Iteration 4: Design - agarcia169/4306-Donaldson-Project GitHub Wiki
Donaldson Twitter Analysis - System Design Document
Introduction
Purpose of the System
Donaldson Company would like to try and anticipate what technologies future industries are going to push towards to replace traditional internal combustion engines, as some of their business currently involves making filters for gasoline and diesel. One possible means of predicting future technologies is possibly through analysis of content published via social media. In our case, we're syphoning information from Twitter to attempt to analyze what technologies companies might be leaning towards in the future.
Design goals
Our current design goals are to have a functioning system that
- Can search through a database looking for a company.
- will return the data if the company is present.
- return an error message if company already exist.
- be able to differentiate between different types of powertrain character.
- be able to pull tweets from any company within the database.
Definitions, acronyms, and abbreviations
NLTK - Natural Language Tool Kit
VADER - Valence Aware Dictionary for Sentiment Reasoning
NLP - Natural Language Processing
Tweepy - 3rd party Twitter API access tool
References
https://dev.mysql.com/doc/connector-python/en/connector-python-example-connecting.html
https://www.nltk.org/howto/sentiment.html
https://dev.mysql.com/doc/connector-python/en/connector-python-example-connecting.html
https://www.Donaldson.com/en-us/
https://ojs.aaai.org/index.php/ICWSM/article/view/14550
Proposed software architecture
Overview
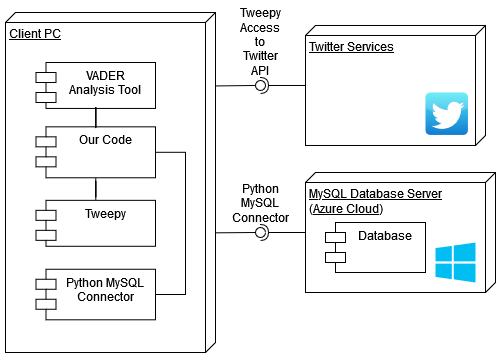
The software will, for ease of development and maintenance, work in a manner similar to that of a repository. Grabbing Tweets will involve accessing Twitter through Tweepy. These Tweets will then be saved to a database. Then the Tweets in the database will be analyzed for tone, and that analysis will be saved to the database. Tweets will also be checked to see if they mention a particular powertrain, and that information will be saved to the database.
This modular approach means that (so long as the database is running), no piece of the software is beholden to another piece of the software operating. While it might make more sense from an efficiency perspective to grab the Tweet from Twitter, analyze it for powertrain and tone, then save all of that data to the database, all in one long pipeline, if we design things with that structure in mind and then any one of those three parts stops working, no part can be tested until it's working again.
This modular or repository-style approach will mean easier development, and will mean other parts of the software will continue to run even if one part ceases to function (except the database, that's vital). At the end we can consider trying to make the process more efficient by doing all the analysis at once (assuming Twitter still exists at that point).
Subsystem decomposition

Hardware/software mapping
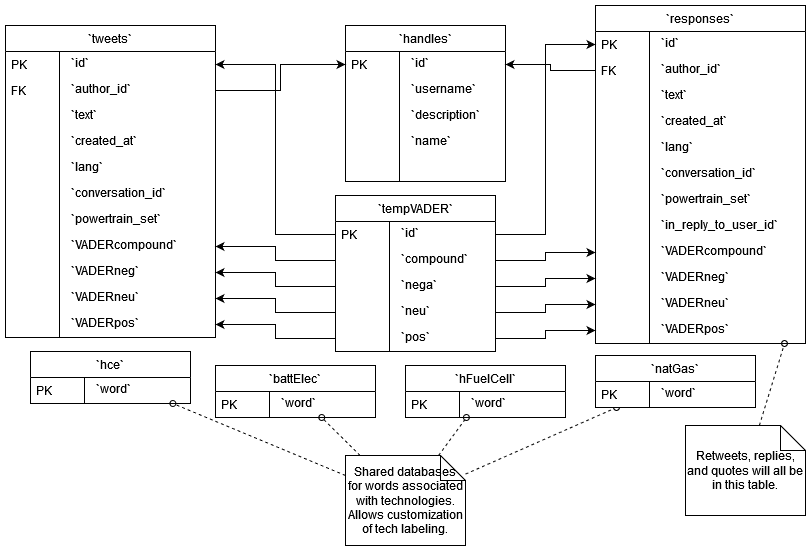
Persistent data management
MySQL database, structured like so:
Access control and security
Global software control
There should be no synchronization problems since any user using the software will automatically be updating the data base with any new command that adds a company. Also with donaldson being the client they will be the only one to edit this code so that they can make any adjustments they see fit.
Boundary conditions
This program will be used when Donaldson would like to search their databases for a company and it can also add a company if needed and it can easily be shutdown with a simple exit command. Also errors that will be seen will be coming from if the user tries to add a company already in the database or they try to search for a powertrain set that is not in the database.
Subsystem services

Glossary
NLTK - The Natural Language Toolkit is a platform used for building python programs to work with the Human Language it contains text processing libraries for tokenization, parsing , classification and semantic reasoning it was originally developed by Steven Bird, Edward Loper, and Ewan Klein for the purposes of program development and education purposes
Sentiment Analysis - the process of computationally identifying and categorizing opinions expressed in a piece of text, mostly used to determine whether the writer's attitude towards a specific topic is positive, negative, or neutral
VADER - Valence Aware Dictionary for Sentiment Reasoning is a module that is based within the initial package of NLTK and can be applied directly to unlabeled text data. VADER analysis relies on a dictionary that can map lexical (relating words) to emotion intensities known as sentiment scores. which the score can be found just by adding together intensities of the sentence.
Appendix: Project Plan
