Semana 13 - Vicvargas/PortafolioDigital GitHub Wiki
Martes 15/10
RAID 10
- Referido como RAID 1+0.
- Mirroring and stripping.
- Requeridos mínimo 4 discos.
- Data is written in stripes across primary disks.
- Excelente redundancia y rendimiento.
- Es la mejor opción cuando tenemos aplicaciones críticas.
- Es bastante complejo de implementar.
- Los discos primarios son mirrored a los discos secundarios.
Finalizamos el tema de RAID.
File Systems
Vamos a hablar de almacenamiento desde una perspectiva diferente. Veníamos hablando de discos y sus operaciones (leer y escribir en los bloques). Pero, si solo usáramos estas operaciones, ¿cómo sabríamos donde está toda la información? ¿Còmo evitar que un usuario accese a la información de otro usuario? ¿Cómo sabríamos cuáles bloques están disponibles?
Un file system es una representación o una abstracción de la información almacenada en el disco duro; es una parte del sistema operativo que permite interactuar con los archivos. Nos la da el sistema operativo. Son unidades lógicas de información creadas por procesos y son independientes. La información contenida en los archivos es persistente: No se ve afectada por creación de procesos o terminación de procesos (la información se mantiene).
Tipos de file systems:
- Ext2, Ext3 (Linux)
- NTFS (Windows)
- FAT, FAT32 (Windows)
- COFS (CD ROM)
- Many others
Requerimientos para implementar un sistema de archivos:
-
Persistencia
-
Velocidad
-
Tamaño: Mayor capacidad de almacenamiento o gestionarlo de forma eficiente.
-
Sharing: Brindar opción de compartir información de mis archivos con otros usuarios.
-
Protección: Dejar que otras personas vean o editen mis archivos.
-
Fácil de usar: Garantizar que brinde un acceso sencillo.
-
Acceso random: Poder acceder a cualquier parte del sistema de archivos sin recorrer todo lo que tiene el disco duro.
Conceptos:
-
Disco: Permanent storage.
-
Bloque: Smallest writable unit by a disk or FS.
-
Partición: Subset of blocks.
-
Volumen:Nombre que se le da a la colección de bloques.
-
Superbloque: Donde el file system almacena la información crítica.
La abstracción de lo que está almacenado en un disco duro puede verse como una matriz.
Archivos
Abstracción que provee una forma de almacenar información. Permite ocultar al usuario el detalle de cómo y dónde está guardada la información y cómo funcionan los discos.
Estructura de los archivos
Existen 3 formas comunes para estructurar una archivo:
-
Byte de secuencia: Un archivo es solo una secuencia de bytes sin estructura. El SO no sabe o no l eimporta lo que hay en el archivo, todo lo que ve son bytes. Cualquier significado tiene que ser establecido por programas de nivel de usuario. Provee máxima flexibilidad. Estos archivos se llamaban archivos planos. UNIX y Windows 98 usan este enfoque.
-
Récord de tamaños fijos: Un archivo es un conjunto de bloques o récords con tamaño fijo y una estructura interna. Con la operación de lectura retorna un bloque completo y cuando escribo, también se escribe un bloque completo. Usado en mainframe/midrange operando sistemas.
-
Tree of records: Consiste en un árbol en el que los bloques o los récords no son necesariamente del mismo tamaño. Cada record tiene un key para permititr una búsqueda indexada rápida. Permite mejorar el rendimiento en cuanto a las búsquedas.
Tipos de archivos:
-
Archivos regulares: Contienen información del usuario (Word, Excel...).
-
Directorios: Sistemas de archivos que permiten mantener la estructura del file system.
-
Especiales de caracteres: Relacionados con input/output. Usados para gestionar o interactuar con dispositivos como impresoras, terminales y redes.
-
Archivos binarios: Archivos de los programas ejectuables.
Existen dos formas de acceder a la información de los archivos:
- Acceso secuencial: Un proceso solo podía leer los bytes o records de un archivo en orden, empezando desde el inicio. Era de esta forma porque usábamos cintas magnéticas. Una vez incorporados los discos duros, se implementó el random access, que permitía acceder a las partes del archivo que queríamos.
Un archivo almacena metadata.
Directorio: Special files used to keep track of files. The simplest form of directory system is having one directory ontaining all files.
Having al files in a single directory was not useful for general applications. A hierarchical directory system allowed to have as many directories as needed grouped in a suitable way.
Layout
File systems are stored on disks. El sector 0 del disco se llama Master Boot Record (MBR) es usado ára bootear la computadora. Al final del MBR se encuentra la tabla de partición. Esta tabla dice cuáles tienen sistemas operativos o cuáles son especiales para almacenar datos.
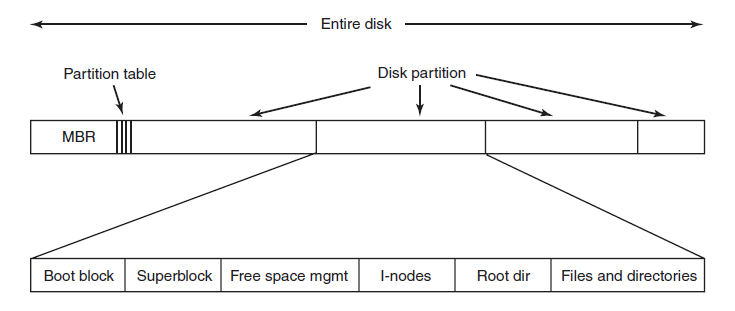
I-nodes: Almacenan la metadata de cada archivo.
¿Cómo saber cuáles bloques pertenecen a cada archivo?
Asignación contigua: Todos los bloques de un archivo están físicamente uno a la par del otro. Su principal problema es la fragmentación porque voy a tener que desfragmentar el disco cada cierto tiempo.
Asignación mediante lista enlazada: Mantener cada archivo como si fuera una lista enlazada de bloques de disco. La información no esytá contigua en el disco. Yo tengo un bloque y digo cual es el siguiente bloque. Estamos ganando en cómo estructuramos la información porque no hay que desfragmentar, pero pierdo el acceso random. Tengo que recorrer la lista.
i-Nodes: Asocian cada archivo con una estructura de dato la cual enlista los atributos y direcciones de disco del bloque de archivos. Aprovecho las ventajas de las anteriores porque permito referenciar a otros bloques y tengo acceso secuencial para poder almacenar archivos de mayor información.

15 punteros: 12 punteros a bloques de data. 13 indirect block, block containing pointers to data blocks 14 doubly indirect data-blocks (128 pointers) 15 triply indirect data-blocks
Su principal ventaja es que necesita estar en memoria solamente cuando el archivo está abierto. Voy cargando por bloques la información, un ejemplo es Word que va cargando la información a medida que hago scroll.
Tarea moral: Revisar qué son los i-nodos y cómo funcionan.
Jueves 17/10
Algoritmos de compresión
Lo que se busca es reducir la cantidad de bits que tenía la información original mediante de su codificación. El proceso de reducir el tamaño de la data se llama compresión.
Compresión sin pérdida: Elimina datos redundantes pero no elimina información. Puede descomprimir la información y voy a tener la información original.
Compresión con pérdida: No puedo obtener la representación original sino una aproximación. La información original no puede ser regenerada a partir de la sequencia comprimida. Cuando usamos algoritmos con pérdida al fin y al cabo lo que usamos es métodos que tratan de hacer aproximaciones a la información original pero no lo va a lograr al 100%. la tecnología de compresión que están bien diseñada generalmente reduce los tamaños de los archivos significativamente antes que la degradación sea notada por el usuario. Es comúnmente usada en archivos de multimedia como audio, video e imágenes, especialmente en streaming.
¿Por qué es importante la compresión?
La compresión es importante porque ayuda a reducir la cantidad de recursos como espacio de almacenamiento o capacidad de transmisión.
Algoritmos sin pérdida
Estos permiten que la data asea recuperada a aprtir de la data comprimida.
Huffmann Code
David H. desarrolló este algoritmo como estudiante en el MIT en 1950. Es probablemente el algoritmo que más ha prevalecido.
La idea es asignar códigos binarios lo más cortos posibles a aquellos caracteres que se presentan más frecuentemente en la data. A los símbolos menos frecuentes se le asignan códigos más largos. Construye un árbol binario, el cual es usado para asignar códigos a los símbolos. A first pass on the compresed data is performed to obtain the staticstics of symbols.
Symbols are arranged in a list according to its probability. This ordered list symbols are the initial node to tree construction.
- Si la lista solo contiene un nodo, terminamos.
- Si no, seleccionamos los primeros nodos de la lista con la menor probabilidad de que aparezca. Un nuevo nodo es creado a partir de la información de los nodos primeros de la lista. Sumo la cantidad de apariciones de los dos caracteres que estoy tomando y sumo la cantidad de caracteres que tienen los dos. El nuevo nodo es agregado a la lista enlazada, con el valor de probabilidad igual a la suma.
