Linked Lists - YashasKamath/IECSE-Summer-Bootcamp-2022 GitHub Wiki
A linked list is a sequence of data structures which are connected via links i.e Pointers. Each element of the list contains the data, item and a pointer/link to the next element, next. It can be visualized as a chain of nodes where every node points to the next node.
First, let's try and understand some common terms used with linked lists -
- Node: an item in a linked list is referred to as a Node. Each node contains a piece of list data and the location of the next node.
- Link of a node: The location of the next node is referred to as a Link of the node.
- Head of a Linked List: The first node in a linked list.
- Head Pointer: The pointer that points to the head node in a linked list.
While both arrays and linked lists might serve similar purposes but the basic difference is that, in an array, the space allocated has to be continuous while the same cannot be said for a linked list. In a linked list you create nodes that may have addresses that are quite distant from each other, but as every node contains an address to the next node, we can access the whole linked list by only knowing the address of the head node, that is what our head pointer does.
Also, certain operations are faster in a linked list when compared to an array.
Before we start with the operations like insertion and deletion in a linked list we will take a look at the basic structure of a linked list.
When we think about it, a linked list is just a collection of nodes where every node contains the data that it is supposed to hold and the memory location or the address of the next node that it is connected to. Hence the insertion and creation of a linked list is done as follows.
#include<iostream>
using namespace std;
struct Node
{
int data;
Node* next;
};
class linkedList
{
private:
Node *head;
public:
linkedList()
{
head=NULL;
}
void addNode(int data)
{
Node* node=new Node;
node->data=data;
node->next=NULL;
if(!head)
{
head=node;
}
else
{
Node *temp=head;
while(temp->next)
{
temp=temp->next;
}
temp->next=node;
}
return;
}
void print()
{
Node* temp=head;
while(temp)
{
cout<<temp->data<<" ";
temp=temp->next;
}
cout<<endl;
}
};
int main()
{
linkedList ll;
ll.addNode(1);
ll.addNode(2);
ll.addNode(3);
ll.print();
}
Also, as we can see here the time taken for insertion is O(n), We can also reduce it by keeping another pointer with us, tail pointer.
NOTE: '<-' in algorithmic notation means '='. For example 'a<-3' means 'a=3'.
The algorithm for adding a node where we have both head and tail pointers would be -
void addNode(int data)
{
//create a new node with data call it node
(tail->next)<-node
tail<-tail->next
}
As here, the insertion happens in O(1). Now, try and implement this on your own.
Now, this is where we get a major advantage of using a linked list over an array. Suppose, we had to delete an element in an array of n elements from the ith position. What would we have to do? We'd have to go to the ith position and move all the other n-i elements on it's right by one position each. So this would always take O(n).
Whereas in a linked list, what you can do is:
void delete(int i)
{
j<-0
temp<-head
while(j<i-1) //0 based indexing
{
temp<-(temp->next)
}
(temp->next)<-(temp->next->next)
return
}
Here what you do is change the address that the (i-1)th node points to, to point to the next to next element.
As a result, we lose what used to be our ith node, we could also free the space for the node.
Here the time complexity becomes O(i), which even though is still linear is much faster than what it would be in a normal array, especially when i is small.
Once you lose the pointer that points to a node in a linked list, there is no way of accessing that node anymore.
Circular linked list is a variation of the linked list structure where the next pointer of the last node points back to the first node, hence none of the pointer contain NULL value.
Doubly linked list is a variartion of the linked list structure where each node has an extra pointer, the previous pointer, which points to the previous link. The previous pointer of the first node is NULL and the next pointer of the last node is NULL. Hence the structure of the node looks like this:
struct Node
{
int data;
Node* next;
Node* prev;
};
Say we have a pointer to our current node as Node* curr, then
curr -> next points to the node after the current node.
curr -> prev points to the node before the current node.
Circular doubly linked list is a variation of the linked list data structure where each node in circular linked list has a prev pointer to point to the previous node and a next pointer to point to the next node. Since the list is circular , the next pointer of the last node points to the first node and the prev pointer of the first node points to the last node. Hence , none of pointers contains NULL value. Thus, each node contains three fields, a data field a pointer pointing to previous node and a pointer pointing to next node
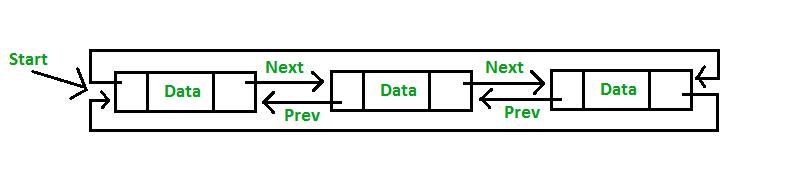
Following are advantages and disadvantages of circular doubly linked list: Advantages: • List can be traversed from both the directions i.e. from head to tail or from tail to head. • Jumping from head to tail or from tail to head is done in constant time O(1). Disadvantages • It takes slightly extra memory in each node to accommodate previous pointer. • Lots of pointers involved while implementing or doing operations on a list. So, pointers should be handled carefully otherwise data of the list may get lost.
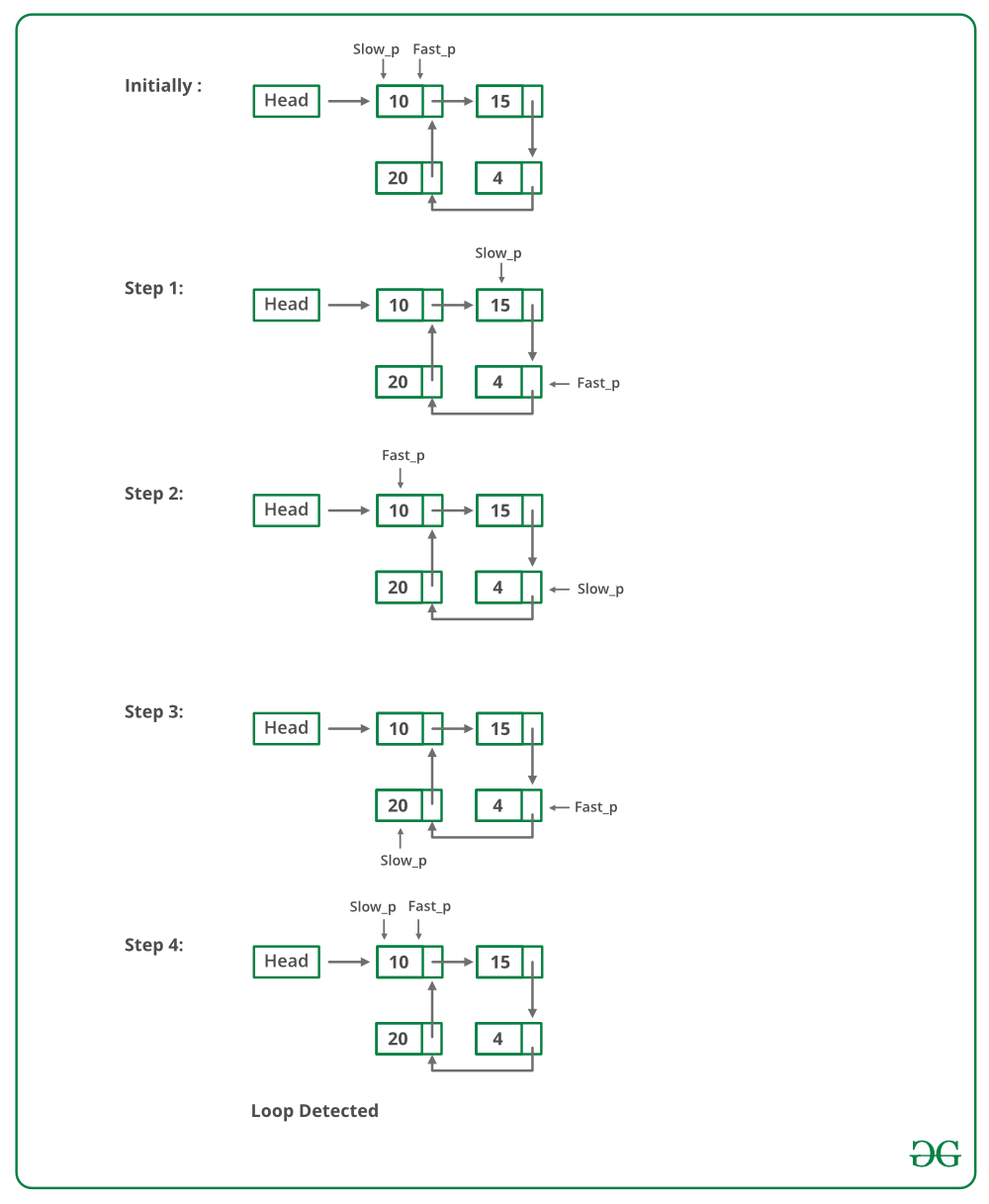
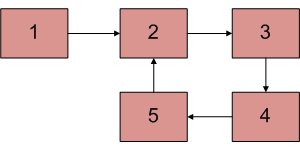
Given a linked list, check if the linked list has loop(cycle) or not. Below diagram shows a linked list with a loop.
The fastest method to do so is by using Floyd's algorithm:
- Traverse linked list using two pointers.
- Move one pointer(slow_p) by one and another pointer(fast_p) by two.
- If these pointers meet at the same node then there is a loop. If pointers do not meet then linked list doesn’t have a loop