KMeansFunction - acromusashi/acromusashi-stream-example GitHub Wiki
クラスタリング(K-means)機能
本ページでは、機械学習のクラスタリング(K-means)機能の利用方法について説明します。
処理内容
本機能は学習ストリーム、評価ストリームと2つのフローがあり、各々は以下のフローで動作します。
学習ストリーム
- WatchTextBatchSpoutが学習に使用するデータを1行1データとして読み込みます。
- 読み込んだデータをKmeansCreatorを用いてエンティティに変換します。
- KmeansUpdaterが読み込んだデータを用いて学習を行い、InfinispanKmeansStateを使用して学習データをIn-Memory DBに保存します。
評価ストリーム
- KMeansDrpcClientがDRPC Serverに対して学習データを用いたクラスタリングクエストを送信します。
- DRPCSpoutがDRPC Serverからリクエストを受信します。
- リクエストをKmeansCreatorを用いてエンティティに変換します。
- KmeansQueryが学習データを用いてクラスタリングを行い、クラスタリング結果をKMeansDrpcClientに返却します。
準備
クラスタリング(K-means)機能を動作させるためには以下の準備が必要です。
- Step1: 必要となるミドルウェアのインストール
- Step2: K-meansクラスタリングTopologyのデプロイ
- Step3: K-meansクラスタリングTopologyの設定
- Step4: DRPC Serverプロセスの起動
Step1: 必要となるミドルウェアのインストール
下記の手順を確認し、必要ミドルウェアのインストールを行います。
Step2: K-meansクラスタリングTopologyのデプロイ
Step2: acromusashi-stream-exampleのデプロイ を参照し、Topologyのデプロイを行います。
Step3: K-meansクラスタリングTopologyの設定
Nimbusをインストールしたサーバの/opt/storm/conf 配下にKmeansTopology.yamlを配置し、下記(★項目)の設定を行います。
## KmeansTopology Config
## ★NimbusHost
## Set StormCluster's Nimbus Host
nimbus.host : "192.168.0.1"
## NimbusPort
nimbus.thrift.port : 6627
## WorkerProcess Number
topology.workers : 3
## parallelismHint ThreadNum
topology.parallelismHint : 3
## Storm Debug Flag
topology.debug : false
## TopologyDefine
## ★Tridentの管理情報を保存するZooKeeperホスト
transactional.zookeeper.servers :
- "192.168.0.1"
- "192.168.0.2"
- "192.168.0.3"
## ★Tridentの管理情報を保存するZooKeeperポート
transactional.zookeeper.port : 2181
## Spout
## ★KMeans用のテストデータの配置パス&ベースファイル名
## parallelismHint設定に応じて「ベースファイル名_【TaskIndex】」のファイルが読みこまれる。
## 例)「Kmeans.txt_0」「Kmeans.txt_1」
kmeans.datafilepath : "/opt/acromusashi-stream-ml/"
kmeans.datafilebasename : "Kmeans.txt"
## StateFactory
## ★学習モデルを保存するサーバアドレス。「host1:port1;host2:port2;host3:port3...」という形式で定義
kmeans.stateservers : "192.168.0.1:11222;192.168.0.2:11222;192.168.0.3:11222"
## 学習モデルキャッシュ名称
kmeans.cachename : "default"
## 学習モデルのマージを行う間隔
kmeans.merge.interval.secs : 30
## キャッシュ上に学習モデルを保存する期間
kmeans.lifespan.secs : 360000
## Creator
## ★投入データを分割する文字列
kmeans.delimeter : ","
## Updater
## キャッシュに保存する際のベース名称
kmeans.statebasename : "KMeans"
## 識別する際のクラスタ数
kmeans.clusternum : 3
## Query
## ★DRPCサーバアドレス
drpc.servers :
- "192.168.0.1"
## DRPC機能名称
kmeans.drpc.function : "kmeans"
Step4: DRPC Serverプロセスの起動
Nimbusインストールサーバにログインし、下記のコマンドを実行してDRPC Serverプロセスを起動します。
service storm-drpc start
実行
クラスタリング(K-means)機能は下記の手順で起動します。
- Step1: K-meansクラスタリングTopologyの起動
- Step2: クラスタリングリクエストの送信
- Step3: K-meansクラスタリングTopologyの終了
Step1: K-meansクラスタリングTopologyの起動
Nimbusインストールサーバにログインし、下記のコマンドを実行してK-meansクラスタリングTopologyを起動します。
cd /opt/storm
bin/storm jar acromusashi-stream-example-x.x.x.jar acromusashi.stream.example.ml.topology.KmeansTopology conf/KmeansTopology.yaml false
Step2: クラスタリングリクエストの送信
Nimbusインストールサーバにログインし、下記のコマンドを実行してKMeansDrpcClientによるクラスタリングリクエストを送信します。-dオプションに続けてクラスタリングを行いたいデータを入力してください。
java -classpath conf:acromusashi-stream-example-x.x.x.jar:lib/* acromusashi.stream.example.ml.client.KMeansDrpcClient -c conf/KmeansTopology.yaml -d "10,10,10,10"
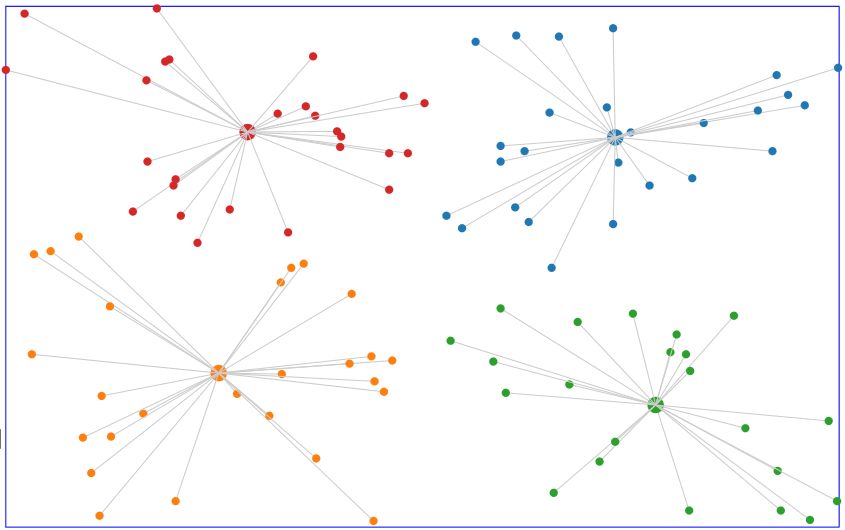
コンソールにクラスタリング結果が出力されることを確認します。
- クラスタリング結果イメージ
/images/kmeans-demo.jpg
{kind=link}
Step3: K-meansクラスタリングTopologyの終了
Nimbusインストールサーバにログインし、下記のコマンドを実行してSNMPTrap受信Topologyを終了します。
cd /opt/storm
bin/storm kill KmeansTopology
解説
WatchTextBatchSpoutでは起動直後、および学習データファイルが更新された場合にファイルを学習データとして読み込んでいます。