Materi 4 ‐ Penggabungan DataFrame, Penanganan Anomali, dan Encoding Data Kategorik - ThesionMS/Exploratory-Data-Analysis GitHub Wiki
DataFrame adalah struktur data yang digunakan dalam pemrograman untuk menyimpan data dalam bentuk tabel yang terstruktur dan dapat diakses dengan mudah. Di Python, DataFrame dapat dibuat menggunakan library pandas. Namun, seringkali kita perlu menggabungkan beberapa DataFrame yang berbeda untuk mendapatkan data yang lebih lengkap dan lebih bermakna.
Mengapa Menggabungkan DataFrame?
Saat bekerja dengan data, seringkali kita memerlukan data dari beberapa sumber yang berbeda. Kita mungkin memiliki data dari beberapa file yang berbeda, atau data yang berasal dari database yang berbeda. Dengan menggabungkan DataFrame, kita bisa menyatukan data dari berbagai sumber tersebut menjadi satu kesatuan yang lebih mudah diakses dan dikelola.
Cara Menggabungkan DataFrame
- Concatenation
- Merge
- Join
Kapan Menggunakan Metode Mana?
Pemilihan metode penggabungan DataFrame tergantung pada tujuan yang ingin dicapai dan karakteristik dari data yang ingin digabungkan. Metode concatenation cocok digunakan jika data yang ingin digabungkan memiliki struktur dan tipe data yang sama. Sedangkan, metode merge dan join lebih cocok digunakan jika data memiliki kolom yang berbeda tetapi terhubung oleh satu kolom yang sama.
Penggabungan DataFrame adalah proses yang penting dalam analisis data karena memungkinkan kita untuk menggabungkan data dari berbagai sumber menjadi satu kesatuan yang lebih lengkap dan bermakna. Dengan memahami metode-metode penggabungan yang tersedia dan kapan menggunakannya, kita dapat meningkatkan efisiensi dan akurasi analisis data kita.
1. Menggabungkan DataFrame dari Dataset dan Reshaping
1.1 Concatenation (Penggabungan) DataFrames
Concatenation adalah metode penggabungan DataFrame yang paling sederhana. Pada dasarnya, metode ini menyatukan DataFrame secara berdampingan atau vertical. Kita dapat menggunakan method concat dari library pandas untuk melakukannya. Namun, perlu diperhatikan bahwa DataFrame yang akan digabungkan harus memiliki kolom yang sama.

Contoh penggabungan dua dataframe menggunakan concat():
pd.concat([dataFrame1, dataFrame2], axis=1)
1.2 Merging DataFrames (Penggabungan dengan Merge)
Merge adalah metode penggabungan DataFrame yang lebih kompleks dan sering digunakan dalam analisis data. Metode ini memungkinkan kita untuk menggabungkan DataFrame berdasarkan nilai pada kolom tertentu. Sehingga kita dapat menggabungkan DataFrame yang memiliki kolom yang berbeda namun terhubung oleh satu kolom yang sama.

Berikut adalah beberapa contoh penggabungan DataFrames menggunakan fungsi merge:
Contoh 1: Menggabungkan dua dataframe berdasarkan kolom kunci
merged_df = df1.merge(df2, on='key_column')
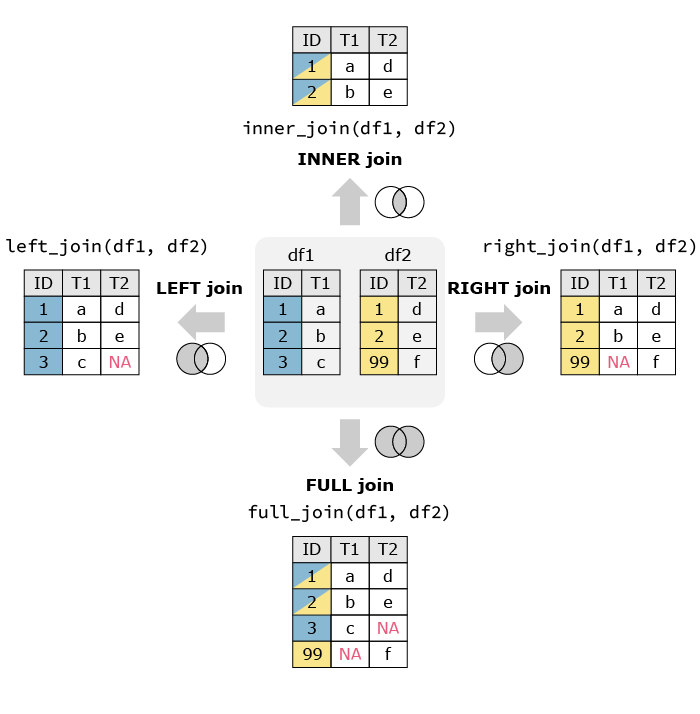
Contoh 2: Menggabungkan dua dataframe dengan inner join
merged_df = df1.merge(df2, how='inner', on='key_column')
Contoh 3: Menggabungkan dua dataframe dengan left join
merged_df = df1.merge(df2, how='left', on='key_column')
Contoh 4: Menggabungkan dua dataframe dengan right join
merged_df = df1.merge(df2, how='right', on='key_column')
Contoh 5: Menggabungkan dua dataframe dengan outer join
merged_df = df1.merge(df2, how='outer', on='key_column')
Harap dicatat bahwa fungsi merge() digunakan dari library pandas untuk menggabungkan dataframe. Argumen on='key_column' digunakan untuk menentukan kolom kunci yang akan digunakan sebagai basis penggabungan. Argumen how digunakan untuk menentukan jenis penggabungan (inner, left, right, atau outer join).
1.4 Penggunaan Groupby dalam Penggabungan
Ketika kita menggabungkan dua DataFrame, kemungkinan besar data akan tumpang tindih atau terjadi duplikasi. Hal ini dapat menyebabkan hasil yang tidak akurat atau bahkan salah. Dengan menggunakan groupby, kita dapat menghindari hal ini karena data akan dielompokkan berdasarkan kriteria tertentu sebelum digabungkan. Selain itu, penggunaan groupby juga dapat mempermudah dalam melakukan agregasi data, seperti melakukan penjumlahan atau rata-rata pada data yang sama.
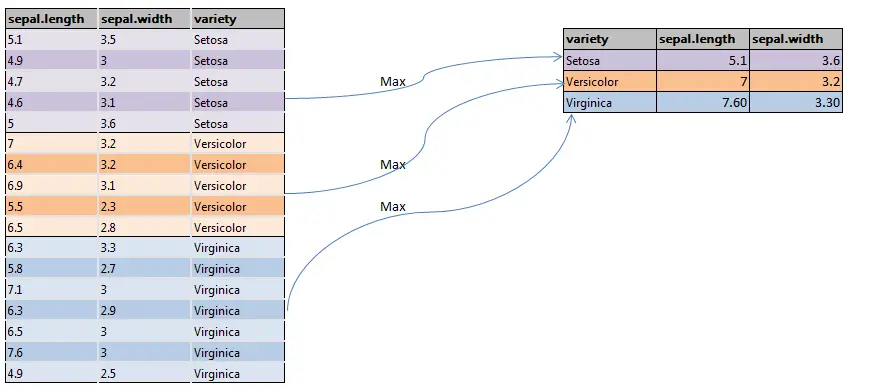
Berikut adalah beberapa contoh penggunaan fungsi groupby dalam penggabungan DataFrames:
Contoh 1: Mengelompokkan data berdasarkan kolom tertentu dan menghitung rata-rata
grouped_df = df.groupby('column_name').mean()
Contoh 2: Mengelompokkan data berdasarkan beberapa kolom dan menghitung jumlah
grouped_df = df.groupby(['column1', 'column2']).sum()
Contoh 3: Mengelompokkan data dan menerapkan fungsi kustom
grouped_df = df.groupby('column_name').apply(custom_function)
Contoh 4: Mengelompokkan data dan menghitung beberapa agregasi
grouped_df = df.groupby('column_name').agg(['sum', 'mean', 'count'])
Contoh 5: Mengelompokkan data dan mengubah urutan grup
grouped_df = df.groupby('column_name', sort=False).sum()
Harap dicatat bahwa fungsi groupby() digunakan dari library pandas untuk mengelompokkan data berdasarkan kolom tertentu. Fungsi agregasi seperti mean(), sum(), count(), dll. digunakan untuk menghitung statistik tertentu untuk setiap grup.
1.5 Pivot Table untuk Pivoting dan Unpivoting
Pivot dataframe merupakan teknik untuk merubah bentuk data yang awalnya berada pada baris menjadi berada pada kolom dan sebaliknya. Pengertian ini seringkali disebut juga sebagai pivoting dan unpivoting. Dengan menggunakan pivot dataframe, data yang tadinya sulit dibaca dan diolah dapat diubah menjadi lebih mudah dipahami dan diproses.

Untuk melakukan pivoting dataframe pada Pandas, terdapat dua metode yang dapat digunakan yaitu pivot() dan pivot_table(). Metode pivot() digunakan untuk mengubah bentuk data dari baris ke kolom tanpa ada perhitungan tambahan, sedangkan metode pivot_table() digunakan untuk mengubah bentuk data dengan melakukan pengelompokan berdasarkan nilai tertentu dari data yang ada.
Untuk melakukan unpivoting dataframe pada Pandas, kita dapat menggunakan metode melt(). Metode ini digunakan untuk mengubah bentuk data dari kolom ke baris dengan memecah data pada kolom-kolom tertentu menjadi beberapa baris. Dengan demikian, kita dapat melihat data yang tadinya terkonsentrasi menjadi lebih terurai sehingga lebih mudah diproses.
Berikut adalah beberapa contoh penggunaan pivot table untuk pivoting dan unpivoting DataFrames:
Contoh 1: Membuat pivot table
pivot_table = df.pivot_table(values='D', index=['A', 'B'], columns=['C'])
Contoh 2: Menggunakan fungsi agregasi dalam pivot table
pivot_table = df.pivot_table(values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum)
Contoh 3: Mengisi nilai yang hilang dalam pivot table
pivot_table = df.pivot_table(values='D', index=['A', 'B'], columns=['C'], fill_value=0)
Contoh 4: Unpivoting atau melebur pivot table
melted_df = pd.melt(df, id_vars=['A', 'B'], value_vars=['D'])
Harap dicatat bahwa fungsi pivot_table() digunakan dari library pandas untuk membuat pivot table. Argumen values digunakan untuk menentukan kolom yang akan dihitung, index digunakan untuk menentukan kolom yang akan menjadi indeks, dan columns digunakan untuk menentukan kolom yang akan menjadi kolom pivot table. Fungsi melt() digunakan untuk unpivoting atau melebur pivot table.
1.6 Reshaping DataFrame dengan Hierarchical Indexing (Stack dan Unstack)
Reshaping DataFrame dengan Hierarchical Indexing melibatkan penggunaan metode stack() dan unstack() dalam pandas. Metode ini memungkinkan kita untuk mengubah struktur DataFrame kita.
Metode stack() "menumpuk" kolom DataFrame menjadi baris, menghasilkan Series dengan MultiIndex. Indeks baru terbentuk dari indeks asli DataFrame ditambah dengan label kolom asli.
Metode unstack() adalah kebalikan dari stack(). Metode ini "membongkar" indeks menjadi kolom, menghasilkan DataFrame baru. Anda dapat memilih level indeks mana yang ingin Anda "unstack".
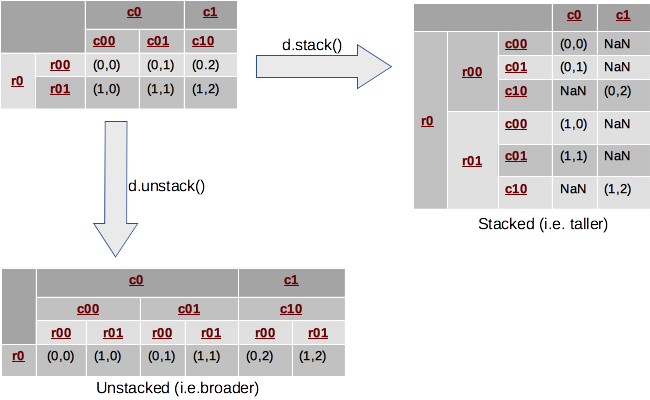
Berikut adalah beberapa contoh reshaping DataFrame dengan Hierarchical Indexing menggunakan fungsi stack dan unstack:
Contoh 1: Menggunakan fungsi stack untuk mengubah kolom menjadi baris
stacked_df = df.stack()
Contoh 2: Menggunakan fungsi unstack untuk mengubah baris menjadi kolom
unstacked_df = stacked_df.unstack()
Contoh 3: Menggunakan fungsi stack dengan level tertentu
stacked_df = df.stack(level=0)
Contoh 4: Menggunakan fungsi unstack dengan level tertentu
unstacked_df = stacked_df.unstack(level=0)
Harap dicatat bahwa fungsi stack() dan unstack() digunakan dari library pandas untuk reshaping DataFrame dengan Hierarchical Indexing. Argumen level digunakan untuk menentukan level indeks yang akan di-stack atau di-unstack.
2. Mengganti Nilai dalam DataFrame
2.1 Menggunakan Metode .replace() untuk Mengganti Nilai
Metode .replace() adalah metode yang digunakan dalam pandas untuk mengganti nilai tertentu dalam DataFrame atau Series. Metode ini sangat berguna ketika Anda ingin mengganti nilai tertentu dalam data Anda dengan nilai lain.
Berikut adalah contoh penggunaan metode .replace():
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [5, 15, -10, 20, 25],
'C': ['a', 'b', 'c', 'd', 'e']
})
# Mengganti nilai 5 di kolom 'B' dengan NaN
df['B'] = df['B'].replace(5, np.nan)
print(df)
Dalam contoh di atas, kita mengganti semua nilai 5 di kolom 'B' dengan nilai NaN. Anda juga dapat mengganti beberapa nilai sekaligus dengan memberikan list nilai yang ingin diganti dan list nilai penggantinya.
# Mengganti nilai 1 dan 2 di kolom 'A' dengan 100 dan 200
df['A'] = df['A'].replace([1, 2], [100, 200])
print(df)
Dalam contoh kedua, kita mengganti semua nilai 1 dan 2 di kolom 'A' dengan 100 dan 200 secara berturut-turut.
3. Menangani Data yang Hilang (Missing Value)
Data yang hilang (missing value) adalah data yang tidak tersedia atau tidak lengkap dalam suatu dataset. Ketika data tersebut diabaikan, maka bisa menyebabkan bias pada analisis data dan menghasilkan kesimpulan yang tidak akurat. Oleh karena itu, penting untuk menangani data yang hilang dengan cara yang tepat.
3.1 Mengecek Data yang Hilang dengan isnull() dan notnull()
Metode isnull() dan notnull() adalah metode yang digunakan dalam pandas untuk mengecek data yang hilang atau missing values dalam DataFrame atau Series.
Metode isnull() mengembalikan DataFrame boolean yang sama dengan DataFrame asli dan menggantikan setiap nilai dengan True jika nilai tersebut hilang dan False jika tidak.
Contoh penggunaan isnull():
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, 15, np.nan, 20, 25],
'C': ['a', 'b', 'c', 'd', 'e']
})
# Mengecek data yang hilang
print(df.isnull())
Metode notnull() adalah kebalikan dari isnull(). Metode ini mengembalikan True untuk nilai yang tidak hilang dan False untuk nilai yang hilang.
Contoh penggunaan notnull():
# Mengecek data yang tidak hilang
print(df.notnull())
3.2 Menghitung Total Data yang Hilang dengan isnull().sum()
Metode isnull().sum() digunakan dalam pandas untuk menghitung total data yang hilang atau missing values dalam DataFrame atau Series. Metode isnull() mengembalikan DataFrame boolean yang sama dengan DataFrame asli dan menggantikan setiap nilai dengan True jika nilai tersebut hilang dan False jika tidak. Kemudian, metode sum() digunakan untuk menghitung jumlah True dalam DataFrame tersebut, yang mewakili jumlah total data yang hilang.
Berikut adalah contoh penggunaan isnull().sum():
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, 15, np.nan, 20, 25],
'C': ['a', 'b', 'c', 'd', 'e']
})
# Menghitung total data yang hilang
print(df.isnull().sum())
Dalam contoh di atas, kita menghitung jumlah total data yang hilang dalam setiap kolom DataFrame.
3.3 Menghapus Baris atau Kolom dengan Data Hilang Menggunakan dropna()
Metode dropna() adalah metode yang digunakan dalam pandas untuk menghapus baris atau kolom dengan data yang hilang atau missing values dalam DataFrame atau Series. Metode ini sangat berguna ketika Anda ingin membersihkan data Anda dari missing values.
Berikut adalah contoh penggunaan dropna():
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, 15, np.nan, 20, 25],
'C': ['a', 'b', 'c', 'd', 'e']
})
# Menghapus baris dengan data yang hilang
df_no_missing_values = df.dropna()
print(df_no_missing_values)
Dalam contoh di atas, kita menghapus semua baris yang memiliki setidaknya satu nilai NaN.
Anda juga dapat menghapus kolom yang memiliki setidaknya satu nilai NaN dengan memberikan argumen axis=1 ke metode dropna():
# Menghapus kolom dengan data yang hilang
df_no_missing_values = df.dropna(axis=1)
print(df_no_missing_values)
Dalam contoh kedua, kita menghapus semua kolom yang memiliki setidaknya satu nilai NaN.
3.4 Menggunakan Opsi how pada dropna(): 'all' dan 'any'
Metode dropna() dalam pandas digunakan untuk menghapus baris atau kolom dengan data yang hilang atau missing values dalam DataFrame atau Series. Opsi how pada dropna() menentukan bagaimana cara menghapus baris atau kolom tersebut.
Opsi how='all' akan menghapus baris atau kolom jika semua datanya adalah missing values.
Contoh penggunaan how='all':
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, np.nan],
'B': [5, np.nan, np.nan, np.nan],
'C': ['a', np.nan, np.nan, np.nan]
})
# Menghapus baris dengan semua data yang hilang
df_all = df.dropna(how='all')
print(df_all)
Dalam contoh di atas, baris kedua, ketiga, dan keempat dihapus karena semua datanya adalah missing values.
Opsi how='any' akan menghapus baris atau kolom jika setidaknya satu datanya adalah missing value. Ini adalah opsi default pada dropna().
Contoh penggunaan how='any':
# Menghapus baris dengan setidaknya satu data yang hilang
df_any = df.dropna(how='any')
print(df_any)
Dalam contoh kedua, hanya baris pertama yang tetap karena tidak ada missing values.
3.5 Menghapus Data Hilang dengan loc dan iloc
Metode loc dan iloc dalam pandas digunakan untuk mengakses sekelompok baris dan kolom dalam DataFrame. Metode loc digunakan untuk mengakses berdasarkan label, sedangkan iloc digunakan untuk mengakses berdasarkan posisi integer.
Namun, metode loc dan iloc sendiri tidak digunakan untuk menghapus data yang hilang. Untuk menghapus data yang hilang, Anda dapat menggunakan metode dropna(). Namun, Anda dapat menggunakan loc atau iloc untuk memilih baris atau kolom tertentu yang tidak memiliki nilai yang hilang.
Berikut adalah contoh penggunaan loc dan iloc untuk memilih baris atau kolom tanpa nilai yang hilang:
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, 15, np.nan, 20, 25],
'C': ['a', 'b', 'c', 'd', 'e']
})
# Menggunakan loc untuk memilih baris tanpa nilai yang hilang di kolom 'A'
df_no_missing_values_A = df.loc[df['A'].notnull()]
print(df_no_missing_values_A)
# Menggunakan iloc untuk memilih baris tanpa nilai yang hilang di kolom pertama
df_no_missing_values_first_column = df.iloc[df.iloc[:, 0].notnull().values]
print(df_no_missing_values_first_column)
Dalam contoh di atas, kita menggunakan loc dan iloc untuk memilih baris yang tidak memiliki nilai yang hilang di kolom tertentu.
4. Pengisian Data yang Hilang (Missing Value)
4.1 Mengisi Data yang Hilang dengan Nilai Rata-Rata, Median dan Modus
Metode fillna() dalam pandas digunakan untuk mengisi data yang hilang atau missing values dalam DataFrame atau Series. Anda dapat mengisi missing values dengan nilai rata-rata (mean), median, atau mode dari kolom tersebut.
Berikut adalah contoh penggunaan fillna():
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, 15, np.nan, 20, 25],
'C': ['a', 'b', 'c', 'd', 'e']
})
# Mengisi data yang hilang dengan nilai rata-rata (mean)
df['A'] = df['A'].fillna(df['A'].mean())
df['B'] = df['B'].fillna(df['B'].mean())
print(df)
Dalam contoh di atas, kita mengisi semua missing values di kolom 'A' dan 'B' dengan nilai rata-rata dari kolom tersebut.
Anda juga dapat mengisi missing values dengan median atau mode:
# Mengisi data yang hilang dengan median
df['A'] = df['A'].fillna(df['A'].median())
df['B'] = df['B'].fillna(df['B'].median())
# Mengisi data yang hilang dengan mode
df['C'] = df['C'].fillna(df['C'].mode())
print(df)
Dalam contoh kedua, kita mengisi semua missing values di kolom 'A' dan 'B' dengan median dan di kolom 'C' dengan mode.
4.2 Mengisi Data yang Hilang dengan Nilai Tertentu (e.g., 0)
Metode fillna() dalam pandas digunakan untuk mengisi data yang hilang atau missing values dalam DataFrame atau Series. Anda dapat mengisi missing values dengan nilai tertentu, seperti 0.
Berikut adalah contoh penggunaan fillna() untuk mengisi missing values dengan 0:
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, 15, np.nan, 20, 25],
'C': ['a', 'b', 'c', 'd', 'e']
})
# Mengisi data yang hilang dengan 0
df_filled = df.fillna(0)
print(df_filled)
Dalam contoh di atas, kita mengisi semua missing values di DataFrame dengan 0.
4.3 Menggunakan Forward dan Backward Filling untuk Data yang Hilang
Forward filling dan backward filling adalah teknik yang digunakan dalam pandas untuk mengisi data yang hilang atau missing values dalam DataFrame atau Series. Forward filling (metode 'ffill') mengisi missing values dengan nilai sebelumnya dalam kolom atau baris, sedangkan backward filling (metode 'bfill') mengisi missing values dengan nilai berikutnya dalam kolom atau baris.
Berikut adalah contoh penggunaan forward filling dan backward filling:
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, 15, np.nan, 20, 25],
'C': ['a', 'b', 'c', 'd', 'e']
})
# Mengisi data yang hilang dengan forward filling
df_ffill = df.fillna(method='ffill')
print(df_ffill)
# Mengisi data yang hilang dengan backward filling
df_bfill = df.fillna(method='bfill')
print(df_bfill)
Dalam contoh di atas, kita mengisi semua missing values di DataFrame dengan forward filling dan backward filling.
5. Mendeteksi Data Anomali (Outlier)
Deteksi data anomali atau outlier adalah proses identifikasi item, observasi, atau titik data yang berbeda secara signifikan dari sebagian besar data yang diamati. Outlier dapat menunjukkan kesalahan pengukuran, variasi dalam data, atau kejadian yang tidak biasa. Dalam analisis data, outlier dapat mempengaruhi hasil dan dapat menyebabkan bias dalam estimasi statistik.
Berikut adalah contoh kodingan untuk mendeteksi outlier menggunakan metode IQR (Interquartile Range):
import pandas as pd
import numpy as np
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 100]
})
# Menghitung IQR
Q1 = df['A'].quantile(0.25)
Q3 = df['A'].quantile(0.75)
IQR = Q3 - Q1
# Mendefinisikan aturan untuk outlier
filter = (df['A'] >= Q1 - 1.5 * IQR) & (df['A'] <= Q3 + 1.5 *IQR)
# Menerapkan filter untuk DataFrame
df_no_outlier = df.loc[filter]
print(df_no_outlier)
5.1 Normalisasi Data
Normalisasi data adalah teknik yang digunakan untuk mengubah nilai dalam dataset ke skala yang sama. Teknik ini sangat berguna ketika dataset berisi kolom yang memiliki rentang nilai yang berbeda, dan biasanya digunakan dalam algoritma machine learning yang memerlukan semua input memiliki rentang yang sama.
Berikut adalah contoh kodingan untuk normalisasi data:
from sklearn.preprocessing import MinMaxScaler
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
})
# Membuat scaler
scaler = MinMaxScaler()
# Mengubah kolom 'A' menjadi array 2D dan melakukan fit_transform
df['A'] = scaler.fit_transform(df['A'](/ThesionMS/Exploratory-Data-Analysis/wiki/'A'))
print(df)
Dalam contoh di atas, kita menggunakan MinMaxScaler dari library sklearn.preprocessing untuk melakukan normalisasi data. MinMaxScaler mengubah fitur dengan menskalakan setiap fitur ke rentang yang diberikan (defaultnya adalah 0 dan 1).
5.2 Standarisasi Data
Standarisasi data adalah proses mengubah data menjadi skala standar, yaitu dengan rata-rata 0 dan standar deviasi 1. Teknik ini berguna ketika kita ingin membandingkan data yang memiliki unit atau skala yang berbeda.
Berikut adalah contoh kodingan untuk standarisasi data:
from sklearn.preprocessing import StandardScaler
# Membuat DataFrame
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
})
# Membuat scaler
scaler = StandardScaler()
# Mengubah kolom 'A' menjadi array 2D dan melakukan fit_transform
df['A'] = scaler.fit_transform(df['A'](/ThesionMS/Exploratory-Data-Analysis/wiki/'A'))
print(df)
Dalam contoh di atas, kita menggunakan StandardScaler dari library sklearn.preprocessing untuk melakukan standarisasi data. StandardScaler mengubah fitur dengan menghapus mean dan menskalakan ke varians unit.
6. Encoding Data Kategorik Menjadi Numerik
6.1 Penggunaan One-Hot Encoding untuk Mengubah Data Kategorik Menjadi Numerik
Encoding data kategorik menjadi numerik adalah proses mengubah variabel kategorik menjadi format yang dapat disediakan ke algoritma machine learning untuk melakukan prediksi yang lebih baik. Ada banyak teknik yang dapat digunakan untuk mengubah data kategorik menjadi numerik, salah satunya adalah One-Hot Encoding.
One-Hot Encoding adalah proses di mana variabel kategorik dikonversi menjadi bentuk yang dapat disediakan ke algoritma ML untuk melakukan prediksi yang lebih baik. Dengan One-Hot, kita membuat satu kolom baru untuk setiap nilai unik dalam kolom kategorik. Untuk setiap baris dalam dataset, nilai kolom baru akan 1 jika nilai aslinya sama dengan kolom tersebut dan 0 jika tidak.
Berikut adalah contoh penggunaan One-Hot Encoding:
import pandas as pd
# Membuat DataFrame
df = pd.DataFrame({
'A': ['a', 'b', 'a'],
'B': ['b', 'a', 'c']
})
# Melakukan One-Hot Encoding
df_encoded = pd.get_dummies(df, prefix=['col_A', 'col_B'])
print(df_encoded)
Dalam contoh di atas, kita menggunakan fungsi get_dummies() dari pandas untuk melakukan One-Hot Encoding. Fungsi ini membuat DataFrame baru dengan kolom biner untuk setiap kategori/nilai unik dalam kolom asli.
Referensi: McKinney, W. (2012). Python for Data Analysis. O'Reilly Media, Inc. VanderPlas, J. (2016). Python Data Science Handbook. O'Reilly Media, Inc. Grus, J. (2015). Data Science from Scratch. O'Reilly Media, Inc.