know you could run it like every day run and compare pattern and store patterns but I think what I'll probably do in the future is maybe just have like a pattern storage script that you just run it every now and then stores all patterns then you visit that those patterns but I guess for now for the back tester we can just leave this in here and let's just build what we need for the back test.
so a couple things let's make an accuracy array and that'll be empty to start and then let's make a samp's and that'll be also empty to start of course and every time there's runs we have another sample so we'll just say down here samp's plus equals one and so we know like how many samples we actually ran through now the next thing we want to do even though it wouldn't really necessarily be trade worthy but anyways next thing that we want to do is come up to our actual graphing I think the best way to do this see it's going to be kind of hard because here we need to do it for each pattern and then down here we kind of need this stuff in the order without changing up a whole bunch of stuff so we're going to kind of work around that I guess and the first thing that we'll do is we'll come over here indent and then we'll say bread array that's going to be empty array so pred array for prediction sorry hit the Mike prediction array and now what we'll do is as we come down here if the color is so if it's greater that means this color was Green and for anybody that forgot so positive or prediction will be we'll just say that's one for up right and then we'll come down here oops come down here and if the color is red then we want to repent pred or a pen a negative one point zero zero this way when we do the averaging it will automatically do decimals for us then after that we want to do I guess we're done there the next thing that we want to do is after this for loop right now we want to do um so in line with all of this stuff we want to do some stuff so first let me just delete octane Posada phone line I guess yeah we'll just delete this now what we'll do is let's just to make sure that we actually are on the right track well go ahead and print the prediction array just so we can see it visually because when you start doing stuff like this you might think you're expecting some something specific in here and that way if something is going wrong you can just look at it and be like oh well that's not what I wanted at all so now what we will do is print prediction or make a prediction average and again we're going to use this lovely lovely function that we've created for ourselves and come back here prediction average equals ready and we're going to use pred array in the variables here so pret array and put ray now so that'll be the average of all the predictions so it'll either be above zero or below zero as an average right so now we'll say print prediction average just to make sure we're on the right track and then we'll say if prediction prediction average is less than 0 that means spring drop predicted right
Subsequently let's print hat for rack 29 so the plot in the pattern where is that now print real move keep in mind real movement was present change from all data that last point in the plot to the actual outcome so what is so we've got our prediction is to drop then we want it to print the last point then we want to print out what was the actual movement so we can see visually whether or not a drop actually occurred
Subsequently if real movement is indeed under pat for Rhett 29 congratulations accuracy array append 100 you know 100% accurate else accuracy or a hope and several. Next up, we ought to do the other side of the equation, so if prediction average is greater than zero print "rise predicted". N we want to do the same thing and actually um let's save ourselves our fingers and copy paste and the only thing we really need to change is the phone fact.
So it's probably a good idea to go ahead and check your accuracy and so if prediction average is above zero that does mean a rise and we just want to print the variables just to make sure we're doing it right and logically if real movement actually does indeed is indeed higher than that last plot so our prediction turned out to be accurate we want to say that specific extra prediction was accurate, continue. so it adds that to the accuracy right which we just made down here is empty but it will get populated with either 100's or zeroes and now if we come down to the bottom here this means under all of this we can now say print and we say back-tested accuracy is comma string accuracy average plus a little % because we're awesome oh and then we'll say after comma samp's um samples since that is exactly what they are um okay. I think that's it we might have had a typo somewhere where you did a lot of edits and stuff you always run the risk we've been doing pretty good lately so we're definitely coming up on an error soon so anyway we'll run it and I think we actually have that press Enter ticking yeah we do that's another thing we want to remove from our script so we can actually run this and walk away so because we'd kind of like to run it for a while so pattern storage we could buy delete that too but that's okay I'm just kind of waiting for a response one one
rise predicted and looks like it was good but we're not for whatever reason entire process so I guess it's a print enter back test accuracy and accuracy average is not defined I swear we define this Oh let's see hold on.
I thought we had to find it but I guess not so what we need to do is another one of those sexy lambda equations so let's go ahead and take this and copy come over and we're going to do accuracy average equals paste and in here we actually want to be accuracy array where is that here it is accuracy array array and it's go ahead and remove move on
run this again let me drag this down and we wait suspense is killing you guys okay with one sample we're so far 100% accurate so I'm going to pause this for a little bit and let it run through a few okay well after 12 samples here we're still running at 100% accuracy in theory we should eventually hit something that's incorrect. But, anyways, what I'll do here is I'm going to show you guys now I've been running this back test against a lot more data for a lot more samples and I've got about one of them is going very slow and only has 570 the other ones are about 900 samples and at different intervals within so here is an example of the accuracy is pretty good everyone is at least over 50% so that's always nice to see. Let me pause this and I'll resume the video over them all
right this is eight different scripts that were started at different points I did I think it's like 35,000 lines in 37,000 lines in 40,000 lines in 42,000 lines and so on so anyway this first one is through 915 different tests it's 57 percent accuracy kind of a string of zeros lately it used to be it started off very accurate and I guess it's going south this one has 76 percent accurate it had a nice string of 100's there this one 72 74 64-58 88 and this one a freakin awesome 98% Wow anyway so that's that and it's on against you know about let's see got nine hundred times a - about 400 since everyone's running really slow so really about 6800 samples so far and we have so I guess I could run that math real quick to posit water on that the average accuracy here. So our average accuracy is seventy three point five so that's pretty impressive if you ask me I'm pretty happy about that accuracy
That's going to conclude a video what is this eighteen hopefully you guys have enjoyed the series so far it looks like we've got a pretty good pattern recognition with pre darn good accuracy as far as friction in the future is concerned.
As always, thanks for watching, thanks for the support, for the subscriptions and until next time!
- Question: hi, one big mistake i see is that you are comparing average outcome of next 20-30 days to the change of price from 30th day of pattern to the first day to say if that was a rise or fall you should compare the average outcome of next 20-30 days to 0 in order to know if it was a rise prediction or not
-
Question: 7:20 Stop, stop. Why do you compare last movement in a pattern with real movement after it? Maybe you should better compare realMovement with 0 (whether direction of it matches with predicted direction) or with predictedAvgOutcome. Ok. If you place 0 there instead of pathForRec[29] like i suggested, you will get 50-52% accuracy which sounds more likely. Trading with this algorithm is no better than flipping a coin - you manage to choose the correct direction half of a time.
- But the prediction array is based on a comparison to pathForRec[29] as well so just changing that doesnt make sense. A postive prediction average means that the predicted percentage change is higher than the current percentage change. So a -10% current change and a -5% predicted future change would be a negative. So if the actual future change was a -7% the prediction would have been accurate. But if you compare the real movement to zero you are excluding many correct predictions hence your 50% accuracy.
- -10% current change and -5% predicted future change means predArray should be 1 and rising is predicted so we should buy in this case. but what's the result? Real future change -7% is less than -10% current change according to code the accuracyArray is 100 but if we follow the signal to buy ,we will lose 7%. Is it reasonable?
- maybe I did mix my numbers up. But anyway the way the code is set up is not for direct buy and sell. The way it is now is simply whether the percentage change will be greater or less than the current change. You could change the appropriate threshold to 0 if you want it the way you describe
In this video, the series is wrapped up.
Source: Conclusion - Machine Learning and Pattern Recognition for Algorithmic Trading p. 19
Hello everybody and congratulations on what's possibly going to be one of the last videos in this series this is really kind of the last video I really want to make there I might add a few videos as time goes on but this pretty much is going to mark the end of this series. We've covered everything I really want to cover the things that are left is I do want to show one more thing in this in the script which is what you're looking at here.
And otherwise just keep in mind all of the variables that we've already brought up and that is how long the patterns are we going to look at what is the required similarity that we're going to allow for what's the timeframe that will even look back on patterns what is the way that we're even calculating similarity all that stuff that we've already brought up.
Again the way that you machine learn this kind of stuff is you start playing with those variables and as long as performance increases in an escalating manner so it continue it gets better to a degree that's even better than the previous change right as long as that is the case you continue manipulating that variable until it that is no longer the case and then you move on to another variable.
Pretty much the best method because really a lot of these variables or there's an infinite number of changes you could make. so that's that. There's just no way we could possibly cover all of that in a series I mean there's it's just it's that would be a huge huge undertaking.
This just was just meant to be educational and cover the basics and you guys can go do as you please from here now the only change I was going to I was going to show you guys and what's up here right now is the about 99% of our processing time is spent in this function right here pattern recognition so there's a couple of things we can do with this.
One we could take this function and write it in C and then create a Python import for this using you could do like scythe on ours so you can use scythe on and scythe on eyes something. You can use you could literally write it and see and just make it an import for Python you could use Jai thon and probably do this quicker see there's all those options and there's really a bunch of things that you can do to speed this up.
The other thing you could do as far as pattern recognition is concerned is do what we've done here where each each step of the way we're requiring a 50% similarity at least for the first 10. this way what's happening is is in the sport that's really this four loop that's causing the most trouble because if the 70 percent similarity is not met for that pat-pat found to be one then it doesn't even run this stuff so the main issue is really this four loop right here so there's a few ways you could speed this four loop up.
One of them is just to like if this one similarity is not greater than 50% no need to continue this one's not great and so each step of the way because naturally if we leave it the way that we've had it even if this is you know a thousand percent different and this is five thousand percent different and this is a two hundred percent different it's still going to go through everything anyways. So here we can cut it off right away and you could go all the way through the entire 30 if you wanted to do that and save on some processing so just going through these right here I dropped processing time by about 50% and so that wasn't too bad
the other thing you can do is use different arrays like numpy array or you can use imports there's an import called blissed and depending on your race size that can be better so you can check stuff like it that out or again put this entire function C and just import the function itself so really there's a lot of options there.
But I'm going to leave that to you guys to figure out on your own.
So now what I'm going to go ahead and do is in the background I'm going to be showing off a visual representation of all of our predictions and the outcomes to those predictions so the thin lines right R are comparable patterns that we found you should recognize those the thick cyan line is the actual pattern that's in question so you should recognize that so far the red and green dots represent each patterns outcome and as such the prediction either rise fault right so the rise is a green dot and if it's fall it's a red dot. That really only means rise or fall so not the degree at which it would rise or fall and then that's all averaged together to create an average rise or drop which is plotted in that kind of dark blue plot and then finally we have the cyan plot which is the actual outcome and so if you don't know what sign is that you probably do but it signs like a light blue so the dark blue is the predicted outcome sign plot is the true outcome. And just keep in mind the prediction is really only directional so it's not attempting to predict the exact number it's just directional so if you were trading it as long as the prediction was to continue falling you would you know continue selling and as long as the prediction was you know continued rise you would hold okay so that's all that that would mean so anyway we're going to be putting that in the background as I discuss a few things that I consider to be pretty important to this series like the disclaimer says in the beginning of every video and I said in the beginning of the series the series was for educational use only now I didn't just say that for legal reasons I mean it.
So first off you know this program is is very basic yet you can see already the complexity that is already coming to us right and so not as well not only is the field of triste trading overall very very tough but quant analysis and algo trading overall is really difficult and the competition is very challenging people are paid million dollar salaries just to produce stuff like this you know if people come out of MIT or Harvard or whatever and they're paid million dollar salaries just to spend their time devoting the mathematics and algorithms to this practice right so that's your competition the figure is about somewhere between 95 and 99 percent of traders lose money in the market period.
Next of those 1 to 5 percent of people that aren't maybe losing money most of them don't actually beat the market either. Really they're losing money and taking more risk then than if they just invested pure in the market now what I mean by that is if you compare to say the SP five hundred growth year today today today is October 14th 2013 as I'm filming this and year today the sp500 index is up 20% so if you just bought the S&P 500 and held it so say you bought an index fund like the SP Y right the spy you be up 20% and if we included dividends which you also get if you would have held you up 21.5% so here today 21.5 percent and you've done nothing you've done you put in really no effort besides the execution of the purchase you've paid one commission on this, basically, and you're left with a bunch of free time right so despite the name automated trading I've never met an auto / algo trader who didn't spend most of their time dealing with it so it's not like it's a passive income and everyone interested in quantity you know like the numbers right surely must agree that we even just the one to five percent odds of winning those are horrible odds right you want an executed trade or a group of trades with one to five percent odds unless of course the you know the outcome was thousands and thousands of percent if you got it right you know but that's not what's at stake right and so so know but yet a lot of people are taking these 1 to 5% odds and so it is kind of strange but I get it you know the field is very appealing it's exciting it's sexy but when you break it down it's gambling most of the time so so with that just be aware of what you're getting into if you decide to continue to pursue this exact field all right and always compare your results to something like the SP 500 on long term scale.
I recognize I'm not the smartest guy in the room all the time and some people really are smart enough and really do beat the market and make a lot of money doing it right and but the problem is most of Quon traders think that's them right they think they're smarter than everybody writing it and soon find out that they're not and and you know some people are actually just addicted to the gambling part of it and treat the markets that way so you don't want to do that either or you know and in the worst part is they don't realize there it's the gambling they're addicted to all right the rush
All of that said, machine learning, pattern recognition, data manipulation that I mean it's all it's all just fun right I made this series mostly for fun and to teach I realize that's kind of silly sounding to most people they don't quite understand why that's fun but it's fun to me and if that's you then you know what have at it right that's what I was doing here and if you're that tiny you know percentage that's just brilliant and they can make Bank off this then I'm also happy for you right just just be smart about this stuff and I was happy to at least just teach you guys but I certainly don't want to lead anybody on thinking that if you do what I've just showed you you're going to make a ton of money you're going to probably lose all of your money if you traded on this system.
So please don't do it so along the lines of it being fun as well uh this entire series and program was made by me just straight on the fly have no experience at all with pattern recognition when it comes to like a line I do it a lot with sentiment analysis but that's a lot different than the pattern recognition of a line. So that should also shed some light on how basic this program is and also the possibility of there's to be something wrong with this the entire thing was just kind of made as I went right so I was just kind of doing it as I went and filmed and it was it was kind of fun and interesting but uh it is certainly a very basic program
Luckily if you get to this point and you realize oh my gosh you're right that's a crazy idea machine learning and pattern recognition can be used for all kinds of things and I'll probably have some more video series coming out for that kind of purpose I wouldn't mind doing one on image recognition stuff like that so like facial recognition and if you do know machine learning it's a great skill to have and this the skill alone can make you a good sizable amount of income like facial recognition and not really so much anymore but not too long ago that would have gotten you like an instant government government contract for big huge money more than you'd make in the market probably.
So anyway good skill to have programming as well overall so if anything you got that now and I enjoyed the series hopefully you enjoyed the series
As always thanks for watching thanks for all the support in the subscriptions and until next time!