07. Streaming读写DataHub - aliyun/MaxCompute-Spark GitHub Wiki
MaxCompute支持Spark Streaming(DStream)和Spark Structured Streaming,本文介绍Streaming作业流式接收DataHub数据源的示例。
首先, 得在阿里云DataHub拥有数据源,DataHub控制台传送门
-
获取projectName
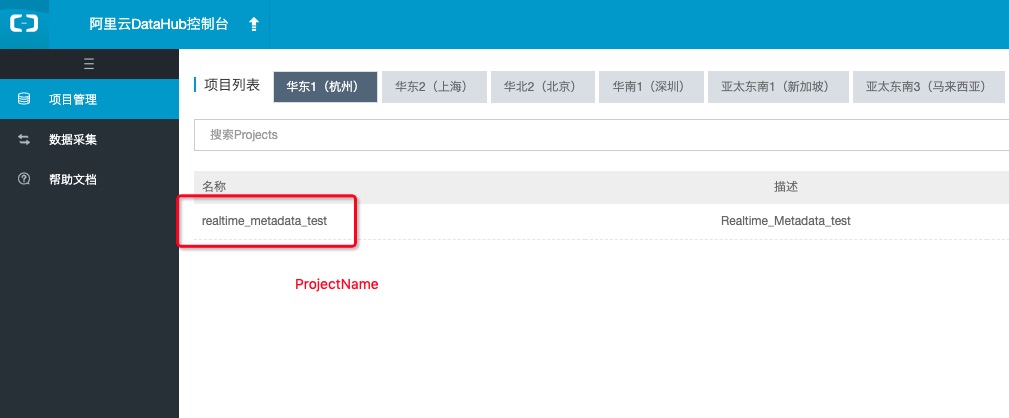
-
获取topic
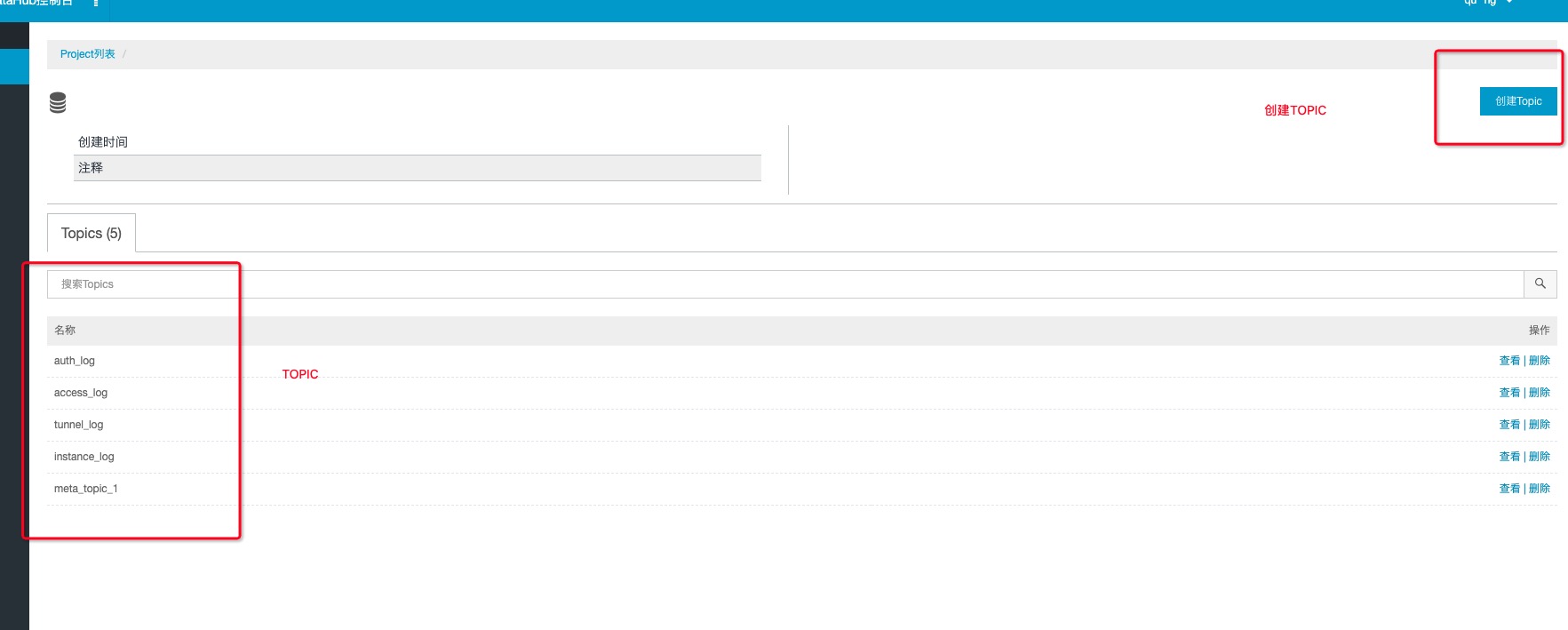
-
获取subId
注意,每一个Streaming程序只能对应一个subId,如果有多个程序要读同一个topic,那么需要多个订阅
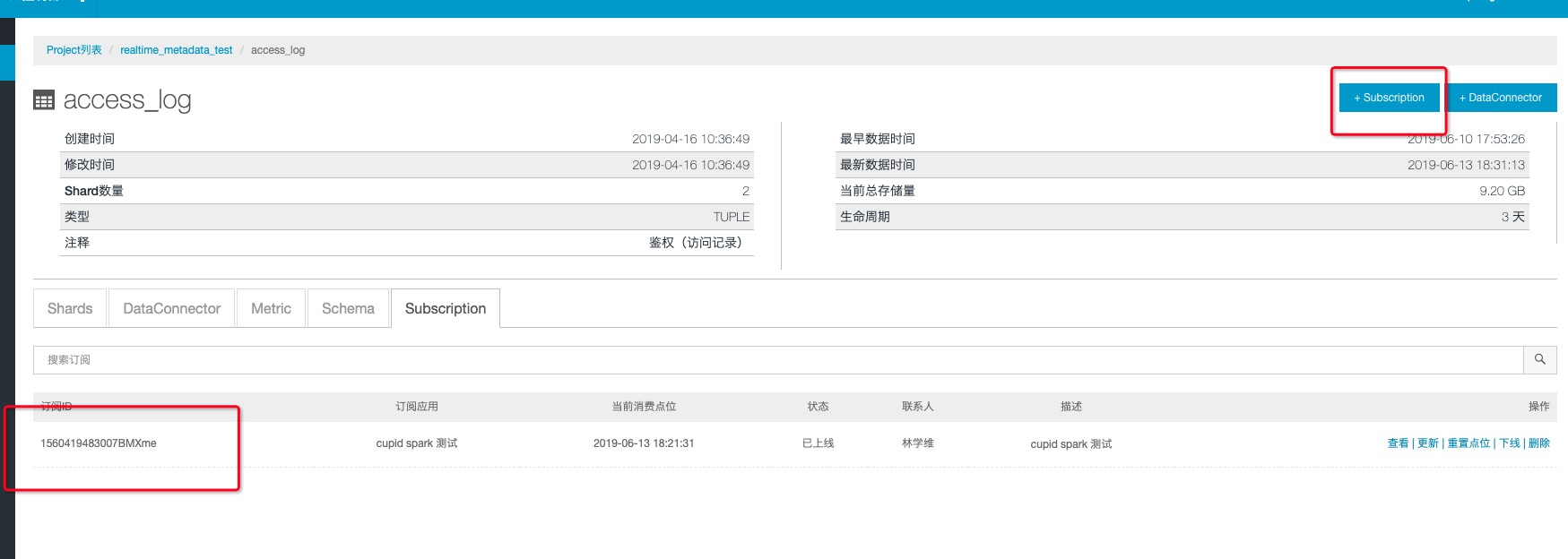
- 获取endPoint
每个region的endPoint都是不一样的,参考如何配置EndPoint
<!-- datahub streaming依赖 -->
<dependency>
<groupId>com.aliyun.emr</groupId>
<artifactId>emr-datahub_${scala.binary.version}</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>aliyun-sdk-datahub</artifactId>
<version>2.9.4-public</version>
</dependency>
<!-- datahub streaming依赖 -->
val dataStream = DatahubUtils.createStream(
ssc,
"projectName",
"topic",
"subId",
"accessId", // 云账号accessId
"accessKey", // 云账号accessKey
"endPoint",
transferFunc(_), // 见Demo注释
StorageLevel.MEMORY_AND_DISK
)
利用DStream+Dataframe可以把DataHub数据回流到MaxCompute
source的示例如下(请参考代码):
val stream = spark.readStream
.format("datahub")
.option("datahub.endpoint", "http://....")
.option("datahub.project", "project")
.option("datahub.topic", "topic1")
.option("datahub.accessId", "accessId")
.option("datahub.accessKey", "accessKey")
.option("datahub.startingoffsets", "latest")
.option("datahub.maxoffsetsperTrigger", 20000) // optional
.load()
sink的示例如下:
val query = spark.writeStream
.format("datahub")
.option("datahub.endpoint", "http://....")
.option("datahub.project", "project")
.option("datahub.topic", "topic1")
.option("datahub.accessId", "accessId")
.option("datahub.accessKey", "accessKey")
.load()
其中datahub.endpoint请使用经典网络ECS Endpoint,各region对应的endpoint参考此文。此外,需要将endpoint配置在VPC访问配置中,参考VPC访问。示例如下:
{
"regionId":"cn-beijing",
"vpcs":[
{
"zones":[
{
"urls":[
{
"domain":"dh-cn-beijing.aliyun-inc.com",
"port":80
}
]
}
]
}
]
}
注意: 目前所给的这个Demo,没有启用checkpoint,checkpoint需要使用oss作为checkpoint的存储,另外Spark Streaming作业处于试用阶段,作业最长运行时间不能超过3天,如果需要投入长时间正式运行使用,请联系我们开通相关权限。