谢宇翔 - XLab-Tongji/RCAToolbox GitHub Wiki
K8s基础概念
核心
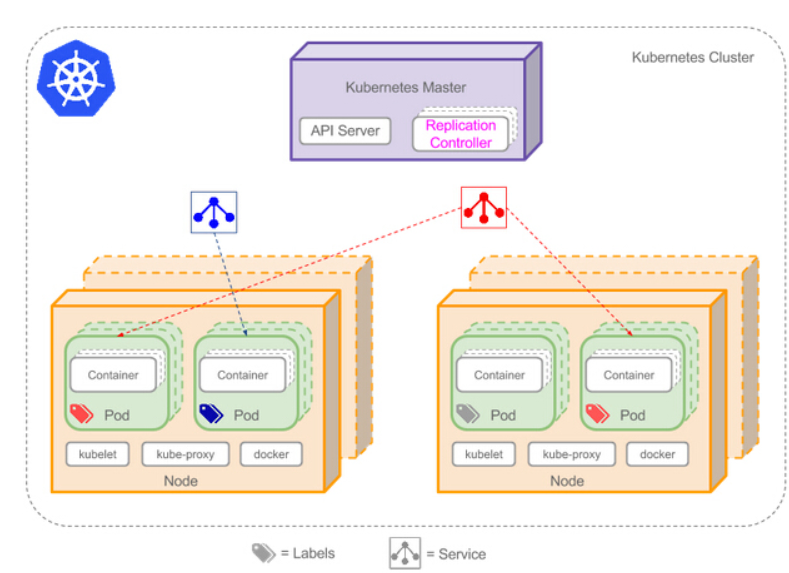
- Node
Node作为集群中的工作节点,运行真正的应用程序;Node上运行着Kubernetes的Kubelet、kube-proxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启、销毁、以及实现软件模式的负载均衡。
- Pod
Pod是Kubernetes最基本的操作单元,包含一个或多个紧密相关的容器,一个Pod可以被一个容器化的环境看作应用层的“逻辑宿主机”;一个Pod中的多个容器应用通常是紧密耦合的,Pod在Node上被创建、启动或者销毁;每个Pod里运行着一个特殊的被称之为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此他们之间通信和数据交换更为高.
- Service
负责为一组Pod组成的集群提供服务;
一个Service可以看作一组提供相同服务的Pod的对外访问接口,Service作用于哪些Pod是通过Label Selector来定义的。
- Volume
Volume是Pod中能够被多个容器访问的共享目录。
- Label
识别标志
- RC(Replication Controller)
Kubernetes通过RC中定义的Lable筛选出对应的Pod实例,并实时监控其状态和数量,如果实例数量少于定义的副本数量(Replicas),则会根据RC中定义的Pod模板来创建一个新的Pod,然后将此Pod调度到合适的Node上启动运行,直到Pod实例数量达到预定目标。
总体架构
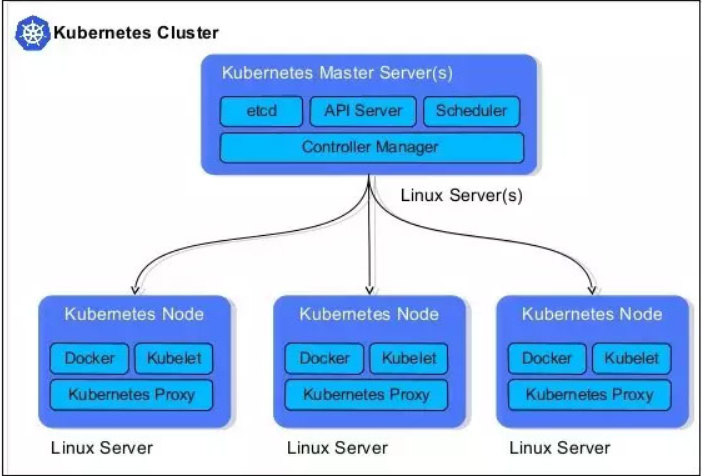
Kubernetes将集群中的机器划分为一个Master节点和一群工作节点(Node)。其中,Master节点上运行着集群管理相关的一组进程etcd、API Server、Controller Manager、Scheduler,后三个组件构成了Kubernetes的总控中心,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,并且全都是自动完成。在每个Node上运行Kubelet、Proxy、Docker daemon三个组件,负责对本节点上的Pod的生命周期进行管理,以及实现服务代理的功能。
- etcd:用于持久化存储集群中所有的资源对象,如Node、Service、Pod、RC、Namespace等,API Server可以写etcd
- API Server:提供了资源对象的唯一操作入口,其他所有组件都必须通过它提供的API来操作资源数据。(入口)
- Controller Manager:集群内部的管理控制中心,其主要目的是实现Kubernetes集群的故障检测和恢复的自动化工作
- Scheduler:集群中的调度器,负责Pod在集群节点中的调度分配。
- Proxy:实现了Service的代理与软件模式的负载均衡器
- 我觉得网上讲的流程很清楚:
通过Kubectl提交一个创建RC的请求,该请求通过API Server被写入etcd中,此时Controller Manager通过API Server的监听资源变化的接口监听到这个RC事件,分析之后,发现当前集群中还没有它所对应的Pod实例,于是根据RC里的Pod模板定义生成一个Pod对象,通过API Server写入etcd,接下来,此事件被Scheduler发现,它立即执行一个复杂的调度流程,为这个新Pod选定一个落户的Node,然后通过API Server讲这一结果写入到etcd中,随后,目标Node上运行的Kubelet进程通过API Server监测到这个“新生的”Pod,并按照它的定义,启动该Pod并任劳任怨地负责它的下半生,直到Pod的生命结束。
随后,我们通过Kubectl提交一个新的映射到该Pod的Service的创建请求,Controller Manager会通过Label标签查询到相关联的Pod实例,然后生成Service的Endpoints信息,并通过API Server写入到etcd中,接下来,所有Node上运行的Proxy进程通过API Server查询并监听Service对象与其对应的Endpoints信息,建立一个软件方式的负载均衡器来实现Service访问到后端Pod的流量转发功能。(这里不太清楚)
云服务、微服务概念
学长上次开会讲清楚了
因果推断
因果推断的核心思想在于反事实推理,即在我们观测到X和Y的情况下,推理如果当时没有做X,Y'是什么。
因果推断的目的是要判断因果性,即计算因果效应(有无X的情况下Y值的变化量)。在进行反事实推理后,可得出因果效应e = |Y - Y'|,进而判断因果性。
实际上,对于一个对象,我们永远只能观察到Y和Y'的其中一个,因果推断所做的就是从已有数据中估计因果效应,所以我认为因果推断的本质是,对因果效应的估计。
https://blog.csdn.net/qq_36153312/article/details/102781633
DyCause论文
-
众包方案(整合信息)
DyCause通过将内核API调用记录到本地日志中,在每个应用程序中作为API代理工作;并且每个代理都可共享本地记录,解决非对称诊断信息的挑战;DyCause将日志本地聚合并插值到许多1Hz的时间序列中,表示每个请求的内核服务的性能指标。
-
异常分析(找error)
SPOT算法找出有异常的区间
-
新的统计算法和动态因果分析曲线模型---发现时变因果关系(找原因链)
在格兰杰因果关系检验的基础上优化,原来是静态的,之后改为动态的,将时间区间改为动态的,利用剪枝策略,获得更加精确地原因链。
-
将独立的曲线众包图融合为直观的图形结构(直观化)
将原因链直观化
-
根本原因追溯(找源头)
向后BFS,用自创的算法根据可能链寻找根本原因
-
优点
对比市面上的优秀的算法,DyCause有着相比较下突出的优点。
代码
只是粗略看了看,不能很深入的理解