03. Processing Source Code Into A Graph - VitalyRomanov/method-embedding GitHub Wiki
Source Code Data Format
Source code should be structured in the following way
source_code_data
│
└───package1
│ │───source_file_1.py
│ │───source_file_2.py
│ └───subfolder_if_needed
│ │───source_file_3.py
│ └───source_file_4.py
│
└───package2
│───source_file_1.py
└───source_file_2.py
An example of source code data can be found in this repository method-embedding\res\python_testdata\example_code. A package should contain self-sufficient code with its dependencies. Unmet dependencies will be labeled as non-indexed symbol.
Indexing with Docker
To create dataset need to first perform indexing with Sourcetrail. The easiest way to do this is with a docker container
docker run -it -v "/full/path/to/data/folder":/dataset mortiv16/sourcetrail_indexer
Indexing manually with Sourcetrail (alternative option)
This option works onl on Linux. Download a release from Github repo (latest tested version is 2020.1.117). Add Sourcetrail location to PATH
echo 'export PATH=/path/to/Sourcetrail_2020_1_117:$PATH' >> ~/.bashrc
SCT=/path/to/SourceCodeTool_repository
SOURCE_CODE=/path/to/source/code
DATASET_OUTPUT=/path/to/dataset/output
cd $SOURCE_CODE
echo "example\nexample2" > list_of_packages.txt
bash -i $SCT/scripts/data_collection/process_folders.sh < list_of_packages.txt
bash -i $SCT/scripts/data_extraction/process_sourcetrail.sh $SOURCE_CODE
Creating graph
Need to provide a sentencepiece model for subtokenization. Model trained on CodeSearchNet can be downloaded here.
SCT=/path/to/SourceCodeTool_repository
SOURCE_CODE=/path/to/source/code/indexed/with/sourcetrail
DATASET_OUTPUT=/path/to/dataset/output
python $SCT/SourceCodeTools/code/data/sourcetrail/DatasetCreator2.py --bpe_tokenizer sentencepiece_bpe.model --track_offsets --do_extraction $SOURCE_CODE $DATASET_OUTPUT
Creating graph without Sourcetrail index
There is an option to create a graph without creating a Soutrcetrail index. You need to create a DataFrame that stores source code. An example of needed format can be created with
python SourceCodeTools/code/data/ast_graph/build_ast_graph.py path_to_input path_to_output --create_test_data
The output is a DataFrame pickle (written with pandas.to_pickle). path_to_input will be ignored when --create_test_data is set. The output DataFrame has header
id,filecontent,package
Package and id are used to uniquely identify source code. No id can be repeated inside one package. The column package must be present.
Convert source code into a graph by running
python SourceCodeTools/code/data/ast_graph/build_ast_graph.py path_to_input path_to_output --bpe_tokenizer path/to/tokenizer/sentencepiece.model
When bpe_tokenizer is provided, names are subtokenized. All names and subwords are shared between different snippets of code. Files common_nodes.bz2, common_edges.bz2, common_filecontent.bz2, and common_offsets.bz2 will be created in output directory.
Given a small example with two snippets of code
test_code = pd.DataFrame.from_records([
{"id": 1, "filecontent": "import numpy\nnumpy.array([1,2,3])", "package": "any_name_1"},
{"id": 2, "filecontent": "from numpy import *\n", "package": "can use the same name here any_name_1"},
])
the output graph is
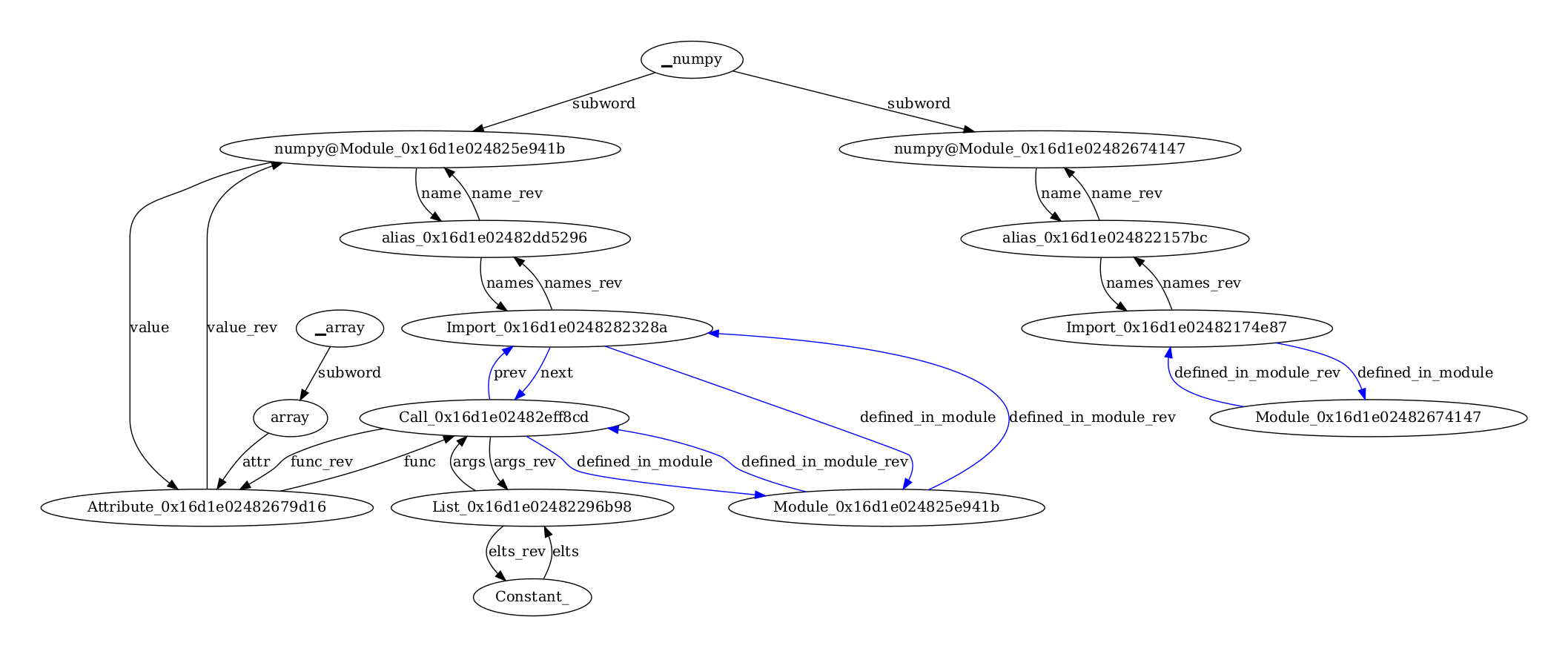 Note that the common subword
Note that the common subword numpy is shared between two snippets of code.