Classification - WorldBank-Transport/tz-data-cleaning GitHub Wiki
Sometimes you may have a dataset containing a collection of different types of entries without a field that specifies type of each entry. In this case you may classify the entries based on another field or combination of multiple fields available in the dataset. For example in a dataset which contains a collection of different type of educational institutions (primary schools, secondary schools, universities, nursery schools and more) you may identify the type an institution based on its name.
Nomenclature cleaning
In classifying entries in a dataset based on a certain field, it may be useful to have a uniform naming pattern for that field. If origininal field doesn't have a uniform naming pattern you may have to harmonize it before using it for classification. For example if you have mixed use of abbreviations and full names or multiple abbreviation formats for the same thing it is usually better transform the values to a common pattern.
Openrefine is a powerful tools that can be used for cleaning messy tabular datasets. For basic usage instruction and more information about Openrefine you can check on the Openrefine's documentation or other resources available online.
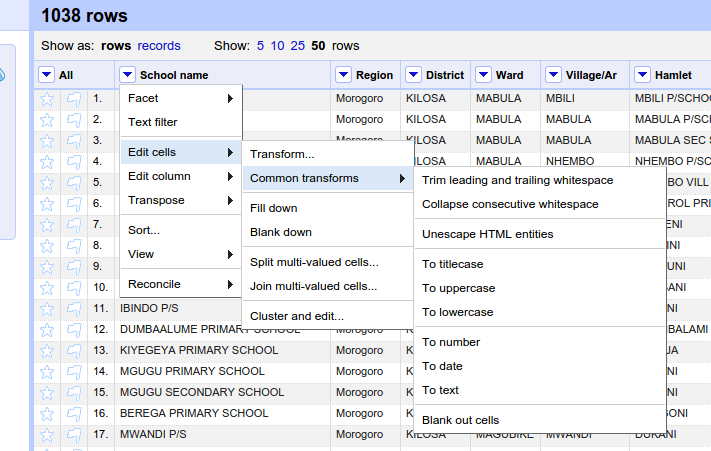
Openrefine provides functions to trim leading and trailing whitespace, collapse consecutive whitespace, convert entries to a uniform case, perform other custom or complex transformations and much more therefore you them to create a uniform naming pattern for your dataset.
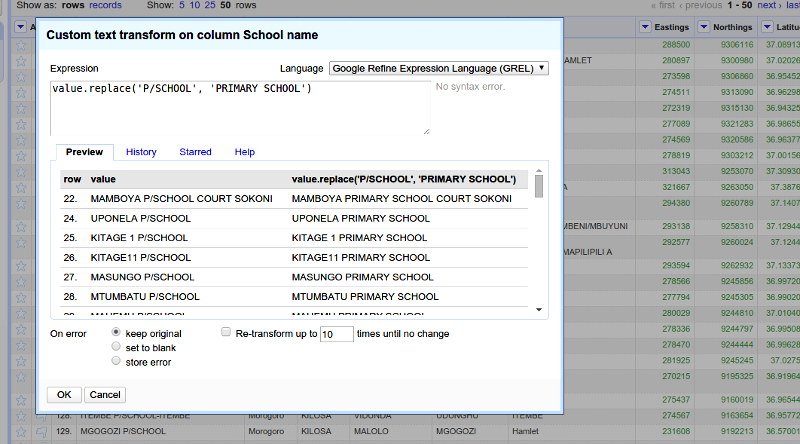
For example in order to perform cell transformation from one naming pattern to another
- click an arrow which on the left of the column name that you want to transformation and you will see a drop-down menu
- Hover the pointer to the
Edit cellsoption and you will see another sub-menu - Click on
Transformoption and a pop up will be opened which will allow you to enter an expression to transform all cells based on that expression. For example an expressionvalue.replace('P/SCHOOL', 'PRIMARY SCHOOL')will transform text 'P/SCHOOL' to 'PRIMARY SCHOOL' for each cell in a column. - Click
OKto Apply the changes.
Classifying entries based on a field using Openrefine
Example: Classifying primary and secondary schools based on school name
In a dataset containing a collection of educational institutions (primary schools and secondary schools) you can identify the type of an institution based institution name.
- By clicking an arrow on the left column name go to
school name>edit column>add column based on this column. - Enter the the new column name, example school type
- Put an expression
if(value.contains('PRIMARY SCHOOL'), 'primary', 'secondary') - Click
OK
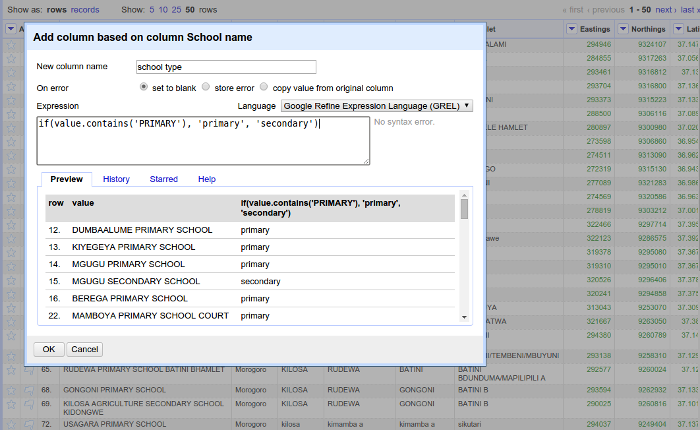
This will create a new column with a value of either primary or secondary based on the value of school name.
The general syntax of an 'if' expression used in this case is
if (test_condition, true_result, false_result)
An expression if(value.contains('PRIMARY SCHOOL'), 'primary', 'secondary') will return a value of 'primary' if the school name contains text 'PRIMARY SCHOOL' it will return 'secondary school'.
In this way you can have a classified dataset
Sample custom script for classifying schools
You can also use custom scripts to classify datasets based on a certain field.
A tz-data-cleaning repository contains a Python script called categorize_schools.py that can be used to classify schools in csv format based on their names.
You can use this script by running
python categorize_schools.py <path/to/input-1.csv>
So if the dataset is named schools_data.scv you will have to run python categorize_schools_data.py schools_data.csv which will produce an output file Schools/schools_data.csv
For this script to work you need have python installed in your system and your dataset must contain a filed called name or School or Particular .