Curso Profesional de Arquitectura de Software - Yessica54/carrera-front-end GitHub Wiki
Definiciones
Atributos de calidad Son las expectativas de usuario, en general implícitas, de cuan bien funcionará un producto
Atributos:
La Idoneidad Funcional tiene que ver con la conexión del usuario (tareas u objetivos a resolver con el sistema) y como están implementadas funcionalmente en dicho sistema. Se puede dividir en 3 partes:
- Completitud funcional: cuan completa esta la implementación con respecto a lo que se espera del sistema. Requerimientos Funcionales vs Funcionalidades implementadas
- Exactitud funcional: cuan preciso es el sistema para implementar lo requerido. Resultados Esperados vs Resultados Obtenidos
- Pertinencia funcional: cuan alineado esta lo que se implemento con lo requerido. Objetivos Cumplidos vs Objetivos Esperados
La Eficiencia de Ejecución se trata de que tan eficiente es el sistema a la hora de responder y del propio sistema, como aprovecha o desaprovecha los recursos.
Se divide en 3 partes cada una con atributos que deben ser comparados entre si:
- Tiempo de comportamiento: Tiempo transcurrido entre: Pedido vs Respuesta y Tiempo esperado vs Tiempo máximo tolerado.
- Uso de recursos: Consumo de recursos vs Consumo esperado.
- Capacidad: Límite de tolerancia detectado vs Límite de tolerancia esperado
La **Compatibilidad ** es el grado en el cual un producto, sistema o componente puede intercambiar información con otros productos, sistemas o componentes, y / o realizar las funciones requeridas, mientras comparte el mismo entorno de hardware o software.
Esta característica se compone de las siguientes subcaracterísticas
- Interoperabilidad Grado en el cual dos o más sistemas, productos o componentes pueden intercambiar información y usar la información que se ha intercambiado.
- Coexistencia Grado en el cual un producto puede realizar sus funciones requeridas de manera eficiente mientras comparte un entorno y recursos comunes con otros productos, sin impacto perjudicial en ningún otro producto.
La **Usabilidad **es el Grado en el cual un producto o sistema puede ser utilizado por usuarios específicos para alcanzar objetivos específicos con efectividad, eficiencia y satisfacción en un contexto de uso específico. Esta característica se compone de las siguientes subcaracterísticas:
- Reconocimiento de idoneidad. Grado en el cual los usuarios pueden reconocer si un producto o sistema es apropiado para sus necesidades. Ej: Appro. recog: Wordpress usado para cualquier cosa que no sea blog.
- Curva de aprendizaje. Grado en que un producto o sistema puede ser utilizado por usuarios específicos para lograr objetivos específicos de aprender a utilizar el producto o sistema con efectividad, eficiencia, ausencia de riesgo y satisfacción en un contexto de uso específico. Ej: Lenguaje de gestos en aplicaciones móviles.
- Operabilidad. Grado en el cual un producto o sistema tiene atributos que hacen que sea fácil de operar y controlar. Ej: Formularios largos o de múltiples pasos. Sistemas gubernamentales.
- Protección de errores. de usuario Grado en el que un sistema protege a los usuarios contra errores. EJ: Sistemas de pago, incertidumbre en el estado del pago.
- Estética de la interfaz de usuario. Grado en el cual una interfaz de usuario permite una interacción agradable y satisfactoria para el usuario. Ej: UI vs UX.
- Accesibilidad. Grado al cual un producto o sistema puede ser utilizado por personas con la más amplia gama de características y capacidades para alcanzar un objetivo específico en un contexto de uso específico. Ej: imágenes con texto, sin alt. Contenido redundante o mal marku.
La **Confiabilidad ** son los atributos que tienen que tienen que ver con el uso normal del sistema a través del tiempo:
- Madurez, El grado en que un sistema, producto o componente satisface necesidades de confiabilidad bajo operación normal. Ej: Sistemas de compras. Sistemas bancarios.
- Disponibilidad, Grado en el cual un sistema, producto o componente es operacional y accesible cuando se requiere su uso. Ej: SLAs, contratos de servicio. Sistemas con eventos de carga pico puntuales.
- Tolerancia a fallos, Grado en el que un sistema, producto o componente funciona según lo previsto a pesar de la presencia de fallas de hardware o software. Ej Aplicaciones móviles.
- Capacidad de recuperación, Grado en el que, en caso de interrupción o falla, un producto o sistema puede recuperar los datos directamente afectados y restablecer el estado deseado del sistema. Ej Sistemas distribuidos, configuraciones auto-escalables en la nube. Puede estar conectado a la mantenibilidad.
La Seguridad es grado en que un producto o sistema protege la información y los datos para que las personas u otros productos o sistemas tengan el grado de acceso a los datos apropiado para sus tipos y niveles de autorización. Esta característica se compone de las siguientes subcaracterísticas:
-
Confidencialidad, Grado en el cual un producto o sistema asegura que los datos solo sean accesibles para aquellos autorizados a tener acceso. Ej: Redes sociales.
-
Integridad, Grado en el que un sistema, producto o componente impide el acceso no autorizado o la modificación de programas o datos de computadora. Ej: Sistemas bancarios.
-
Comprobación de hecho, Grado en que se puede demostrar que las acciones o eventos tuvieron lugar, para que los eventos o acciones no puedan ser repudiados más tarde. Ej: Firmas digitales. Logs de auditoría.
-
Traza de responsabilidad, Grado en el que las acciones de una entidad se pueden rastrear de manera única a la entidad. Ej: Logs de auditoría.
-
Autenticidad, Grado en el cual se puede probar que la identidad de un sujeto o recurso es la reclamada. Ej: Autenticación de 2 factores. Correo electrónico, número de teléfono. Datos biométricos.
La Mantenibilidad es la característica representa el grado de efectividad y eficiencia con la que un producto o sistema puede ser modificado para mejorarlo, corregirlo o adaptarlo a los cambios en el entorno y en los requisitos. Esta característica se compone de las siguientes subcaracterísticas:
-
Modularidad, Grado en el cual un sistema o programa de computadora se compone de componentes discretos tales que un cambio en un componente tiene un impacto mínimo en otros componentes. Ej: Patrones de arquitectura. Sistemas distribuídos.
-
Reusabilidad, Grado en el cual un activo puede ser utilizado en más de un sistema, o en la construcción de otros activos. Ej: Código de código abierto.
-
Analizabilidad, Grado de efectividad y eficiencia con el cual es posible evaluar el impacto en un producto o sistema de un cambio intencional a una o más de sus partes, o diagnosticar un producto por deficiencias o causas de fallas, o identificar partes a ser modificadas . Ej: Conexión entre código y requerimiento (pepinillo)
-
Modificabilidad, Grado en que un producto o sistema puede ser modificado de manera efectiva y eficiente sin introducir defectos o degradar la calidad del producto existente. Ej: Cobertura de código en tests.
-
Testabilidad, Grado de eficacia y eficiencia con el que se pueden establecer los criterios de prueba para un sistema, producto o componente y se pueden realizar pruebas para determinar si se han cumplido esos criterios. Ej: Funciones puras: ayuda efectos secundarios. Principio de responsabilidad única. Buenas prácticas de diseño.
La Portabilidad es el grado de eficacia y eficiencia con el que un sistema, producto o componente puede transferirse de un hardware, software u otro entorno operacional o de uso a otro. Esta característica se compone de las siguientes subcaracterísticas:
-
Adaptabilidad, Grado en el cual un producto o sistema puede ser adaptado efectiva y eficientemente para hardware, software u otros entornos operacionales o de uso diferentes o en evolución. Ej: Arquitecturas específicas de dominio. Abstracción y separación.
-
Instalabilidad, Grado de eficacia y eficiencia con el que un producto o sistema puede instalarse y / o desinstalarse con éxito en un entorno específico. Ej: Tiendas de aplicaciones.
-
Reemplazabilidad, Grado en el cual un producto puede reemplazar otro producto de software especificado para el mismo propósito en el mismo entorno. Ej: Sistemas distribuidos. Microservicios.
Tensiones entre atributos
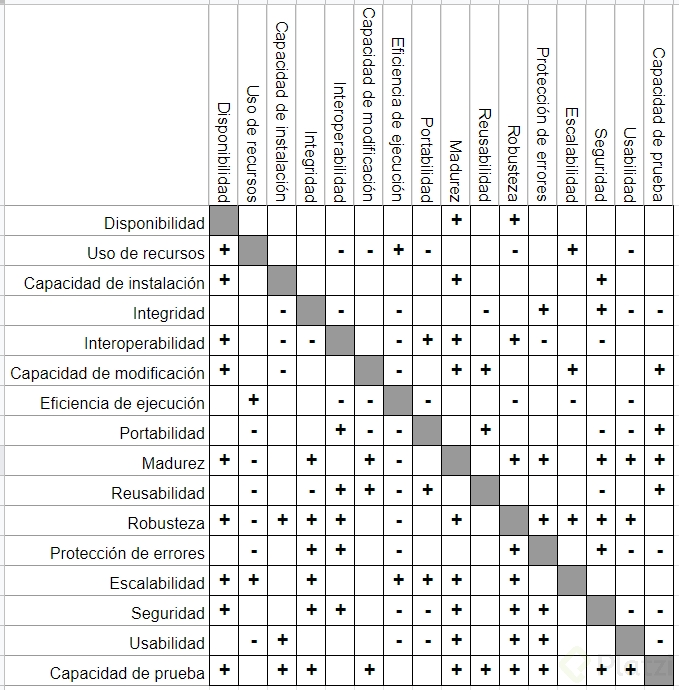
Patrones monolíticos vs distribuidos
los Patrones de Arquitectura son decisiones de diseño importantes ya tomadas para generar un esquema, estructura o tipo de comunicación entre componentes.
- Monolíticos: Despliegue de un artefacto que contiene todas las partes de la aplicación.
- Distribuidos: La aplicación está separada en partes desplegables independientemente.
- Gran bola de lodo: Una gran bola de mierda…
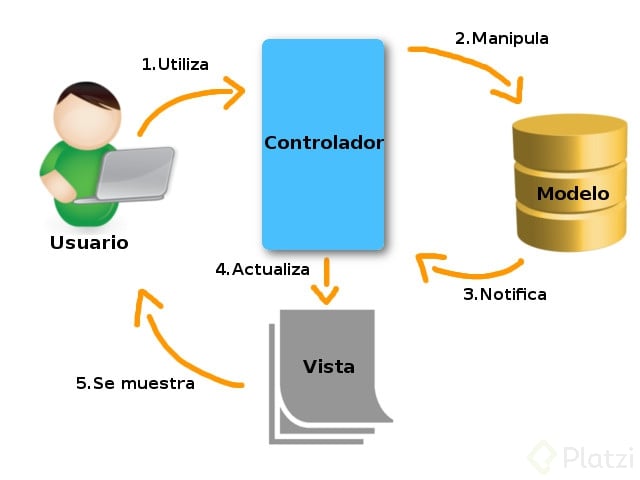
Patrón Modelo Vista Controlador
Modelo-vista-controlador (MVC) es un patrón de arquitectura de software, que separa los datos y la lógica de negocio de una aplicación de su representación y el módulo encargado de gestionar los eventos y las comunicaciones. Para ello MVC propone la construcción de tres componentes distintos que son el modelo, la vista y el controlador, es decir, por un lado define componentes para la representación de la información, y por otro lado para la interacción del usuario. Este patrón de arquitectura de software se basa en las ideas de reutilización de código y la separación de conceptos, características que buscan facilitar la tarea de desarrollo de aplicaciones y su posterior mantenimiento.
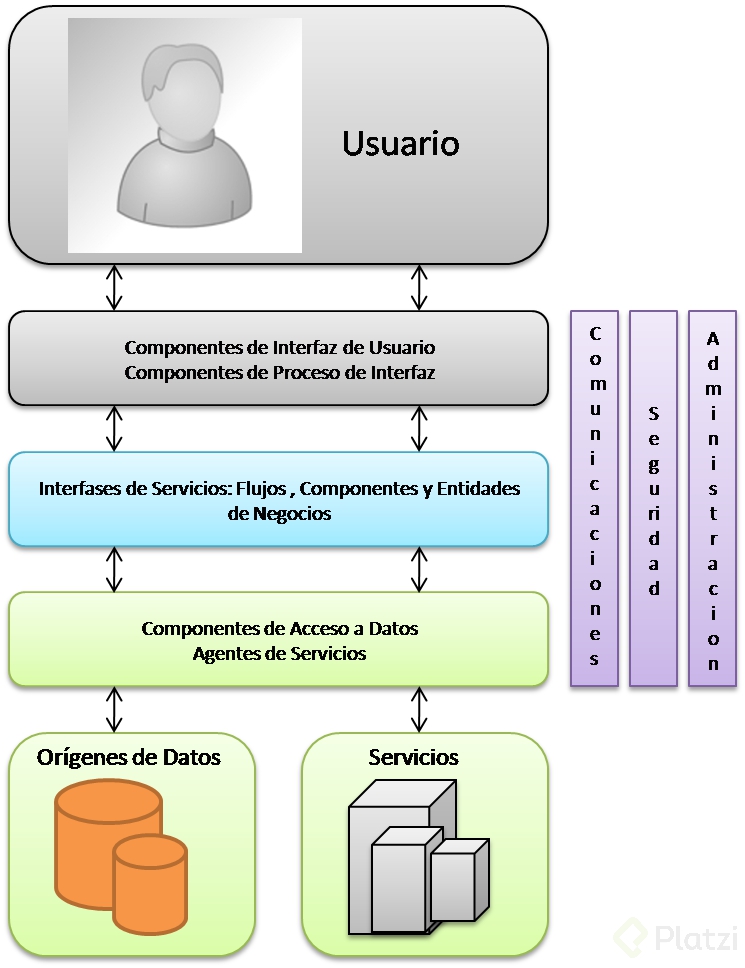
Patrones: Capas
Al pensar en un sistema en términos de capas, se imaginan los principales subsistemas de software ubicados de la misma forma que las capas de un pastel, donde cada capa descansa sobre la inferior.
A continuación se describen las tres capas principales de un patrón de arquitectura por capas:
-
Capa de Aplicación: Referente a la interacción entre el usuario y el software. Puede ser tan simple como un menú basado en líneas de comando o tan complejo como una aplicación basada en formas.
-
Capa de Lógica de Dominio: Esta capa contiene la funcionalidad que implementa la aplicación. Involucra cálculos basados en la información dada por el usuario y datos almacenados y validaciones. Controla la ejecución de la capa de acceso a datos y servicios externos.
-
Capa de Datos: Esta capa contiene la lógica de comunicación con otros sistemas que llevan a cabo tareas por la aplicación. Generalmente está representada por una base de datos, que es responsable por el almacenamiento persistente de información.
Patrones: Orientado a eventos / Provisión de eventos.
Los componentes van a publicar eventos a un bus común y esos componentes vas a estar suscritos a ese bus de eventos para recibir y transmitir eventos. En este caso, el bus de eventos es el único medio de comunicación entre componentes. Tendremos productores y consumidores de eventos. En general las arquitecturas orientadas a eventos suelen ser eventualmente consistentes (va a responder hasta que se distribuya en todos los componentes), sin embargo, será difícil testear ya que tendremos que usar sí o sí el bus de eventos y eso lo hace más complejo. Hay un concepto llamado EventSourcing esta va a tener guardados eventos que nos importan para entender el estado del sistema y se van a leer secuencialmente. Y esto nos permitirá saber el estado actual del sistema y también en cualquier momento del tiempo (potente para logs de auditoria, incluso recuperarse de ataques). Pero presenta varios desafíos como el consumo de recursos por una acumulación de estados. (Un ejemplo puede ser un registro de transacciones en una cuenta de banco).
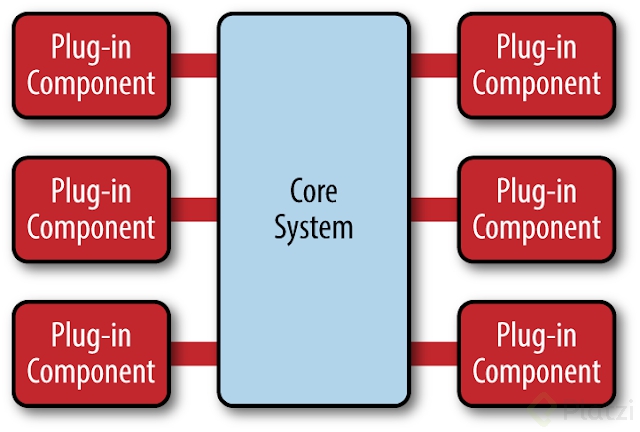
Patrones: Microkernel - Plug-ins
Esta arquitectura esta compuesta por 2 componentes, el sistema core y los modulos plug-in. El core contiene la minima funcionalidad y los módulos plug-in son componentes autónomos e independientes que contienen procesamiento especializado, características adicionales y código personalizado que está diseñado para mejorar o ampliar el sistema central para producir capacidades empresariales adicionales. Generalmente, los módulos plug-in deben ser independientes de otros módulos plug-in, pero ciertamente puede diseñar plug-ins que requieran que otros plug-ins estén presentes. De cualquier manera, es importante mantener la comunicación entre plug-ins a un mínimo para evitar problemas de dependencia.
Cuando leemos esto lo primero que se nos viene a la mente es OSGi, porque este estándar nació para darle soporte a este tipo de arquitecturas y el ejemplo más significativo de esta arquitectura sea eclipse.
Patrones: Comparte-nada
Compartir recursos entre diferentes componentes agrega mucha complejidad a la hora de decidir prioridades o disponibilidad del componente, entonces se busca crear que NO se tenga punto de unión entre componentes. Esta arquitectura es muy potente al procesar la información ya que al separar los componentes se puede enfocar en el fallo por que cada componente hace uso único de los recursos de dicho sistema.
Patrones: Microservicios
Son Componentes distribuidos donde cada componentes va a exponer una funcionalidad al resto del sistema. de esta forma modularizamos el sistema a traes de estos ser. independientes. Los clientes o los mismos servicios consumen estas funcionalidades entre ellos. Se debe tener comunicación entre ellos, de forma directa o indirecta (bus de eventos).
Patrones: CQRS
La segregación de responsabilidades de consultas y comandos (CQRS), Es un estilo de arquitectura que separa las operaciones de lectura de las operaciones de escritura. Los comandos, Deberían basarse en tareas, en lugar de centrarse en datos. (“Reservar habitación de hotel” y no “Establecer ReservationStatus en Reservado”). Los comandos se pueden colocar en una cola para un procesamiento asincrónico, en lugar de que se procesen de forma sincrónica. Las consultas, Nunca modifican la base de datos. Una consulta devuelve un DTO que no encapsula ningún conocimiento del dominio.
Patrones: Hexagonal - Puertos y adaptadores
Es un estilo de arquitectura que mueve el foco de un programador desde un plano más conceptual hacia la distinción entre el interior y el exterior del software. La parte interior son los casos prácticos y el modelo domain está construido sobre ello. La parte exterior es UI, base de datos, mensajería, etc. La conexión entre el interior y el exterior es mediante puertos, y su implementación equivalente se conocen como adaptadores. Por esta razón, este estilo de arquitectura se conoce habitualmente como Puertos y Adaptadores.
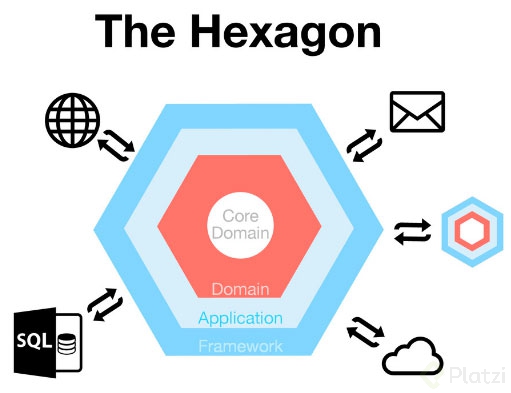
Patrones: Diseño orientado al dominio
Lo que hacemos es guiar nuestra aplicación y el diseño a través del uso del lenguaje común entre el negocio y el desarrollo. El obtener ese lenguaje del negocio y el poder hacer aplicaciones que estén concentradas en eso mucho más que lo que están concentradas en detalles técnicos. Va más allá de una sola aplicación, nos dice que busquemos modularizar nuestro sistema a través de los bounded context, que tratan de encontrar dónde el lenguaje cambia de sentido.
Herramientas y partes de un diseño: Tipos de conectores
La arquitectura está separada en dos partes fundamentales: Componentes: Son partes de nuestro sistema que cumplen una función específica Estos mismos componentes “modulares” pueden estar formados por más componentes, ya bien objetos o capas, que actuan como subcomponentes en su interior. La comunicación existente entre ellos se lleva a cabo por medio de conectores. Conectores: Estos no están asociados a un dominio específico y son independientes a la hora de su análisis, pudiendo un e-commerce o una red social el mismo tipo de conector.
Tipos de conectores:
-
Llamado a procedimiento: Invocan de un componente a otro componente y esperan una respuesta.
-
Enlace: Vinculan fuertemente un componente a otro, incluso para la compilación. Visto en lenguajes compilados, y en componentes que forman parte de un monolito
-
Evento: Permiten a un componente notificar un evento (que algo sucedió), y a otros componentes escuchar y reaccionar ante un evento.
-
Adaptador: Ayudan a compatibilizar la interfaz de un componente con la de otro componente
-
Acceso a datos: Nos ayudan a acceder a recursos compartidos de datos, como APIs, sistemas de archivos y bases de datos. Compatibiliza la interfaz del dato con la interfaz que espera el componente que estamos usando.
-
Flujo: Permite la recolección de datos en un flujo de información continuo por parte de otro componente que tiene intereses en obtener varios o todos los datos del flujo.
-
Arbitraje: Coordinan los permisos de acceso a un recurso entre componentes y deciden quien se encarga de distribuir dichos comportamientos.
-
Ej: Test A/B, teniendo varios componentes disponibles recibimos un pedido y se decide qué versión enviar para comparar diferentes atributos de calidad.
-
Distribuidor: Facilita la distribución de un mensaje a varios componentes a través de un solo conector.
Conectores: Llamado asincrónico / sincrónico. Modelo Cliente servidor.
Llamado asíncrono, un componente llama a otro y luego evalúan la respuesta cuándo la necesitan, no espera respuesta para poder continuar.
Llamado sincrónico, el emisor espera y no sigue ejecutando hasta que recibe resultado por parte del receptor.
Cliente / servidor: La comunicación va a ser siempre del cliente hacia el servidor, la diferencia en este caso con respecto a los llamados síncronos, es que el cliente no sabe exactamente quien es el servidor. Trata de la forma en que están distribuidos los componentes.
Conectores: Enrutador, difusión
Enrutador: Facilita la conexión entre un componente que emite un mensaje y un set de componentes que les interesa el mensaje.
Difusión: Dado un mensaje de un emisor lo difunde a muchos otros de componentes interesados.
##Conectores Pizarra, repositorio, colas, modelo PUBSUB
- Colas: Sirve cuando tenemos un productor tiene mas velocidad que un consumidor, para eso se agenda el procesamiento de cada mensaje, por lo que el consumidor va leyendo los mensajes a la velocidad que él se lo permite.
- Pizarra/repositorio: Está orientado a escribir o leer datos de un componente que funciona como base de datos.
- Modelo PUBSUB (Publicar-Suscribir): Permite mandar mensaje de un componente que publica eventos a otro que se suscriba a esos eventos, sin que estos componentes se conozcan entre sí.
Escenarios: Disponibilidad, detección, reparación
Escenario de disponibilidad. En este caso el estímulo es la falla, algo pasó que compromete la disponibilidad. vamos a ver las diferentes tácticas que podemos usar para trabajar con este posible escenario.
-
Detección, en este caso contamos con varias tácticas: la primera es la de o ping / eco. que se trata de como un componente envía un mensaje genérico a otro componente para saber si el otro componente esta disponible o no. o Latido, esta táctica es similar pero en vez de que haya interacción entre dos componentes, cada uno de estos envían una señal propia que indica que continua activo. o Excepciones, Un método para reconocer fallas es encontrar una excepción, que se produce cuando se reconoce una de las clases de fallas. El manejador de excepciones generalmente se ejecuta en el mismo proceso que introdujo la excepción.
-
Recuperación, como podemos estar listos para que si algo falla podamos recuperar rápidamente el sistema. o Votación, El algoritmo de votación puede ser “reglas de mayoría” o “componente preferido” o algún otro algoritmo. Este método se usa para corregir el funcionamiento defectuoso de algoritmos o fallas de un procesador y se usa a menudo en sistemas de control. o Redundancia activa, Cuando se produce una falla, el tiempo de inactividad de los sistemas que utilizan esta táctica suele ser de milisegundos, ya que la copia de seguridad es actual y el único momento de recuperación es el tiempo de conmutación. La redundancia activa a menudo se utiliza en una configuración cliente / servidor, como los sistemas de administración de bases de datos, donde las respuestas rápidas son necesarias incluso cuando ocurre una falla. o Redundancia pasiva, Un componente (el primario) responde a los eventos e informa a los otros componentes (los recursos) de las actualizaciones de estado que deben realizar. Cuando ocurre una falla, el sistema primero debe asegurarse de que el estado de la copia de seguridad sea lo suficientemente reciente antes de reanudar los servicios. o Repuesto, Una plataforma de computación de reserva en espera está configurada para reemplazar muchos componentes diferentes que fallaron. Debe reiniciarse a la configuración de software apropiada y debe tener su estado inicializado cuando ocurre una falla.
Escenarios: Reintroducción y prevención
- Reintroducción, Hay tácticas de reparación que se basan en la reintroducción de componentes. Cuando un componente redundante falla, puede reintroducirse después de haber sido corregido. Tales tácticas son el funcionamiento en la sombra, la resincronización del estado y la reversión.
o Modo sombra. Un componente previamente fallido puede ejecutarse en “modo sombra” durante un corto período de tiempo para asegurarse de que imita el comportamiento de los componentes en funcionamiento antes de restaurarlo al servicio. o Resincronización del estado. Las tácticas de redundancia pasiva y activa requieren que el componente que se está restaurando tenga su estado actualizado antes de su regreso al servicio. o Punto de control / retroceso. Un punto de control es una grabación de un estado consistente creado periódicamente o en respuesta a eventos específicos.
- Prevención, Las siguientes son algunas tácticas de prevención de fallas. o Remoción del servicio. Esta táctica elimina un componente del sistema de la operación para someterse a algunas actividades para evitar fallas anticipadas. Un ejemplo es reiniciar un componente para evitar que las pérdidas de memoria causen una falla. o Transacciones. Una transacción es la agrupación de varios pasos secuenciales, de modo que todo el paquete se puede deshacer a la vez. Las transacciones se utilizan para evitar que cualquier dato se vea afectado si falla un paso de un proceso y también para evitar colisiones entre varios subprocesos simultáneos que acceden a los mismos datos. o Monitor de proceso. Una vez que se ha detectado un error en un proceso, un proceso de supervisión puede eliminar el proceso no productivo y crear una nueva instancia del mismo, inicializado en un estado apropiado como en la táctica de repuesto.
Escenarios: Mantenibilidad
Mantenibilidad En este caso el estimulo es un pedido de cambio (llega un requerimiento y tenemos que cambiar el sistema).
Familias de tácticas:
- Confinar modificaciones. Las tácticas van a intentar trabajar sobre nuestros módulos para que cada cambio que nos pidan esté confinado a sólo un módulo. Cuando logramos esto logramos que las dependencias entre módulos sean más ligeras y el cambio que nos proponen no afecte a muchas partes del sistema. > a) Coherencia semántica. Habla de la relación entre las responsabilidades de los módulos. Hablamos de acoplamiento y cohesión. Si logramos encontrar la cohesión en un módulo entonces vamos a poder hacer que ese módulo sea más mantenible. De lo contrario es posible que ese módulo cambie por diferentes razones.
Abstraer servicios comunes. Cuando encontramos que la aplicación tiene servicios más genéricos de no necesario podemos abstraerlos a un punto común y que las dependencias vayan de los módulos cohesivos a un servicio o modulo externo.
- b) Generalizar. Al generalizar un módulo podemos separar lo específico de lo genérico.
- c) Limitar opciones disponibles. Limitar el rango de modificación nos ayuda a que sea más mantenible.
- d) Anticipar cambios. Prepararnos para algún cambio que nosotros mismo sepamos que se deberá de dar en el futuro tomando en cuenta una estrategia sobre como incorporar el nuevo cambio. Los patrones de diseño suelen estar orientados a esto (Patrón estrategia).
-
Prevenir efectos domino. Trabaja estrictamente con las dependencias, es decir cuando podemos detectar que un cambio generaría problemas en otros módulos o dependencias.
-
Diferir enlace. Como podemos hacer para que un cambio en el código no requiera desplegar toda la aplicación..
Escenarios: Prevenir efectos dominó y diferir enlace
Prevenir efectos dominó. Trabaja estrictamente con las dependencias. Es decir, cuándo podemos detectar que un cambio generaría problemas en otros módulos u otras dependencias.
- Ocultar información. Cualquier módulo u objeto que diseñemos, tenga la capacidad de ocultar cierta parte de la información para que los agentes externos no dependan de esa información puntual sino de una interfaz clara que no puedan cambiar por más que la información cambie. De esta forma podemos garantizar que, si el cambio de la información es importante, los dependientes no necesiten cambiar porque están pasando por una interfaz que no cambió. *** Mantener la interfaz**. Si tengo un servicio que hace algo, la dependencia a ese servicio va a ser a través de una interfaz clara, de lo contrario cualquier acción cuándo cambie puede poner en riesgo el módulo.
- Restringir comunicación. Para generar sistemas que estén acoplados de forma ligeras, en vez de conocer las dependencias de tus dependencias, siempre te limites a tus dependencias directas, de esta forma cualquier cambio en la forma que tus dependencias trabajan no afecta al módulo en el que estás trabajando.
- Intermediarios. Hablamos de un punto dónde podamos compatibilizar a un módulo con otro y si dejan de ser compatibles, estos intermediarios puedan servir como punto de compatibilidad.
Diferir enlace. Habla sobre cómo podemos hacer para que un cambio en nuestro código no requiera desplegar toda la aplicación completa.
- Registro en ejecución. Cuando un módulo o servicio depende de otro, si dependen fuertemente van a requerir estar compilados juntos. Si nosotros podemos diferir esa compilación y que se registre un servicio en momento de ejecución, es decir que se ponga disponible a sus dependencias en el momento de ejecución, podemos hacer que estos servicios se puedan desplegar independientemente.
- Archivos de configuración. Van a servir para en momento de ejecución saber cómo conectar varias partes. Es imprescindible que nuestros módulos dependan de interfaces y no de implementaciones específicas.
- Polimorfismos. Un objeto pueda comportarse de forma diferente en base a su estado. A través del polimorfismo podemos postergar la forma en que se resuelve un problema dependiendo de qué instancia del objeto será.
- Reemplazo de componentes. Tener la capacidad de desplegar un componente y luego desplegar su reemplazo, o quizás otro componente que respete esa interfaz, y que todo el resto de nuestra aplicación no necesite cambiar.
- Adherir a protocolos. Nos permite tener un protocolo claro entre dos módulos y no necesitar saber la instancia específica o el tipo específico de un módulo.
Escenarios: Eficiencia de ejecución
Eficiencia de ejecución
En el caso de eficiencia de ejecución vamos a tener eventos ingresando a nuestro sistema como estímulo y luego vamos a trabajar sobre las tácticas para controlar esta eficiencia para que la respuesta sea dentro del tiempo esperado.
Demanda de recursos. Trata sobre cuándo entra un evento, cómo hacemos para que ese evento tenga los recursos disponibles y cuánto de esos recursos necesita. • Mejorar la eficiencia computacional. Podemos analizar nuestros algoritmos y podemos analizar nuestro procedimiento para encontrar cuáles son los puntos en dónde no estamos siendo eficientes. • Reducir sobrecarga. Habla sobre cuántos pasos o qué acciones estamos tomando para una misma tarea o responder a un mismo evento. • Manejar tasa de eventos. Cuántos eventos vamos a emitir a un componente específico y si es necesario ser tan fino en estos eventos. Si podemos reducir esa tasa de eventos podemos optimizar esa comunicación. • Frecuencia de muestreo. Si yo sí estoy recibiendo todo este stream, cómo puedo hacer para decidir procesar esos eventos en una forma grupal, entonces en lugar de hacer una tarea por evento puedo hacer una tarea cada cierta cantidad de tiempo y agrupar todos los eventos en una tarea única puedo hacer mejor uso de los recursos procesando una sola vez un grupo de eventos.
Gestión de recursos. Cómo ponemos disponibles más o menos recursos y cómo hacemos para que estén cuándo se le necesitan. • Concurrencia. Trabajamos sobre cómo paralelizar nuestro proceso para que se pueda responder en menor tiempo usando recursos de forma paralela o en menor tiempo. • Réplicas. Cómo podemos duplicar el procesamiento o los datos para hacer más accesibles estos recursos a nuestro proceso. • Aumentar recursos. El poder medir y decidir cuándo crecer la cantidad de recursos que tenemos disponibles.
Arbitraje de recursos. En caso de conflicto, en caso de haber múltiples eventos necesitando los mismos recursos cómo decidimos cuáles tienen prioridad. • Políticas de planificación de tareas. Yo puedo decidir que cada recurso tiene que responder en el momento entonces tiene que tener un acceso sincrónico, un acceso prioritario a cada uno de esos recursos o puede postergar tareas y agendarlas para que se hagan en un momento futuro. Incluso puedo priorizar esos pedidos paralelos y decidir si un pedido es más importante que otro o el orden en que se van a resolver.
Escenarios: Seguridad
Seguridad Nuestro estimulo de entrada es un ataque, nuestras tácticas para controlar la seguridad y tener como resultado la detección, resistencia o recuperación en nuestro sistema. Tendremos tres familias:
Detectar ataques: Van a tratar de identificar que el estado actual de la aplicación está bajo un ataque, puede ser por medio de sensores.
-Detectores de intrusos: Ayuda a tener implementaciones para saber cuándo se está usando de manera no apropiada. Levantará alertas para tomar decisiones sobre nuestro sistema (pueden ser complejas, automatizadas o simples). Podremos ir descendiendo en niveles cuanto más complejo sea.
Recuperación de ataques: Trata de tener bases o tácticas para regresar a un estado basal y también poder comprender cuáles fueron las acciones del atacante para poder evitarlas a futuro
-Restauración: Cómo hacemos para entender nuestros estados del sistema y entender qué pasa con mi sistema. Es muy similar a la estrategia de Disponibilidad (estados conocidos, estados diferentes para comparar) -Identificación: Saber qué específicamente hizo el atacante. La traza de auditoria sirve para que cuando detectamos un atacante tengamos todo el rastro de nuestro usuario y poder restablecer mi sistema a ese punto basal, ignorando lo que hizo el atacante
Resistencia de ataques: Va a tratar que el atacante no tenga éxito.
-Autenticación: Cómo sabemos que el usuario es quien realmente die ser (Contraseñas, datos biométricos, RS, etc.) -Autorización: Saber quién es y qué puede o no hacer esa persona (Roles entre sistemas) -Confidencialidad de datos: Cómo garantizamos que el dato sea visto por quien debe verlo (encriptación) -Integridad: Cómo garantizo que el mensaje es íntegro, es decir, cómo el emisor lo envió (Hashes para comprobar información) -Limitar exposición: Si un atacante entra podemos determinar que este no pueda (por lo menos) entrar a consultar la información más sensible del usuario. Lo podemos hacer separando información (separar info sensible de info “normal”). -Limitar acceso: Entender cuáles son los vectores de acceso y restringir lo menor posible esos accesos que pueden ser puntos iniciales de penetración (Puertos de red: 8080, SSH, etc.)
Escenarios: Capacidad de prueba
Capacidad de prueba: Nuestro estimulo de entrada será una nueva funcionalidad para implementar, tendremos técnicas para controlar la capacidad de prueba y nuestro resultado será detectar fallas para repararla y volver a iterar. Tendremos dos grandes familias, entradas/salidas y monitoreo que tiene en cuenta más que nada la ejecución.
Entrada/Salida: Cómo hacer para dado un estímulo de entrada, evaluar una salida.
-Captura y reproducción: Sirve para, en un escenario de comunicación, grabarla para poder usar esa comunicación en un test de prueba. De esta forma podemos garantizar que el uso normal está cubierto por un test y sabemos qué es lo que tiene que dar mi sistema. Es muy útil cuando queremos trabajar con sistemas externos. VCR (librería: video cam recording) es una herramienta muy útil aquí. -Separar la interfaz de la implementación: De esta forma podemos evaluar si la implementación está recibiendo lo que se espera. Podemos hacer pruebas con diferentes implementaciones. -Acceso exclusivo para pruebas: Trata sobre partes de la aplicación que no podemos funcionar desde fuera de la aplicación, para esto es posible que tenga que escribir código específico para el contexto de test, es importante garantizar que no llegue a ambientes productivos. Son útiles para probar microservicios
Monitoreo: Tendrá en cuenta la ejecución y que se está ejecutando exitosamente
Monitoreo interno: Significa incorporar a la misma aplicación funcionalidades que nos permiten tener información de lo que se está ejecutando para mantener el control de lo que está consumiendo cada aplicación.
Escenarios: Usabilidad
Usabilidad
Va a tener como estímulo el pedido de usuario y luego vamos a ver con qué tácticas contamos para a través del control de la usabilidad poder brindar información y asistencia al usuario.
Separar la interfaz de usuario. Que cualquier otro artefacto que haya dentro de nuestra aplicación, cualquier módulo que hagamos, esté separado de la interfaz de usuario. De esta forma podemos iterar y podemos revisar la cantidad de veces que sea necesario la interfaz de usuario para poder trabajar constantemente sobre la usabilidad de lo que estamos proponiendo, y esto puede trabajarse independientemente de la lógica de negocios o de la estructura de datos. • Cancelar. Permite a un usuario dada una acción previa el poder arrepentirse. • Deshacer. Volver para atrás al estado anterior le permite al usuario re evaluar lo que va a hacer y luego tomar mejores decisiones. • Agregación. Tiene que ver con entender cuándo las funcionalidades que estamos presentando al usuario en realidad deberían estar agrupadas. • Múltiples vistas. Refiere a cómo hacemos para que el usuario tenga solamente la información necesaria para poder hacer sus acciones de la forma más eficiente posible.
Iniciativas del usuario.
Iniciativas del sistema. La idea es poder entender del lado del sistema cuál es el estado actual de la aplicación. • Modelo del usuario. Esto significa que del lado del sistema entendamos cuál es el estado actual del usuario para poder empezar una iniciativa, es decir, enviar un mensaje del lado del sistema y que tenga sentido con lo que está viendo. • Modelo del sistema. Implica qué sabemos de nosotros mismos, qué sabemos cómo aplicación de lo que está pasando en este momento. • Modelo de la tarea. Tiene que ver con cuánto entiende el sistema de la tarea que está realizando el usuario.
Validar las decisiones de diseño: Arquitectura en evolución
¿Cómo validamos todas estas desiciones de diseño y de arquitectura que estamos tomando?.
La validación es muy compleja y en general depende del contexto en el que estamos trabajando.
ATAM - para analizar las estrategias y desiciones vemos como los objetivos del negocio, los tributos de calidad y los escenarios se combinan con la arquitectura, las estrategias de arquitectura y las desiciones de arquitectura. A partir del entendimiento de los puntos mas sensibles y cuáles son o no son los riesgos.
Cómo comunicar la arquitectura: Vistas y Puntos de vista
Arquitectura restrictiva Restringe las decisiones que quedan por tomar (por ejemplo cuándo se le da a un equipo de desarrollo) Arquitectura descriptiva Documenta las decisiones tomadas y describe el estado actual del sistema, restricciones del pasado más las actuales
El arquitecto va a trabajar con diferentes personas para garantizar que la arquitectura se ejecute correctamente:
Analista: Negociación de requerimientos Operaciones: Cálculo de recursos Desarrolladores: Restricciones y libertades para desarrollar Diseñadores de productos dependientes (Product Managers): Definición de interoperabilidad. Comunicación entre productos. Requerimientos de comunicación como una API. Sincronizar equipos Gestores de proyecto (Project Manager): Gestión de equipos y recursos Equipo de calidad (QA): Métricas y conformidad
Documentación vs implementación
Modelo de Arquitectura: Se compone de elementos tales como módulos, componentes, conetores, restricciones, estilo, patrones, atributos de calidad.
Código fuente: Hace referencia a paquetes, clases, interfaces, métodos, funciones, parámetros, tipos.
La “fuente de la verdad” va a ser el código y no el documento de arquitectura. Se deben buscar estrategias para sincronizar el estado actual del código con el documento de arquitectura.
Las posibles estrategias son las siguientes:
-Ignorar la divergencia: Aplica cuando el equipo de trabajo es pequeño y mientras todos conozcan la difernecia entre el modelo de la arquitecura y la implementación consiste en mantener el documento de arquitectura tal y como se encuentra concebido, sabiendo que es lo que hace falta completar y que está en el código fuente.
-Modelado Ad-hoc: Se tiene una idea de la diferencia entre el modelado y el código fuente, de tal forma que se puede enunciar el modelo de arquitectura a pesar de que no se encuentra en el documento.
-Modelos de alto nivel: Se puede seguir modelando la arquitectura con modelos de alto nivel que tienden a cambiar menos y por ende, son más baratos.
-Sincronización en hitos del ciclo de vida: Consiste en actualizar el modelo de arquitectura en algún punto del ciclo de vida de la aplicación. Permite versionar el modelo de arquitectura y saber en cada momento del proyecto cual era el estado del modelo de arquitectura.
-Sincronizar en una crisis: Actualizar el modelo de arquitectura cuando dentro del desarrollo, el codigo fuente riñe contra alguna definición plasmada en el modelo arquitectónico.
-Sincronización constante: Es la estrategia mas obvia, pero la menos eficiente de todas porque es la mas costosa y mas complicada de ejecutar porque es bastante complicado tener el modelo actualizado contra el código fuente.