10. MaxCompute Spark支持交互式Zeppelin - aliyun/MaxCompute-Spark GitHub Wiki
由于安全原因,用户无法触达生产集群的网络,所以MaxCompute Spark一直没有放开 yarn-client的支持,也就是Spark-Shell,Spark-SQL以及PYSPARK等交互式功能一直无法支持。Zeppelin on MaxCompute Spark可以在一定程度上支持用户交互式需求。这个模式相对于local模式更有力的地方是,这个模式其实是真实用了yarn-cluster模式运行着的,local模式仅仅能验证语法是否正确,而zeppelin模式能以分布式的方式提供交互式查询,这个对于那种需要关注性能结果的debugging是有帮助的。
- 一键启动脚本:
- spark 2.3 见 spark-zeppelin-public.sh
- spark 2.4 见 spark-zeppelin-public-2.4.sh
- 下载脚本到本地后,运行
sh spark-zeppelin-public.sh后,会自动下载相关组件如下- spark-zeppelin-public.conf
- spark-zeppelin-public.jar
- spark-2.3.0-odps0.32.1.tar.gz
- 第一次运行脚本会出现以下错误,这是因为默认的
spark-zeppelin-public.conf并没有配置accessId,accessKey,projectName
linxuewei:spark-zeppelin-public linxuewei$ sh spark-zeppelin-public.sh
working dir: /Users/linxuewei/Desktop/spark-zeppelin-public
download spark-zeppelin-public.conf
download spark-zeppelin-public.jar
download spark-2.3.0-odps0.32.1.tar.gz
extract spark-2.3.0-odps0.32.1.tar.gz
export SPARK_HOME
spark-zeppelin-public.conf checking
TBD count is 3, plz check config make sure id key project is written!
config check failed, plz set id key project in spark-zeppelin-public.conf
-
注意Spark 2.4.5需要添加
spark.sql.catalogImplementation = hive 和 spark.sql.sources.default = hive之后再运行sh spark-zeppelin-public.sh -
Spark 2.4.5添加
spark.hadoop.odps.spark.libs.public.enable=true和spark.hadoop.odps.spark.version=spark-2.4.5-odps0.33.1这两个参数可以加速包上传速度 -
正常配置
spark-zeppelin-public.conf之后再运行sh spark-zeppelin-public.sh
linxuewei:spark-zeppelin-public linxuewei$ sh spark-zeppelin-public.sh
working dir: /Users/linxuewei/Desktop/spark-zeppelin-public
export SPARK_HOME
spark-zeppelin-public.conf checking
config check passed, start spark-submit
就会启动一个MaxCompute Spark作业,等待作业执行结束之后,可以回溯日志,找到logview
http://logview.odps.aliyun.com/logview/?h=http://service.cn.maxcompute.aliyun.com/api&p=zky_test&i=20190710044052214gy6kc292&token=eXN6eFlsNmQzOFV4dUIzVEVndm9KQUtVSlVNPSxPRFBTX09CTzpwNF8yNDcwNjM5MjQ1NDg0NDc5NzksMTU2Mjk5Mjg1Mix7IlN0YXRlbWVudCI6W3siQWN0aW9uIjpbIm9kcHM6UmVhZCJdLCJFZmZlY3QiOiJBbGxvdyIsIlJlc291cmNlIjpbImFjczpvZHBzOio6cHJvamVjdHMvemt5X3Rlc3QvaW5zdGFuY2VzLzIwMTkwNzEwMDQ0MDUyMjE0Z3k2a2MyOTIiXX1dLCJWZXJzaW9uIjoiMSJ9
- 打开
logview点击master-0点击StdOut
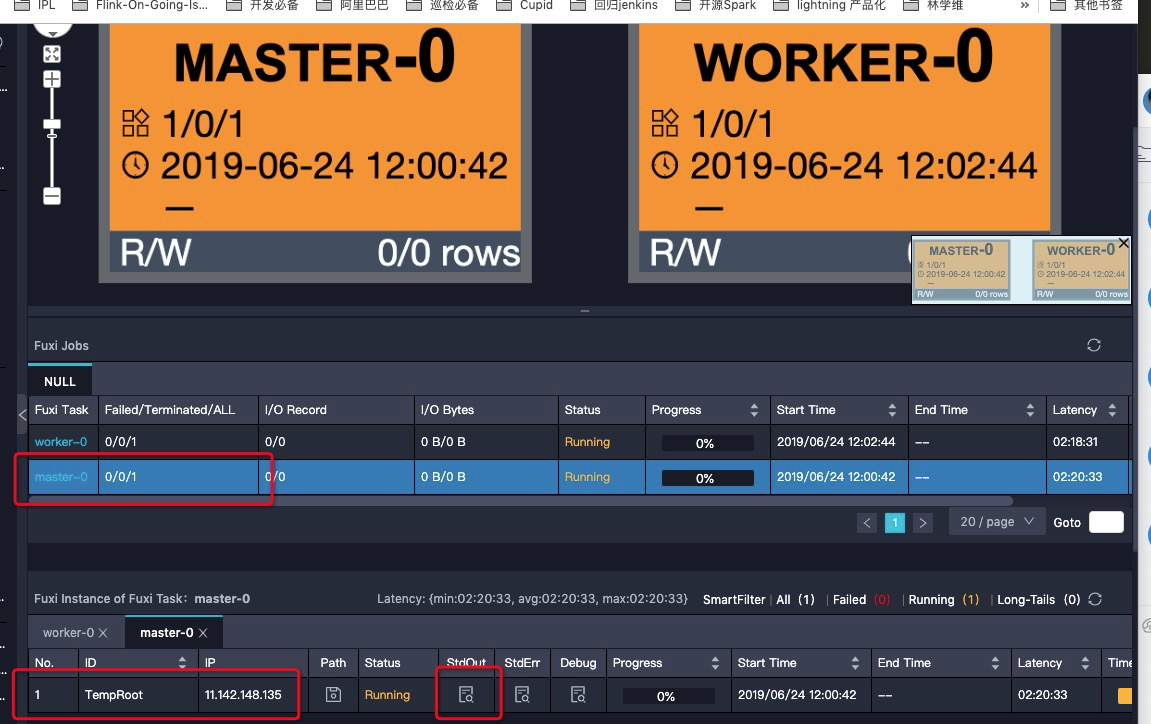
# 日志中的这个url,就是zeppelin server的地址了
# 直接复制粘贴到浏览器上即可访问,弹出的url会需要云账号的登录
Please visit the following url for zeppelin interaction.
http://20190710044052214gy6kc292-zeppelin.open.maxcompute.aliyun.com
Log dir doesn't exist, create /worker/zeppelin_logs/
Pid dir doesn't exist, create /worker/zeppelin_pids/
Zeppelin start [60G[[0;32m OK [0;39m]
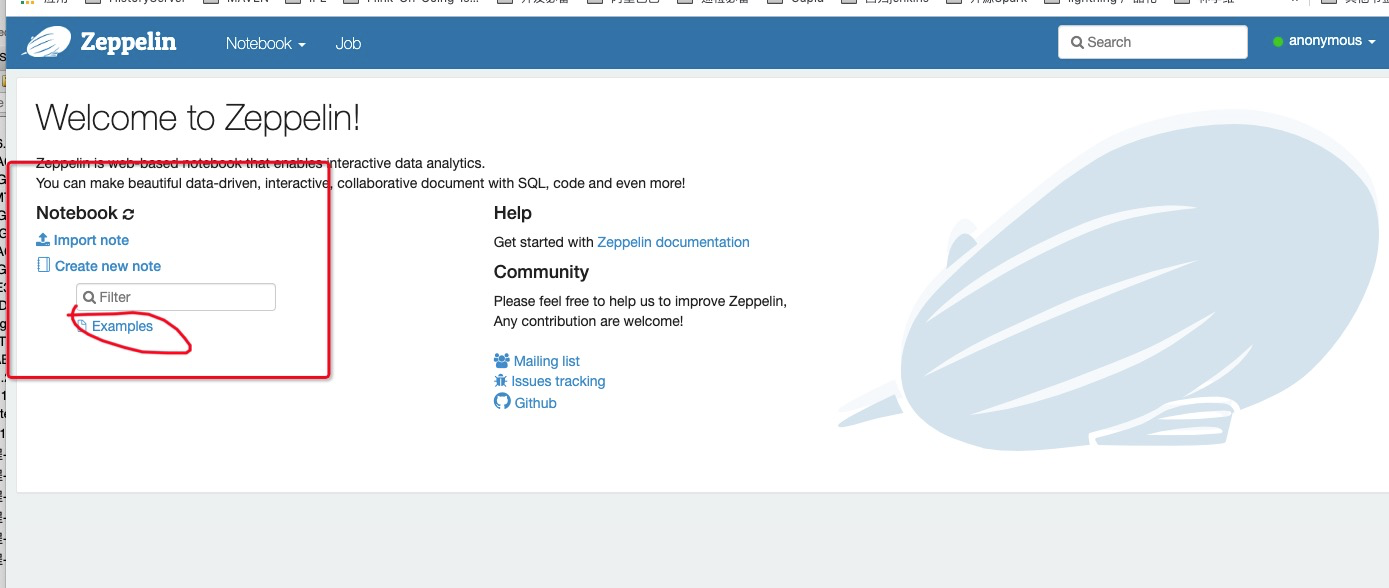
- 打开
zeppelin url打开ExamplesNotebook,有时候页面会显示endpoint not exist的日志,这是因为zeppelin还没有启动完毕的情况,稍等片刻就可以
- 如果页面弹出一个
interpreter binding的页面,直接点击Save即可,然后再点击ToolBar上的运行所有按钮即可执行Notebook上的代码的执行
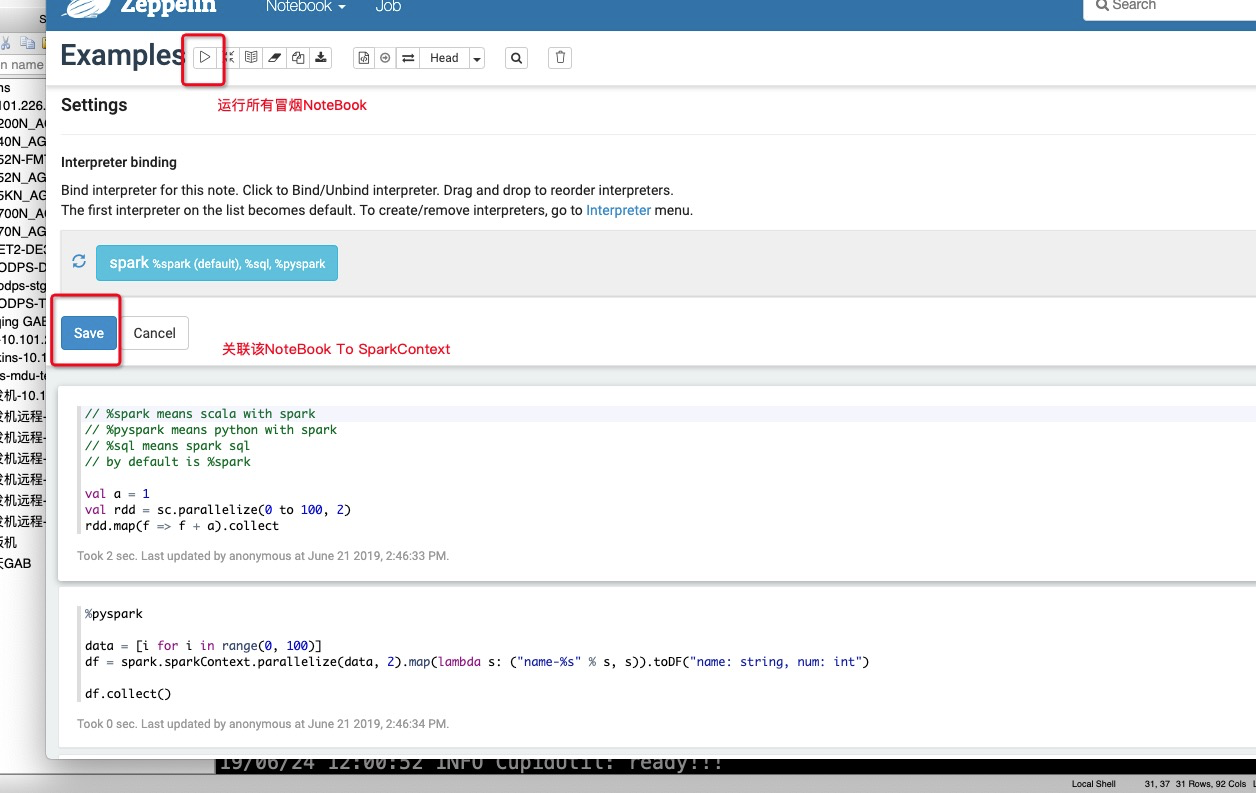
- 从 examples 样例中我们可以看到,NoteBook支持三种语法
- 以
%spark开头表示 scala 执行器 如果不写就默认是这个模式 - 以
%sql开头表示 spark-sql 执行器,默认用ODPS External Catalog - 以
pyspark开头表示 pyspark 执行器,默认用我们打包好的 python2.7
- 以
本质上Zeppelin Server on MaxCompute Spark还是一个Spark作业,默认这个作业会存活三天,如果你想手动关闭这个作业的话,就请用odpscmd,用kill <instanceId>; 命令来停止作业释放资源吧。