JAKE - adammoore/corda GitHub Wiki
So, at the hackday it became clear that it would be useful (necessary) to build in a storage / caching functionality to the mediating layer (Which we've been calling JCAL) - at least for caching interim results
While mulling the best way of bolting on a NoSQL / MongoDB type thing like the kids do these days, I thought that instead, if we were going storage, maybe that might actually be a bit of a revised approach...
So we still have the connectors to the sources of information - these are API / custom exports of ORCID iD information. These are then linked to elasticsearch via custom ingestors and the dashboard is generated via Kibana so the Jisc Custom Abstract Layer becomes the Jisc Abstraction to Kibana via Elasticsearch (JAKE) - I've even generated one of my amazing low fidelity diagrams:
!(https://blog.mimas.ac.uk/ukorcidsupport/wp-content/uploads/sites/23/2019/02/jake-low-fi-01.jpeg)
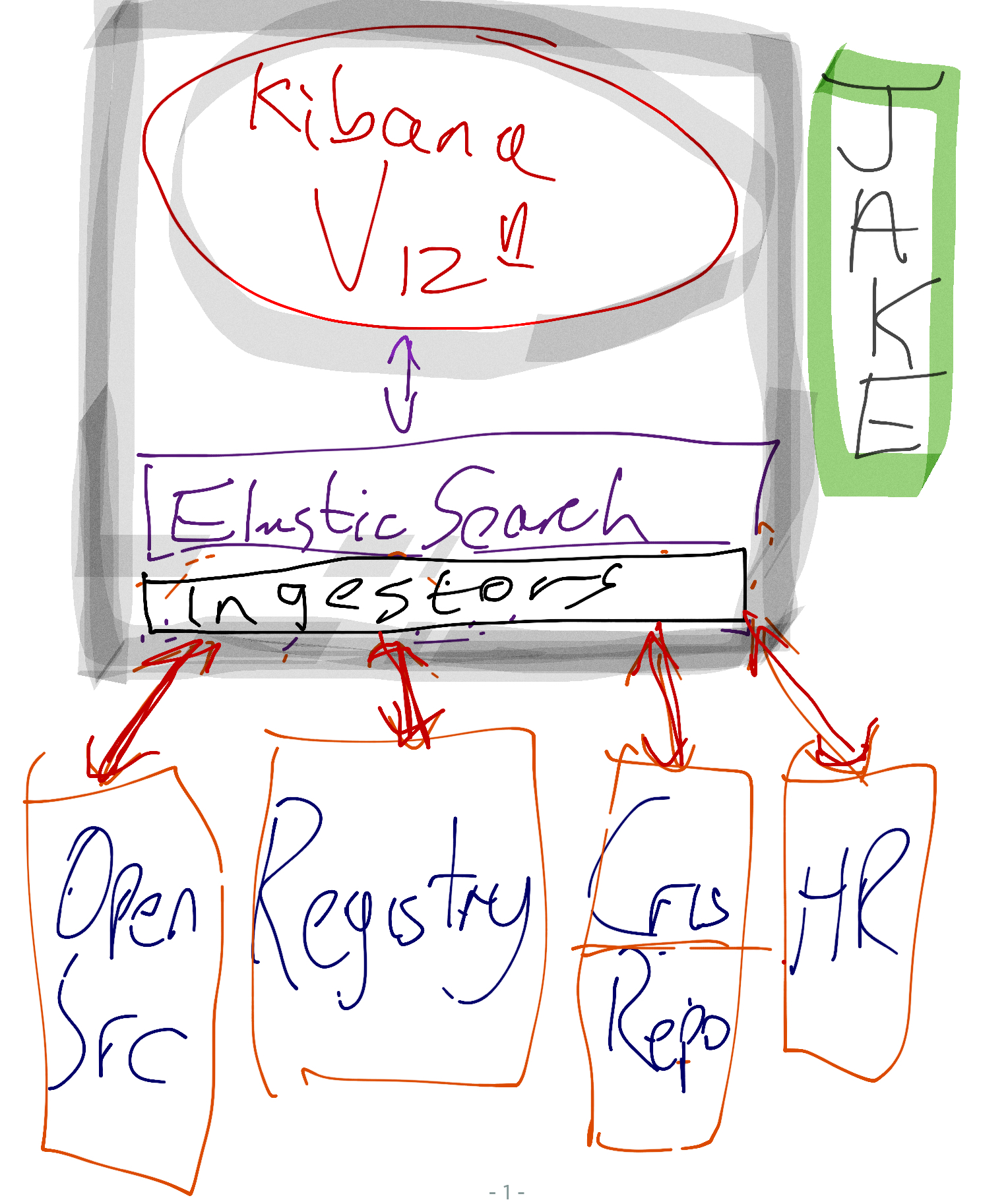{kind=link}
Obviously expressing it like this has lost some flexibility in the design / visualisation elements of the dashboard but in return for a sensible framework to build on (and you can always build out from elastic queries longer term). I think the question is whether the diagram still expresses the overall idea as initially conceived and if as a pragmatic stack it makes sense in the medium term...
Name Comment