ParaConverter - Vaa3D/Vaa3D_Wiki GitHub Wiki
ParaConverter (developed in collaboration with CINECA within the HBP project) is a python script that launches multiple instances of TeraConverter on a different portion of the dataset, ideally reaching perfect speedups (n CPUs = nx faster) of the conversion process if the I/O subsystem provides enough parallelism in both secondary storage access and data transfer.
See the Limitations section for more details.
-
Python 2. We suggest Python 2.7 (download).
-
a working MPI implementation. MPICH and Open-MPI are two valid options. For Linux and MacOS platforms we suggest Open-MPI v1.10 (download and installation instructions). For Windows platforms we suggest Microsoft MPI (download and installation instructions). To check that your MPI works and which implementation is running, just type
mpirun --versionormpiexec --version(on Windows platforms onlympiexecis available). You should also check that you have a workingmpicccompiler: just typempiccand check if it can execute.
If you are using CentOS or RedHat, there is a known bug in the preinstalled
mpichwhich may conflict with the requirement #3. Please remove any existing MPI installation (e.g.yum remove mpich*) and then installopenmpiwithyum install mpi4py-openmpi. To enableopenmpi, runmodule load openmpi-x86_64ormodule load mpi/openmpi-x86_64(if you don't have themoduleutility, install it withyum install environment-modules).
-
MPI for Python (
mpi4py, installation instructions) -
a working TeraConverter executable in the system
PATH(i.e. you must be able to callteraconverterfrom command-line from any place)
- [link] TeraConverter executable (included in the TeraStitcher-portable package)
-
[link] ParaConverter Python driver
See Section 3 and Appendix D of the TeraTools guide for usage of the scripts and further details.
See the following demo for how to use ParaConverter.
- download and unpack the example dataset at this link
- follow the demo of TeraConverter to see how long it takes to convert the example image with one instance of TeraConverter
- follow the demo below and in your case choose the appropriate number of processes depending on your CPUs
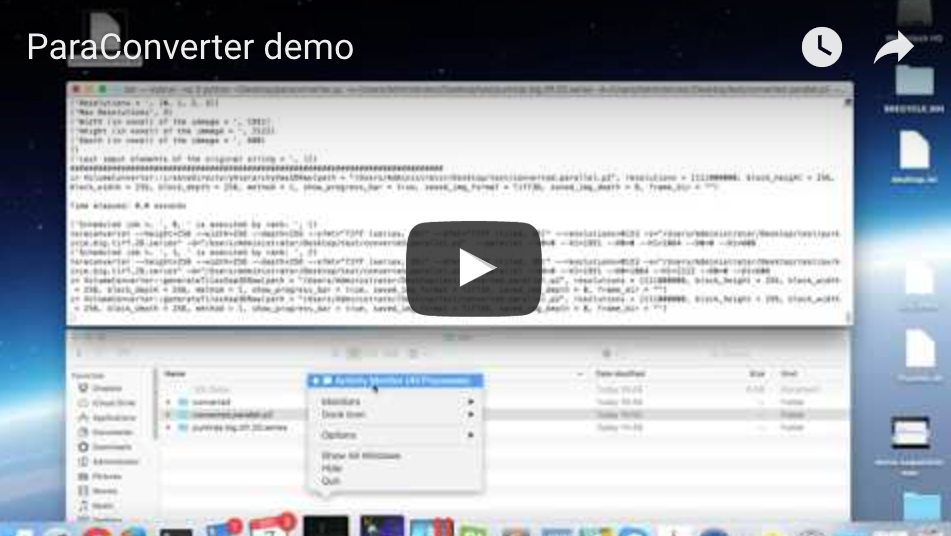
In this demo, we obtain a speedup of 1.4x and an efficiency of about 70% with 2 instances of TeraConverter running on a MacBook Pro with a dual-core CPU and input/output from/to the local SSD storage.
Conversion of large 3D images is an I/O bound operation. Although some computation might be needed (e.g. for compression/decompression), the whole dataset to be converted has to be first read from the original format and then written to the final format.
That said, in order to achieve high speedups with ParaConverter, one has to consider the following limitations:
-
the number of physical CPU cores available: the
-npoption should not set a number of processes higher than the available physical CPU cores. Thus, with a quad-core CPU, the highest (ideal) achievable speedup is 4x, and so on. - the underlying I/O system: it is highly desirable to have an I/O subsystem supporting parallel I/O, i.e. an hardware I/O architecture that can execute multiple physical accesses to secondary storage and related data transfers in parallel. If I/O is not really parallelised, for the Amdahl law, the achievable speedup is necessarily limited.
- the file format: it is highly desirable to have a file format (both in input and in output) allowing to access only a portion of the dataset in a single I/O operation so that when multiple I/O operations are issued in parallel the same data are not accessed and transferred twice. Among the file formats supported by TeraConverter, tiled formats (both TIFF and Vaa3D), all Vaa3D formats, and HDF5 formats do meet this requirement.
An important observation is that the achieved speedups should be evaluated taking into account the performance of the I/O subsystem. In other words it may be trivial achieve high speedups when the I/O subsystem supports transparently parallel I/O operations, while it could be considered a remarkable result to achieve even limited speedups thanks to a careful management of all other resources involved in the conversion on systems that do not support parallel I/O or support it at a limited extent.