How does Gun work - amark/gun GitHub Wiki
If you were brought here from another link; we welcome you to the community! We love your questions and absolutely strive to provide quality answers. The aim of this page is to reduce the repetitiveness of typing out long explanations that have already been answered before. Most of this information is available in other places like the Gun documentation, Github, Projects, Gitter, and elsewhere. The objective is to bring all of this information together in one conclusive place.
First and foremost, Gun is a community of people. The content we are about to cover would not be possible if it weren't for the dozens of contributors to Gun. Expanding upon the official definition of what Gun is
GUN is an ecosystem of tools
we can see that Gun is much more than just a decentralized database. In fact, you could use Gun for streaming data or calling RPC (Remote Procedure Calls) without storing that data at all. In real world examples, Gun could be used for streaming GPS coordinates, games, video and audio. It could be set up for IoT (internet of things) where all your devices speak to one another and coordinate scenes. Your imagination is the limit of what you can build with Gun. The storage part of Gun is just one layer out of the many. The objective of this Wiki is to cover the responsibilities and use cases of each part.
Here is an overview of the layers and how they fit together.
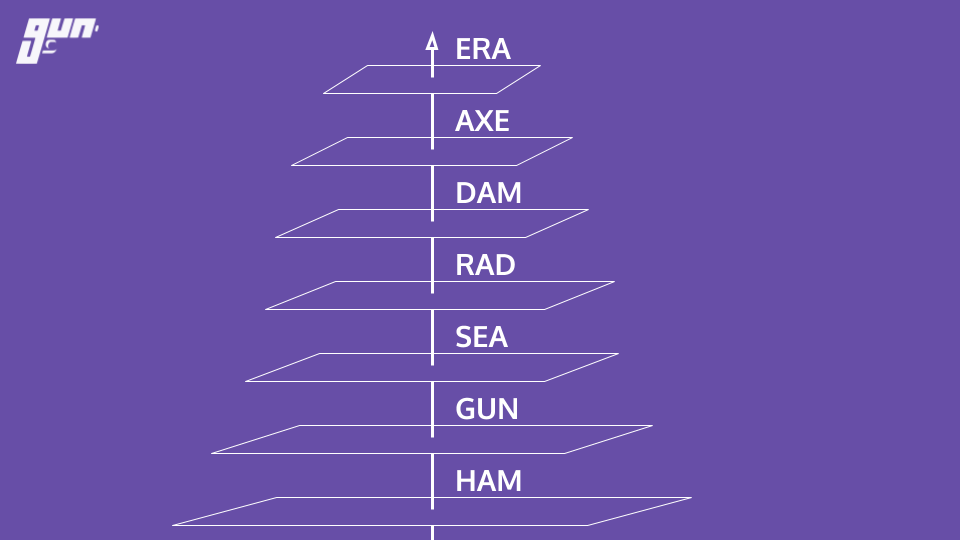
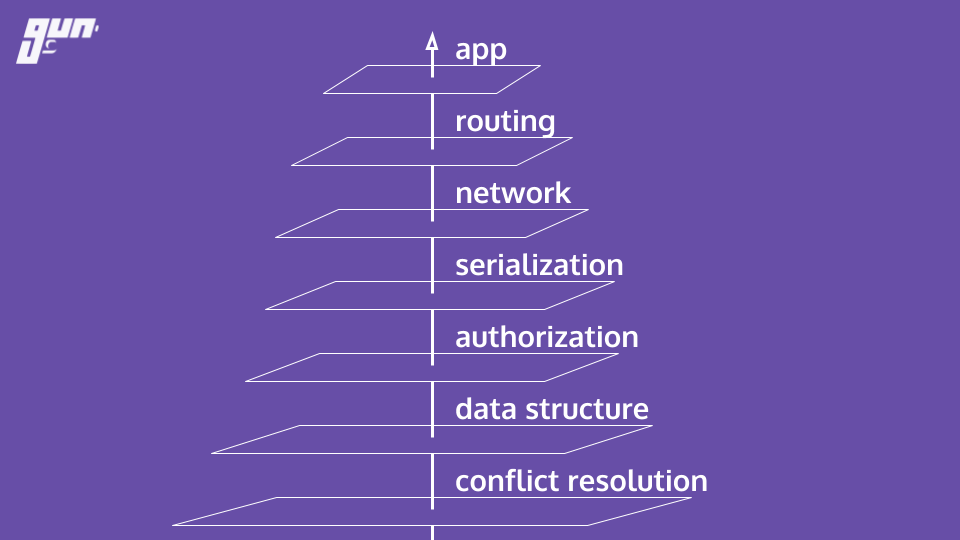
Eventual consistency and conflict resolution
HAM is the crux of the operation. Eventual consistency and conflict resolution are provided by HAM. But what does that mean? Before Gun, regardless of what type of technology you might of used - there was an underlying problem. You had to choose between consistency, high availability, and partition tolerance. Woah! That's a lot of tech mumbo jumbo. Let's break this down or skip to these slides for a cartoon representation.
Consistency is when you want data to be stable. If you put data in, you want it to be the same across the network and you don't want it getting lost. An example of this would be a chat application. Alice is in a chatroom and sends a message at the same time Bob sends one. Behind the scenes if the databases were ever to disagree which message should come first - you end up with poor results. On one screen, you may see Alice sent the message first and on another screen Bob sent his message first. Or even worse, they may not even store the messages at all!
Gun solves this issue with a technique called Eventual Consistency, which we'll go into more later. Having databases agree on which message comes first is not straightforward and shouldn't be dismissed lightly. Some would even argue that you shouldn't settle for Eventual Consistency. Instead we should replicate our user's data across several federated, limited, expensive servers while not providing any real data security or consistency. After all, isn't the new business model to collect and sell user data? (sarcasm)
In the above chat example, let's say Alice and Bob were in different parts of the world. Running a website from one location would provide a significant delay to one of the users in the form of something called network lag. A company may solve this issue by running multiple servers closer to their users. They would then use a special method to coordinate the data between these servers. If they had managed to solve the consistency problem above, this would be their attempt at solving availability.
The other issue availability aims to solve is if a server is interrupted due to technical or environmental issues. If the database that serves those users goes down, they need their data to be backed up somewhere in the event of catastrophic data loss. Companies will replicate that data across many servers for issues such as these. They end up with higher maintenance and infrastructure costs due to the waste generated.
Gun solves this issue by replicating your data across many other users (called peers). This reduces the requirement of having servers, infrastructure, maintenance, and specialized employees in the operational fields. The last, being an extreme expense simply due to the nature of being highly specialized in running constantly changing specific commands, investigating issues, and analyzing network and file data.