JPA - UDFJDC-ModelosProgramacion/Recursos GitHub Wiki
- Introducción
- El mapeo de los objetos a las tablas
- Acceso a la base de datos utilizando JPA.
- Referencias y material complementario

Los desarrolladores de aplicaciones en lenguajes de programación orientados por objetos (OO), como Java, cuyos datos son persistidos en bases de datos relacionales, enfrentan un problema conocido como impedance mismatch. Este problema se crea por la no concordancia entre la forma de modelar los datos en OO y en relacional. El desarrollador debe hacer un esfuerzo para "traducir" de un lado para otro. La Figura 1 ilustra el problema. El elemento llamado "Mapping" tiene la responsabilidad de realizar la correspondencia entre los modelos.
 |
|---|
| Figura 1. Tomada de https://www.service-architecture.com/articles/object-oriented-databases/impedance_mismatch.html |
Para ayudar a los desarrolladores a resolver el problema, existen los Object-relational mapping (ORM). En el mundo de Java, el más popular es Java Persistence API (JPA). JPA ofrece servicios para realizar las correspondencias o Mappings entre los objetos y las tablas relacionales y servicios para acceder a la base de datos. Es un conjunto de interfaces independientes de un proveedor específico y existen varias implementaciones como por ejemplo EclipseLink, Hibernate o TopLink.
En JPA se utilizan anotaciones sobre las clases, atributos y métodos para definir la correspondencia entre los objetos y las tablas. Una clase anotada con @Entity corresponderá con una tabla. Por defecto, el nombre de la clase será el nombre de la tabla y cada uno de los atributos de tipo básico de la clase corresponderá con una columna de la tabla. La Figura 2 muestra un ejemplo simple donde la clase llamada EmployeeEntity (anotada con @Entity) tiene tres atributos simples (id, name, salary) es mapeada a una tabla del mismo nombre que tiene tres columnas. También hay una correspondencia entre los tipos de datos: Long se convierte en BIGINT, String se convierte en VARCHAR y Double en Double.
 |
|---|
| Figura 2 |
Como se observa en la Figura 3, cada instancia de la clase EmployeeEntity puede convertirse en una fila en la tabla EMPLOYEEENTITY. Luego, al cambiar los valores de los atributos de los objetos, estos valores se cambiarán también en la fila donde están guardados.
 |
|---|
| Figura 3 |
En nuestra convención de nombramiento, al nombre de cada clase del modelo conceptual que se convierte en una entidad se le agrega la palabra
Entity. Si la clase en el modelo conceptual era, por ejemplo,Employee, en el modelo de entidades seráEmployeeEntity.
En la Guía de las anotaciones en JPA y en el wikibook Java Persistence podemos encontrar el detalle y ejemplos de cada una de las anotaciones utilizadas para definir la metadata que le permitirá al proveedor de JPA generar las correspondencias entre el modelo objetos y el modelo relacional. La siguiente tabla presenta un pequeño resumen de algunas de las anotaciones utilizadas en los ejemplos de este libro.
| Anotación | Descripción | Atributos |
|---|---|---|
| @Entity | Sobre una clase. La clase corresponderá con una tabla en la BD relacional. |
name el nombre de la entidad en los queries. Por defecto es el nombre (sin los paquetes) de la clase. |
| @Column | Sobre un atributo (o método get). Especifica la relación entre un atributo de la clase y una columna de la tabla. Por defecto cada atributo será una columna. |
name nombre la columna. Por defecto es el mismo nombre del atributo |
nullable indica si el campo de la columna puede ser nulo. Por defecto es true
|
||
length para los atributos de tipo String indica la longitud máxima. Por defecto el valor es 255. |
||
| @Id | Sobre un atributo (o método get). Especifica la llave primaria de la entidad. | |
| @GeneratedValue | utilizado para generar el valor de las llaves primarias. |
strategy define la estrategia de generación del valor de la llave primaria. Esta estrategia puede ser: |
| GenerationType.IDENTITY | ||
| GenerationType.TABLE | ||
| GenerationType.SEQUENCE |
Veamos el ejemplo en java de la entidad EmployeeEntity:
@Entity
public class EmployeeEntity
{
@Id
private Long id;
private Double salary;
private String name;
...
}Tenemos que la clase debe estar anotada por @Entity. Adicionalmente, el atributo id, que fue definido como la llave primaria está anotado por @Id.

Como vimos en la sección anterior el concepto de Entity en JPA permite representar objetos persistentes que se guardan en registros de la base de datos.
La interface JpaRepository es una herramienta en Spring para acceder a la base de datos. Tiene servicios para crear objetos persistentes, obtenerlos, borrarlos y crear queries personalizadas.
En el siguiente ejemplo se está definiendo una interface EmployeeRepository que extiende de JpaRepository.
@Repository
public interface EmployeeRepository extends JpaRepository<EmployeeEntity, Long> {
}La decisión de diseño para la capa de persistencia consiste en tener una clase de persistencia (o Repository) por cada entidad. La lógica de la aplicación se comunica con estas clases que manipulan las entidades persistentes. Para responder a los servicios básicos CRUD, cada clase de persistencia tiene acceso a los métodos:
| Método | Parámetros | Retorno | |
|---|---|---|---|
| C | save | El objeto de la entidad que se quiere persistir | El objeto que se persistió incluido el id(llave primaria) que la base de datos generó |
| R | findById |
id: llave primaria de la entidad que se va a buscar |
Objeto de la entidad correspondiente |
| R | findAll | Retorna la colección de todos los objetos que existen en la base de datos de la entidad correspondiente. | |
| U | save | El objeto de la entidad que se quiere actualizar | El objeto actualizado |
| D | deleteById |
id: llave primaria de la entidad que se va a borrar. |
void |
Una clase de persistencia puede tener muchos otros métodos adicionales al CRUD, la mayoría de estos pueden estar relacionados con consultas y cálculos sobre la base de datos. Por ejemplo, se puede definir un método que se ocupa de devolver un empleado que coincide con un nombre dado.
| Método | Parámetros | Retorno | |
|---|---|---|---|
| R | findByName |
name: nombre del empleado que se quiere buscar. |
Objeto de la entidad correspondiente si la encuentra. |
Cuando un objeto de una clase anotada con Entity es creado, este está en un estado que no tiene, todavía, ninguna relación con la base de datos. Cuando el objeto es persistido o cuando un objeto es obtenido de la base de datos, queda en un estado manejado (Managed) por JPA. Cuando estos objetos son removidos o separados de su manejador (detach) salen del estado Managed (ver Figura 4).
 |
|---|
| Figura 4. Imagen tomada de: ObjectDB |
El Contexto de Persistencia es el conjunto de todos los objetos (entidades) que se encuentran en el estado manejado por JTA (Managed en la figura). Cada Entity Manager tiene su propio contexto de persistencia.
A estos objetos en el contexto de persistencia les ocurre:
- Acceso Base de datos: solo hay una representación en memoria para un objeto (entity) dado y si se pregunta por ese objeto y ya está en el contexto no se accede de nuevo a la base de datos.
- Actualizaciones automáticas: si se cambia el valor de un atributo en uno de estos objetos, ese valor se cambiará automáticamente en la base de datos (sin necesidad de hacer una actualización explícita. Si los objetos tienen atributos que representan relaciones con otros objetos y estos atributos están anotados con el atributo
Cascade.PersistoCascade.ALL, también se actualizarán esos objetos relacionados.

Vamos a utilizar el diagrama conceptual de la Figura 5, para explicar cómo con JPA se define, desde las clases Java utilizando anotaciones, la correspondencia con las tablas.
 |
|---|
| Figura 5 |
Cada relación entre las clases debe anotarse de acuerdo con la semántica de la relación. Si tomamos el modelo de clases en la figura anterior, podemos ver que hay dos relaciones:
-
La entidad
Companytiene una relación con la entidadDepartment:- Una compañía puede tener muchos departamentos (one to many)
- Un departamento le pertenece a una única compañía (many to one)
-
La entidad
Departmenttiene una relación con la entidadEmployee:- Un departamento tiene muchos empleados (one to many)
- Un empleado trabaja para un departamento (many to one)
Podemos utilizar un diagrama de clases con anotaciones (ver Figura 6) para reflejar nuestras decisiones de diseño. En el siguiente diagrama mostramos la relación entre CompanyEntity y DepartmentEntity. En términos de las entidades, esta relación es bidireccional, es decir, una compañía puede tener muchos departamentos (one to many) y un departamento le pertenece a una única compañía (many to one).
Note que lo más importante es definir las propiedades del extremo de la relación. En el caso del extremo departments, la propiedad de cardinalidad dice OneToMany y que está mappedBy, es decir, el atributo correspondiente al otro lado se llama company. El extremo departments también tiene seleccionada la opción fectch = FetchType.LAZY que significa que cuando cargue una compañía, no cargue al mismo tiempo los departamentos sino que lo haga "perezosamente" hasta cuando los necesite. Esto puede tener un impacto importante en el desempeño de la aplicación.
En el caso del extremo company, la cardinalidad es ManyToOne.
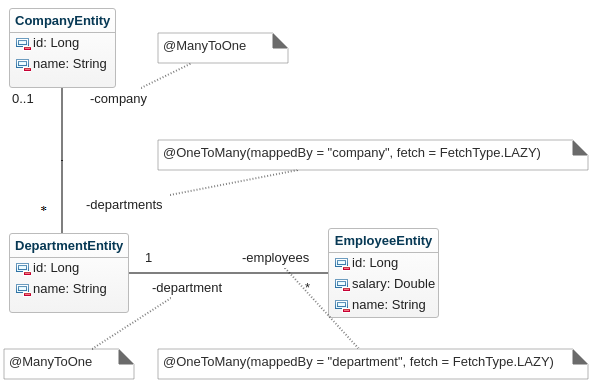 |
|---|
| Figura 6 |
La relación entre DepartmentEntity y EmployeeEntity se modela de la misma forma que la anterior.
Ahora veamos la implementación de este modelo en Java. los extremos se convierten en atributos de las clases. Tomemos la clase CompanyEntity: en el caso del extremo departments, este será un atributo de la clase DepartmentEntity que tendrá las anotaciones correspondientes de la cardinalidad y de las demás propiedades. Como este atributo es de cardinalidad OneToMany, su tipo de dato debe ser una colección, por ejemplo, List<DepartmentEntity>.
Veamos el código:
@Entity
public class CompanyEntity{
@Id
private Long id;
private String name;
@OneToMany(
mappedBy = "company",
fetch = FetchType.LAZY
)
List<DepartmentEntity> departments = new ArrayList<>();
...
}En la clase DepartmenEntity debe obligatoriamente definirse el atributo company al que se hace referencia en la anotación OneToMany. Podemos ver a continuación el código de la clase DepartmentEntity para ver cómo se definió el atributo company y también para ver cómo se define el extremo que relaciona DepartmentEntity y EmployeeEntity, en este caso llamado employees:
@Entity
public class DepartmentEntity {
@Id
private Long id;
private String name;
@ManyToOne
Company company;
@OneToMany(
mappedBy = "department",
fetch = FetchType.LAZY
)
List<EmployeeEntity> employees = new ArrayList<>();
...
}Finalmente, este es el código de la clase EmployeeEntity:
@Entity
public class EmployeeEntity {
@Id
private Long id;
private String name;
private Double salary;
@ManyToOne
DepartmentEntity department;
...
}Sirven para anotar atributos cuyo tipo es una colección de objetos de alguna clase anotada con @Entity.
| Anotación | Descripción | Atributos |
|---|---|---|
| OneToMany | Se aplica sobre un atributo que representa una relación que indica que el objeto fuente, es decir el objeto de la clase que tiene el atributo, tiene una colección (many) de objetos de la clase del destino. |
mappedBy: indica el nombre del atributo en el destino que representa la relación inversa. |
cascade: permite definir si las operaciones sobre la fuente se propagarán al destino. Por ejemplo si se borra la fuente que se borren los destinos. |
||
fetch: puede tener dos valores Lazypara indicar que los destinos no se cargan sino hasta cuando se necesitan o Eagear para indicar que los destinos se cargan al mismo tiempo con la fuente. |
||
orphanRemoval: no puede haber ningún objeto destino de esta relación que no tenga fuente. |
Sirven para anotar atributos cuyo tipo es una clase anotada con @Entity.
Una relación OneToOne en Java es cuando el objeto origen tiene un atributo que hace referencia a otro objeto destino. Las relaciones en Java y JPA son unidireccionales, es decir, si un objeto origen hace referencia a un objeto destino no existe ninguna garantía de que el objeto destino también tenga una relación hacia el objeto origen, a menos que la relación inversa sea definida explícitamente. Esto es diferente en una base de datos relacional, en el que las relaciones se definen a través de llaves foráneas y las consultas, en ambos sentidos, se pueden realizar utilizando estas llaves.