API OF SPARK - Truc1202/Spark-and-Mapreduce GitHub Wiki
Khi làm việc Apache Spark, chúng ta thường gặp bộ ba API: DataFrame, DataSet và RDD. Đây là một trong những điểm hấp dẫn của Apache Spark đối với các nhà phát triển với các API dễ sử dụng, để hoạt động trên các tập dữ liệu lớn, trên các ngôn ngữ: Scala, Java, Python và R. Vì sao lại có sự xuất hiện của bộ ba API này? Tại sao, khi nào nên sử dụng từng bộ? Và cách sử dụng chúng như thế nào, chúng ta sẽ tìm hiểu trong bài viết sau đây?
1.1.1 Giới thiệu chung
RDD ( Resilient Distributed Datasets) - tập dữ liệu phân tán có khả năng phục hồi là một cấu trúc dữ liệu cơ bản của Spark. Nó là một tập hợp các đối tượng được phân phối bất biến. Mỗi tập dữ liệu trong RDD được chia thành các phân vùng logic, có thể được tính toán trên các nút khác nhau của cụm. RDD có thể chứa các đối tượng Python, Java hoặc Scala bất kỳ, bao gồm các lớp do người dùng định nghĩa.
Apache Về mặt hình thức, RDD là một tập hợp các bản ghi được phân vùng, chỉ đọc. RDD có thể được tạo thông qua các hoạt động xác định trên dữ liệu trên bộ lưu trữ ổn định hoặc các RDD khác. RDD là một tập hợp các phần tử chịu được lỗi có thể hoạt động song song.
Apache Có hai cách để tạo RDD - song song một tập hợp hiện có trong chương trình trình điều khiển của bạn hoặc tham chiếu tập dữ liệu trong hệ thống lưu trữ bên ngoài, chẳng hạn như hệ thống tệp chia sẻ, HDFS, HBase hoặc bất kỳ nguồn dữ liệu nào cung cấp Định dạng đầu vào Hadoop.

Cấu trúc của RDD
1.1.2 Vấn đề chia sẻ dữ liệu chậm trong Mapreduce
Spark Sử dụng RDD để đạt được các hoạt động MapReduce nhanh hơn và hiệu quả hơn. Bởi MapReduce sử dụng rộng rãi để xử lý và tạo các bộ dữ liệu lớn với một thuật toán phân tán, song song trên một cụm. Nó cho phép người dùng viết các phép tính song song, sử dụng một tập hợp các toán tử cấp cao, mà không phải lo lắng về việc phân phối công việc và khả năng chịu lỗi. Nhưng vẫn có trường hợp muốn sử dụng lại dữ liệu giữa các lần tính toán (Ví dụ: giữa hai công việc MapReduce) là phải ghi nó vào hệ thống lưu trữ ổn định bên ngoài (Ví dụ - HDFS) mặc dù Mapreduce có cung cấp nhiều nội dung trừu tượng để truy cập tài nguyên tính toán của một cụm.
Cả hai ứng dụng Lặp lại và Tương tác đều yêu cầu chia sẻ dữ liệu nhanh hơn trên các công việc song song. Chia sẻ dữ liệu chậm trong MapReduce là do sao chép, tuần tự hóa và IO đĩa. Về hệ thống lưu trữ, hầu hết các ứng dụng Hadoop, chúng dành hơn 90% thời gian để thực hiện các thao tác đọc-ghi HDFS.
1.1.3 Ứng dụng lặp lại và tương tác trên Mapreduce
Ứng dụng lặp lại sử dụng lại các kết quả trung gian qua nhiều lần tính toán trong nhiều giai đoạn. Hình minh họa sau giải thích cách hoạt động của Mapreduce hiện tại trong khi thực hiện các hoạt động lặp lại trên MapReduce. Điều này phát sinh chi phí đáng kể do sao chép dữ liệu, I / O đĩa và tuần tự hóa, khiến hệ thống chậm.
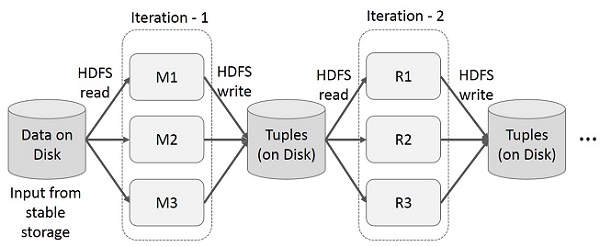
Hoạt động lặp lại của Mapreduce
Hoạt động tương tác trên Mapreduce diễn ra khi người dùng chạy các truy vấn đặc biệt trên cùng một tập con dữ liệu. Mỗi truy vấn sẽ thực hiện I / O đĩa trên bộ nhớ ổn định, có thể chi phối thời gian thực thi ứng dụng. Hình minh họa sau giải thích cách hoạt động của khung hiện tại khi thực hiện các truy vấn tương tác trên MapReduce.
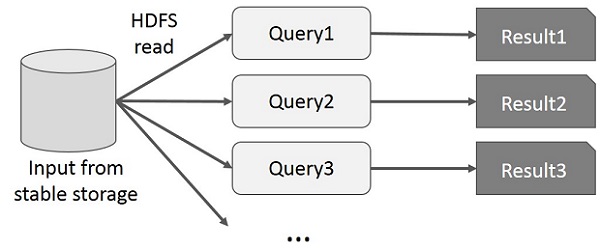
Hoạt động tương tác trên Mapreduce
1.1.4 Chia sẻ dữ liệu bằng Spark RDD
Để giải quyết việc chia sẻ dữ liệu chậm trong MapReduce các nhà nghiên cứu đã phát triển một framework chuyên biệt có tên là Apache Spark. Mà cốt lõi là Resilient Distributed Datasets (RDD), nó hỗ trợ tính toán xử lý trong bộ nhớ. Điều này có nghĩa là, nó lưu trữ trạng thái bộ nhớ như một đối tượng trên các công việc và đối tượng có thể chia sẻ giữa các công việc đó. Chia sẻ dữ liệu trong bộ nhớ nhanh hơn mạng và Đĩa từ 10 đến 100 lần.
Hình minh họa dưới đây cho thấy các hoạt động lặp lại trên Spark RDD. Nó sẽ lưu trữ các kết quả trung gian trong một bộ nhớ phân tán thay vì Ổ lưu trữ ổn định (Disk) và làm cho hệ thống nhanh hơn. Có một lưu ý nho nhỏ: Nếu bộ nhớ Phân tán (RAM) không đủ để lưu trữ các kết quả trung gian (Trạng thái công việc), thì nó sẽ lưu các kết quả đó trên đĩa.
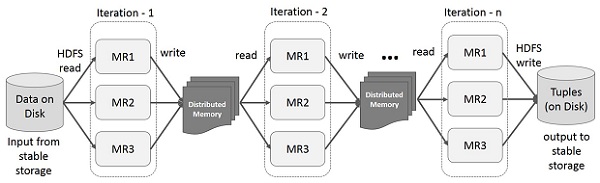
Hoạt động lặp lại trên Spark RDD
Hình minh họa này cho thấy các hoạt động tương tác trên Spark RDD. Nếu các truy vấn khác nhau được chạy lặp lại trên cùng một tập dữ liệu, thì dữ liệu cụ thể này có thể được lưu trong bộ nhớ để có thời gian thực thi tốt hơn.
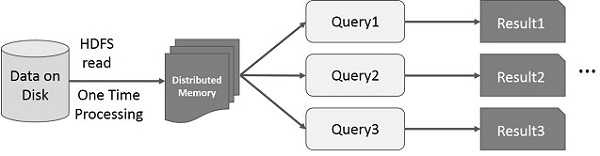
Hoạt động tương tác trên Spark RDD
Theo mặc định, mỗi RDD đã chuyển đổi có thể được tính toán lại mỗi khi bạn chạy một hành động trên đó. Tuy nhiên, bạn cũng có thể duy trì một RDD trong bộ nhớ, trong trường hợp đó Spark sẽ giữ các phần tử xung quanh trên cụm để truy cập nhanh hơn nhiều, vào lần tiếp theo bạn truy vấn nó. Ngoài ra còn có hỗ trợ cho các RDD lâu dài trên đĩa hoặc được sao chép qua nhiều nút.
1.1.5 Mặt hạn chế Spark RDD
Bên cạnh những ưu thế đa năng xử lý trên cả dữ liệu có cấu trúc và không có cấu trúc, bộ sưu tập phân tán, bất biến, chịu lỗi thì RDD còn một số những hạn chế như: Không có công cụ tối ưu hóa tích hợp. Khi làm việc với dữ liệu có cấu trúc, RDD không tận dụng các trình tối ưu hóa tiên tiến của Spark (trình tối ưu hóa chất xúc tác và công cụ thực thi Vonfram). Các nhà phát triển cần tối ưu hóa từng RDD dựa trên các thuộc tính đặc tính của nó.
Ngoài ra, không giống như DataFrames và Datasets, RDD không suy ra lược đồ của dữ liệu được nhập - người dùng được yêu cầu chỉ định rõ ràng.
1.2.1 Định nghĩa
Trong Spark, DataFrame là một tập hợp dữ liệu phân tán được tổ chức thành các cột được đặt tên. Về mặt khái niệm, nó tương đương với một bảng trong cơ sở dữ liệu quan hệ hoặc một khung dữ liệu trong R / Python, nhưng với các tối ưu hóa phong phú hơn. DataFrames có thể được xây dựng từ nhiều nguồn như: tệp dữ liệu có cấu trúc, bảng trong Hive, cơ sở dữ liệu (SQL) hoặc RDD hiện có.<\p>
Ví dụ minh họa với Spark SQL: <\p>

Dataframe in Spark SQL
Tạo một DataFrame về nhân viên có Tên của nhân viên dưới dạng kiểu dữ liệu chuỗi, ID nhân viên là kiểu dữ liệu chuỗi, Số điện thoại của nhân viên dưới dạng kiểu dữ liệu số nguyên, Địa chỉ nhân viên dưới dạng chuỗi kiểu dữ liệu, Mức lương của nhân viên dưới dạng kiểu dữ liệu nổi. Dữ liệu của từng nhân viên được lưu theo từng hàng như hình trên.<\p>
1.2.2 DataFrames được thiết kế để đa chức năng
Đặc tính tốt nhất của DataFrames trong Spark là hỗ trợ nhiều ngôn ngữ, giúp các lập trình viên từ các nền tảng lập trình khác nhau sử dụng dễ dàng hơn. DataFrames trong Spark hỗ trợ R - Ngôn ngữ lập trình, Python, Scala và Java.<\p>
DataFrames trong Spark có thể hỗ trợ nhiều nguồn dữ liệu khác nhau.<\p>
Một số nguồn dữ liệu của DataFrame
Yêu cầu cốt lõi mà DataFrames được giới thiệu là xử lý Dữ liệu lớn một cách dễ dàng. DataFrames trong Spark sử dụng định dạng bảng để lưu trữ dữ liệu theo cách linh hoạt cùng với lược đồ cho dữ liệu mà nó đang xử lý. <\p>
API DataFrame hỗ trợ Slicing và Dicing dữ liệu. Nó có thể thực hiện các thao tác như chọn và lọc theo hàng và cột. Dữ liệu thống kê luôn có xu hướng bị Thiếu giá trị, Vi phạm phạm vi và giá trị không liên quan. Người dùng có thể quản lý dữ liệu bị thiếu một cách rõ ràng bằng cách sử dụng DataFrames.<\p>
1.2.3 Các tính năng của DataFrame trong Spark

DataFrame trong spark có bản chất là Bất biến. Giống như Tập dữ liệu được phân phối có khả năng phục hồi, dữ liệu có trong DataFrame không thể bị thay đổi.
Việc lười đánh giá là chìa khóa cho hiệu suất đáng chú ý do Spark mang lại. DataFrames trong Spark sẽ không hiển thị đầu ra trên màn hình trừ khi một thao tác hành động được kích hoạt.
Kỹ thuật Bộ nhớ phân tán được sử dụng để xử lý dữ liệu làm cho chúng có khả năng chịu lỗi.
Giống như Tập dữ liệu phân tán có khả năng phục hồi, DataFrames trong Spark mở rộng thuộc tính của mô hình bộ nhớ phân tán. Cách duy nhất để thay đổi hoặc sửa đổi dữ liệu trong DataFrame sẽ là áp dụng Chuyển đổi.
1.2.4 Nguồn cho Spark Data Frame
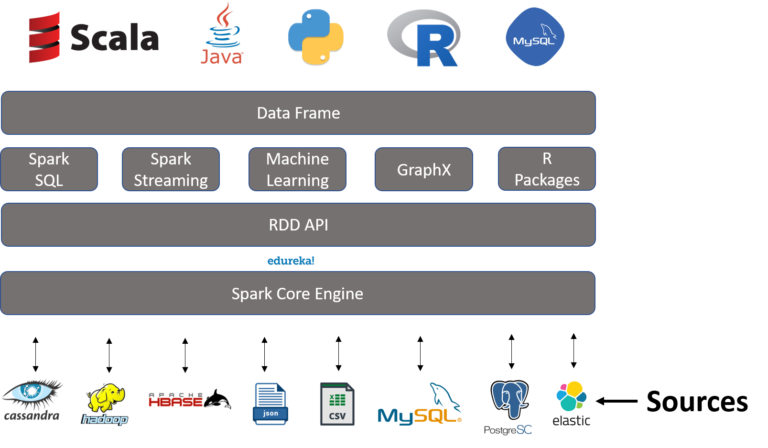
Có rất nhiều cách để tạo DataFrame trong Spark như:
Dữ liệu có thể được tải vào thông qua CSV, JSON, XML, SQL, RDBMS và nhiều hơn nữa. Nó cũng có thể được tạo bằng cách sử dụng RDD hiện có và thông qua bất kỳ cơ sở dữ liệu nào khác, như Hive , HBase , Cassandra . Nó cũng có thể lấy dữ liệu từ HDFS hoặc hệ thống tệp cục bộ.

Tập dữ liệu trong Apache Spark là một phần mở rộng của API DataFrame, cung cấp giao diện lập trình hướng đối tượng, an toàn về kiểu. Dataset tận dụng lợi thế của trình tối ưu hóa Catalyst của Spark bằng cách hiển thị các biểu thức và trường dữ liệu cho công cụ lập kế hoạch truy vấn.
Để khắc phục những hạn chế của RDD và Dataframe, Dataset ra đời. Trong DataFrame, không có điều khoản nào về an toàn kiểu thời gian biên dịch. Dữ liệu không thể bị thay đổi nếu không biết cấu trúc của nó. Trong RDD không có tối ưu hóa tự động. Vì vậy, để tối ưu hóa, chúng ta sẽ cần đến Dataset
Tập dữ liệu trong Spark cung cấp truy vấn được Tối ưu hóa bằng cách sử dụng Trình tối ưu hóa truy vấn Catalyst và Tungsten. Catalyst Query Optimizer là một khung thực thi không khả thi. Nó biểu diễn và thao tác một biểu đồ luồng dữ liệu. Đồ thị luồng dữ liệu là một cây gồm các biểu thức và toán tử quan hệ. Bằng cách tối ưu hóa công việc Spark, Tungsten cải thiện việc thực thi. Tungsten nhấn mạnh kiến trúc phần cứng của nền tảng Apache Spark chạy trên đó.
Sử dụng Dataset, chúng ta có thể kiểm tra cú pháp và phân tích tại thời điểm biên dịch. Không thể sử dụng Dataframe, RDDs hoặc các truy vấn SQL thông thường.
Bộ dữ liệu Spark đều có thể tuần tự hóa và có thể truy vấn. Do đó, chúng tôi có thể lưu nó vào bộ nhớ liên tục.
Chúng ta cũng có thể chuyển đổi tập dữ liệu Type-safe thành DataFrame “chưa được định kiểu”. Để thực hiện tác vụ này Datasetholder cung cấp ba phương pháp để chuyển đổi từ kiểu Seq [T] hoặc RDD [T] sang Dataset [T] để chuyển đổi.
Việc triển khai Dataset nhanh hơn nhiều so với việc triển khai RDD. Do đó làm tăng hiệu suất của hệ thống. Để có hiệu suất tương tự khi sử dụng RDD, người dùng sẽ xem xét thủ công cách thể hiện tính toán song song một cách tối ưu.
Trong khi bộ nhớ đệm, nó tạo ra một bố cục tối ưu hơn. Spark biết cấu trúc của dữ liệu trong tập dữ liệu.
Nó cung cấp một giao diện duy nhất cho Java và Scala . Sự hợp nhất này đảm bảo chúng ta có thể sử dụng giao diện Scala, ví dụ mã từ cả hai ngôn ngữ. Nó cũng làm giảm gánh nặng của các thư viện. Vì các thư viện không còn phải xử lý hai loại đầu vào khác nhau.
| ĐỐI TƯỢNG SO SÁNH | RDD | DATAFRAME | DATASET |
|---|---|---|---|
| Phiên bản phát hành | 1.0 | 1.3 | 1.6 |
| Mô tả dữ liệu | Tập hợp phân tán các phần tử dữ liệu trải rộng trên nhiều máy trong cụm. RDD là một tập hợp các đối tượng Java hoặc Scala đại diện cho dữ liệu. | Tập hợp dữ liệu phân tán được tổ chức thành các cột được đặt tên. Về mặt khái niệm, nó giống như một bảng trong cơ sở dữ liệu quan hệ. | Phần mở rộng của API DataFrame cung cấp chức năng - giao diện lập trình hướng đối tượng, an toàn kiểu của API RDD và các lợi ích về hiệu suất của trình tối ưu hóa truy vấn Catalyst và cơ chế lưu trữ đống của API DataFrame. |
| Định dạng dữ liệu | Có thể dễ dàng và hiệu quả xử lý dữ liệu có cấu trúc cũng như không có cấu trúc. RDD không suy ra lược đồ của dữ liệu đã nhập và yêu cầu người dùng chỉ định | Chỉ hoạt động trên dữ liệu có cấu trúc và bán cấu trúc. Nó sắp xếp dữ liệu trong cột được đặt tên. DataFrames cho phép Spark quản lý lược đồ. | Xử lý dữ liệu có cấu trúc và phi cấu trúc một cách hiệu quả. Nó biểu diễn dữ liệu dưới dạng các đối tượng JVM của hàng hoặc một tập hợp các đối tượng hàng. Được biểu diễn dưới dạng bảng thông qua bộ mã hóa. |
| Tính bất biến và khả năng tương tác | RDDs chứa tập hợp các bản ghi được phân vùng. Đơn vị cơ bản của song song trong RDD được gọi là phân vùng. Mỗi phân vùng là một phân chia dữ liệu hợp lý không thay đổi và được tạo ra thông qua một số chuyển đổi trên các phân vùng hiện có. Tính bất biến giúp đạt được tính nhất quán trong tính toán. Chúng ta có thể di chuyển từ RDD sang DataFrame (Nếu RDD ở dạng bảng) bằng phương thức toDF () hoặc chúng ta có thể thực hiện ngược lại bằng phương thức ".rdd" . | Sau khi chuyển đổi thành DataFrame, người ta không thể tạo lại một đối tượng miền. Ví dụ: nếu tạo testDF từ testRDD, thì bạn sẽ không thể khôi phục RDD ban đầu của lớp thử nghiệm. | Nó khắc phục hạn chế của DataFrame để tạo lại RDD từ Dataframe. Cho phép bạn chuyển đổi RDD và DataFrames hiện có của mình thành Tập dữ liệu. |
| An toàn kiểu thời gian biên dịch | RDD cung cấp một phong cách lập trình hướng đối tượng quen thuộc với sự an toàn kiểu thời gian biên dịch. | Nếu cố gắng truy cập cột không tồn tại trong bảng, trong trường hợp đó, các API Dataframe không hỗ trợ lỗi thời gian biên dịch. Nó chỉ phát hiện lỗi thuộc tính trong thời gian chạy. | Cung cấp sự an toàn kiểu thời gian biên dịch. |
| Tối ưu hóa | Không có công cụ tối ưu hóa sẵn có trong RDD. Khi làm việc với dữ liệu có cấu trúc, RDD không thể tận dụng lợi thế của các trình tối ưu hóa nâng cao Spark. | Quá trình tối ưu hóa diễn ra bằng trình tối ưu hóa chất xúc tác. Khung dữ liệu sử dụng khung chuyển đổi cây xúc tác trong bốn giai đoạn: a) Phân tích một kế hoạch hợp lý để giải quyết các tham chiếu. b) Phương án lôgic tối ưu hóa. c) Lập kế hoạch vật lý. d) Tạo mã để biên dịch các phần của truy vấn sang mã bytecode của Java. | Nó bao gồm khái niệm về trình tối ưu hóa Dataframe Catalyst để tối ưu hóa kế hoạch truy vấn. |
| Thu gom rác | Có chi phí để thu thập rác do tạo và phá hủy các đối tượng riêng lẻ. | Tránh chi phí thu thập rác trong việc xây dựng các đối tượng riêng lẻ cho mỗi hàng trong tập dữ liệu. | Cũng không cần trình thu gom rác phá hủy đối tượng vì quá trình tuần tự hóa diễn ra thông qua Tungsten. Điều đó sử dụng tuần tự hóa dữ liệu đống. |
| Hiệu quả sử dụng bộ nhớ | Hiệu quả bị giảm khi tuần tự hóa được thực hiện riêng lẻ trên một đối tượng java và scala, điều này mất rất nhiều thời gian. | Sử dụng bộ nhớ heap off để tuần tự hóa làm giảm chi phí. Nó tạo mã byte động để có thể thực hiện nhiều thao tác trên dữ liệu được tuần tự hóa đó. Không cần deserialization cho các hoạt động nhỏ. | Cho phép thực hiện một hoạt động trên dữ liệu được tuần tự hóa và cải thiện việc sử dụng bộ nhớ. Vì vậy, nó cho phép truy cập theo yêu cầu vào thuộc tính riêng lẻ mà không cần giải mã hóa toàn bộ đối tượng. |
| Hỗ trợ ngôn ngữ lập trình | Các API RDD có sẵn bằng các ngôn ngữ Java, Scala, Python và R. Do đó, tính năng này cung cấp sự linh hoạt cho các nhà phát triển. | Nó cũng có các API bằng các ngôn ngữ khác nhau như Java, Python, Scala và R. | Các API tập dữ liệu hiện chỉ có sẵn trong Scala và Java. Phiên bản Spark 2.1.1 không hỗ trợ Python và R. |
| Tổng hợp | RDD API chậm hơn để thực hiện các hoạt động nhóm và tổng hợp đơn giản. | API DataFrame rất dễ sử dụng. Nó nhanh hơn cho phân tích khám phá, tạo thống kê tổng hợp trên các tập dữ liệu lớn. | Trong Dataset, thực hiện thao tác tổng hợp trên nhiều tập dữ liệu nhanh hơn. |
- https://www.tutorialspoint.com/apache_spark/apache_spark_rdd.htm
- https://www.edureka.co/blog/dataframes-in-spark
- http://www.gabormelli.com/RKB/Spark_RDD_Data_Structure
- https://data-flair.training/blogs/apache-spark-rdd-vs-dataframe-vs-dataset/
- Learning Spark by Materi Zaharia, Patrick Wendell, Andy Konwinski, Holden Karau