MACHINE LEARNING - Truc1202/Spark-and-Mapreduce GitHub Wiki
Học máy là một phần của một phần mở rộng hơn được gọi là Trí tuệ nhân tạo. Học máy đề cập đến việc nghiên cứu các mô hình thống kê để giải quyết các vấn đề cụ thể với các mẫu và suy luận. Các mô hình này được “huấn luyện” cho một vấn đề cụ thể bằng cách sử dụng dữ liệu huấn luyện rút ra từ không gian bài toán. Học máy (tiếng Anh: machine learning) là một lĩnh vực của trí tuệ nhân tạo liên quan đến việc nghiên cứu và xây dựng các kĩ thuật cho phép các hệ thống "học" tự động từ dữ liệu để giải quyết những vấn đề cụ thể. Ví dụ như các máy có thể "học" cách phân loại thư điện tử xem có phải thư rác (spam) hay không và tự động xếp thư vào thư mục tương ứng. Học máy rất gần với suy diễn thống kê (statistical inference) tuy có khác nhau về thuật ngữ.
Học máy có liên quan lớn đến thống kê, vì cả hai lĩnh vực đều nghiên cứu việc phân tích dữ liệu, nhưng khác với thống kê, học máy tập trung vào sự phức tạp của các giải thuật trong việc thực thi tính toán. Nhiều bài toán suy luận được xếp vào loại bài toán NP-khó, vì thế một phần của học máy là nghiên cứu sự phát triển các giải thuật suy luận xấp xỉ mà có thể xử lý được.
Học máy có hiện nay được áp dụng rộng rãi bao gồm máy truy tìm dữ liệu, chẩn đoán y khoa, phát hiện thẻ tín dụng giả, phân tích thị trường chứng khoán, phân loại các chuỗi DNA, nhận dạng tiếng nói và chữ viết, dịch tự động, chơi trò chơi và cử động rô-bốt (robot locomotion).
1.1.1 Giới thiệu chung
Theo một cách tiếp cận, thì thông thường học máy được phân loại thành hai mục là supervised learning và unsupervised learning.
Supervised learning là việc hoạt động với một tập dữ liệu chứa cả đầu vào và đầu ra mong muốn. Ví dụ:tập dữ liệu chứa các đặc điểm khác nhau của bất động sản và thu nhập cho thuê dự kiến. Học tập có giám sát được chia thành hai tiểu loại lớn được gọi là phân loại và hồi quy:
*
Các thuật toán phân loại có liên quan đến đầu ra phân loại, chẳng hạn như việc một thuộc tính có bị chiếm dụng hay không
* Thuật toán hồi quy có liên quan đến phạm vi đầu ra liên tục, như giá trị của thuộc tính.
Unsupervised learning hoạt động với một tập hợp dữ liệu chỉ có các giá trị đầu vào . Nó hoạt động bằng cách cố gắng xác định cấu trúc vốn có trong dữ liệu đầu vào. Ví dụ: tìm kiếm các kiểu người tiêu dùng khác nhau thông qua tập dữ liệu về hành vi tiêu dùng của họ.
Học máy thực sự là một lĩnh vực nghiên cứu liên ngành. Nó yêu cầu kiến thức về lĩnh vực kinh doanh, thống kê, xác suất, đại số tuyến tính và lập trình. Vì điều này rõ ràng có thể trở nên quá tải, tốt nhất nên tiếp cận điều này một cách có trật tự. Mọi dự án học máy nên bắt đầu với một câu lệnh vấn đề được xác định rõ ràng. Việc này phải được thực hiện theo một loạt các bước liên quan đến dữ liệu có thể giải đáp vấn đề. Sau đó, chọn một mô hình xem xét bản chất của vấn đề. Tiếp theo là một loạt quá trình đào tạo và xác nhận mô hình, được gọi là tinh chỉnh mô hình. Cuối cùng, chúng tôi kiểm tra mô hình trên dữ liệu chưa từng thấy trước đó và triển khai nó vào sản xuất nếu đạt yêu cầu.<\p>

Quy trình của Machine Learning
Spark MLlib là một mô-đun nằm trên Spark Core cung cấp các nguyên bản về máy học dưới dạng API. Học máy thường xử lý một lượng lớn dữ liệu để đào tạo mô hình.<\p>
Khung máy tính cơ sở từ Spark là một lợi ích to lớn. Trên hết, MLlib cung cấp hầu hết các thuật toán thống kê và học máy phổ biến. Điều này giúp đơn giản hóa đáng kể nhiệm vụ làm việc trên một dự án máy học quy mô lớn.<\p>
Spark MLlib được sử dụng để thực hiện học máy trong Apache Spark. MLlib bao gồm các thuật toán và tiện ích phổ biến. MLlib trong Spark là một thư viện mở rộng của học máy để thảo luận về các thuật toán chất lượng cao và tốc độ cao.<\p>
##4.2 Một số công cụ sử dụng Spark.Mllib
Spark.Mllib là API học máy chính cho Spark. Thư viện Spark.Mllib cung cấp một API cấp cao hơn được xây dựng trên DataFrames để xây dựng các pipeline cho machine learning. Một số công cụ như:
Thuật toán ML
Featurization
Pipelines
Persistence
Utilities<\p>
##4.3 Thuật toán Machine Learning
Các thuật toán ML chính là cốt lõi của MLlib. Chúng bao gồm các thuật toán học tập phổ biến như phân loại, hồi quy, phân cụm và lọc cộng tác. MLlib chuẩn hóa các API để giúp kết hợp nhiều thuật toán vào một đường dẫn hoặc quy trình làm việc dễ dàng hơn. Các khái niệm chính là API đường ống, trong đó khái niệm đường ống được lấy cảm hứng từ dự án scikit-learning.
- Transformer: là một thuật toán biển đổi một Dataframe thành một Dataframe khác. Về mặt lý thuyết nó thực hiện một phương thức transform() dùng để chuyển đỏi một Dataframe thành một Dataframe khác bằng cách thêm một hoặc nhiều cột.
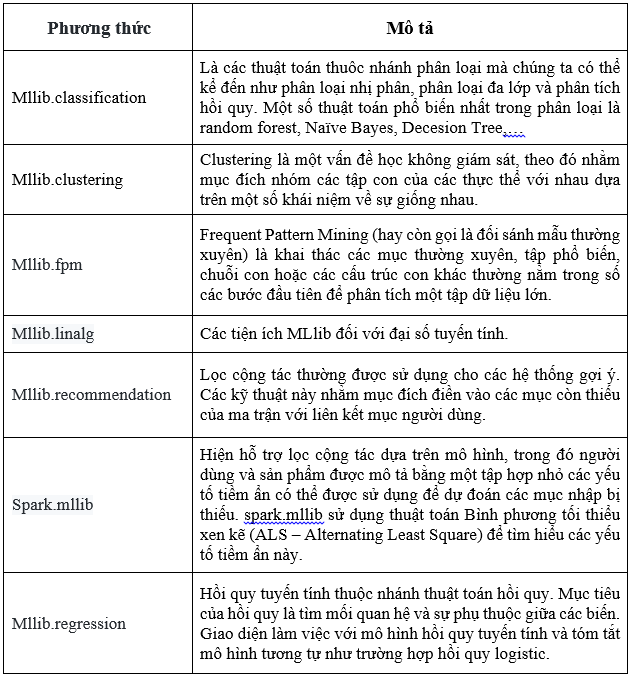
- Estimator: là một thuật toán phù hợp trên Dataframe để tạo Transformer. Về mặt kỹ thuật, Estimator triển khai phương thức fit() và chấp nhận DataFrame tạo ra một mô hình là một transformer.<\p> ##4.4 Các phương thức thư viện mllib cung cấp
- https://www.coursera.org/learn/machine-learning
- http://itechseeker.com/tutorials/apache-spark/lap-trinh-spark-voi-scala/spark-sql-dataset-va-dataframes/
- https://vietnambiz.vn/may-hoc-machine-learning-la-gi-ung-dung-thuc-tien-20190923225908014.htm
- https://trituenhantao.io/kien-thuc/machine-learning-va-cac-khai-niem-co-ban/