Materi 1 ‐ Analisis dan Eksplorasi Data - ThesionMS/Exploratory-Data-Analysis GitHub Wiki
1. Teknik Dasar Eksplorasi Data
Exploratory Data Analysis (EDA) adalah proses pemeriksaan dataset yang tersedia untuk menemukan pola, mendeteksi anomali, menguji hipotesis, dan memeriksa asumsi menggunakan ukuran statistik. EDA merupakan langkah awal sebelum melakukan pemodelan formal atau formulasi hipotesis. Tujuan utama dari EDA adalah untuk memahami apa yang dapat dikatakan oleh data sebelum melakukan analisis lebih lanjut.
Berdasarkan buku "Hands-On Exploratory Data Analysis with Python" oleh Suresh Kumar Mukhiya dan Usman Ahmed, terdapat beberapa teknik dasar dalam Exploratory Data Analysis (EDA) yang dapat digunakan untuk menganalisis data. Berikut adalah penjelasan mengenai beberapa teknik dasar EDA:
-
Profil Data: Teknik ini melibatkan pemahaman mendalam tentang dataset yang ada, termasuk jumlah variabel, tipe data, dan statistik deskriptif seperti mean, median, dan standar deviasi. Profil data membantu dalam mengidentifikasi anomali atau kesalahan dalam dataset.
-
Visualisasi Data : Teknik ini melibatkan penggunaan grafik dan plot untuk memvisualisasikan data. Visualisasi data membantu dalam memahami pola, hubungan, dan tren dalam dataset. Beberapa jenis visualisasi yang umum digunakan dalam EDA adalah histogram, scatter plot, dan box plot .
-
Analisis Statistik: Teknik ini melibatkan penggunaan metode statistik untuk menganalisis data. Analisis statistik dapat melibatkan perhitungan ukuran pemusatan data seperti mean dan median, ukuran penyebaran data seperti rentang dan variansi, serta uji hipotesis untuk menguji asumsi tentang data .
-
Penilaian Kualitas Data : Teknik ini melibatkan evaluasi kualitas data, termasuk keberadaan data yang hilang, duplikat, atau tidak valid. Penilaian kualitas data penting untuk memastikan keandalan dan keakuratan hasil analisis .
2. Peran Eksplorasi Data Dalam Penyajian & Analisis

Berdasarkan buku "Think Stats: Exploratory Data Analysis," Eksplorasi Data (Exploratory Data Analysis/EDA) memiliki peran penting dalam penyajian dan analisis data. Berikut adalah penjelasan mengenai peran EDA dalam penyajian dan analisis data:
-
Penyajian Data: EDA membantu dalam penyajian data dengan menggunakan teknik visualisasi seperti grafik dan plot. Visualisasi data memungkinkan kita untuk memahami data dengan lebih baik dan membuatnya lebih mudah dipahami oleh orang lain. Dengan menggunakan grafik dan plot, kita dapat menggambarkan pola, hubungan, dan tren dalam data secara visual. Hal ini membantu dalam mengkomunikasikan hasil analisis kepada pemangku kepentingan (stakeholders) dengan cara yang lebih jelas dan efektif .
-
Analisis Data: EDA membantu dalam analisis data dengan mengungkapkan pola, hubungan, dan tren yang ada dalam dataset. Dengan menggunakan teknik dasar EDA seperti profil data, analisis statistik, dan visualisasi data, kita dapat mengidentifikasi karakteristik data, menemukan pola atau hubungan antar variabel, dan mengidentifikasi anomali atau kesalahan dalam dataset. Analisis data yang dilakukan melalui EDA membantu dalam mengambil keputusan yang lebih baik dan memberikan wawasan yang lebih dalam tentang data yang ada.
3. Langkah-langkah Eksplorasi Data

Berikut adalah langkah-langkah EDA :
-
Problem Definition: Langkah pertama dalam EDA adalah mendefinisikan masalah yang akan diselesaikan. Hal ini meliputi tujuan, hasil yang diharapkan, peran dan tanggung jawab tim, situasi saat ini, jangka waktu, serta biaya dan manfaat yang terkait.
-
Data Preparation: Langkah selanjutnya adalah mempersiapkan dan mengenal data yang akan digunakan. Hal ini meliputi mengumpulkan data, mengkategorikan data, membersihkan data dari kesalahan atau duplikasi, menghapus data yang tidak diperlukan, mentransformasi data jika diperlukan, dan mempartisi data menjadi subset yang relevan .
-
Data Analysis, Modelling, Evaluation: Langkah ini melibatkan tiga tugas utama dalam analisis data. Pertama, merangkum data untuk memahami karakteristiknya. Kedua, mencari hubungan atau pola tersembunyi dalam data. Ketiga, membuat prediksi berdasarkan data yang ada. Metode yang digunakan dalam langkah ini antara lain tabel ringkasan, grafik, statistik deskriptif, statistik inferensial, statistik korelasi, pencarian data, pengelompokan data, dan pemodelan matematika.
-
Deployment: Langkah terakhir adalah merencanakan dan melaksanakan implementasi berdasarkan definisi masalah yang telah ditetapkan. Setelah implementasi, langkah ini juga melibatkan pengukuran dan pemantauan kinerja hasil yang telah dicapai serta melakukan evaluasi terhadap proyek yang telah dilakukan.
Berikut adalah langkah-langkah EDA menggunakan pandas:
-
Import data ke dalam lingkungan kerja (Jupyter notebook, Google Colab, Python IDE): Langkah pertama dalam EDA adalah mengimpor data ke dalam lingkungan kerja yang akan digunakan. Misalnya, jika menggunakan Jupyter notebook, kita dapat menggunakan fungsi
read_csv()dari pandas untuk mengimpor data dari file CSV. Berikut adalah contoh kode:import pandas as pd # Mengimpor data dari file CSV data = pd.read_csv('nama_file.csv') -
Statistik deskriptif: Setelah data diimpor, langkah selanjutnya adalah melakukan analisis statistik deskriptif untuk memahami karakteristik data. Pandas menyediakan fungsi-fungsi seperti
describe(),mean(),median(),min(),max(), dan lainnya untuk menghitung statistik deskriptif dari data. Berikut adalah contoh kode:# Menampilkan ringkasan statistik deskriptif print(data.describe()) # Menghitung rata-rata print(data.mean()) # Menghitung median print(data.median()) # Menghitung nilai minimum print(data.min()) # Menghitung nilai maksimum print(data.max()) -
Menghapus data yang kosong: Selanjutnya, kita perlu menghapus atau mengisi nilai yang kosong atau null dalam data. Pandas menyediakan fungsi
dropna()untuk menghapus baris atau kolom yang mengandung nilai null. Berikut adalah contoh kode:# Menghapus baris yang mengandung nilai null data_cleaned = data.dropna() # Menghapus kolom yang mengandung nilai null data_cleaned = data.dropna(axis=1) -
Visualisasi: Langkah terakhir dalam EDA adalah melakukan visualisasi data untuk memahami pola dan hubungan antar variabel. Pandas memiliki integrasi dengan paket visualisasi seperti Matplotlib dan Seaborn. Berikut adalah contoh kode untuk membuat beberapa jenis plot:
a. Univariate Visualization: Untuk memvisualisasikan distribusi variabel tunggal, kita dapat menggunakan histogram, box plot, atau bar plot. Berikut adalah contoh kode:
import matplotlib.pyplot as plt
import seaborn as sns
# Histogram
plt.hist(data['variabel'], bins=10)
plt.xlabel('Variabel')
plt.ylabel('Frekuensi')
plt.title('Histogram Variabel')
plt.show()
# Box plot
sns.boxplot(data['variabel'])
plt.xlabel('Variabel')
plt.title('Box Plot Variabel')
plt.show()
# Bar plot
sns.countplot(data['variabel'])
plt.xlabel('Variabel')
plt.ylabel('Frekuensi')
plt.title('Bar Plot Variabel')
plt.show()
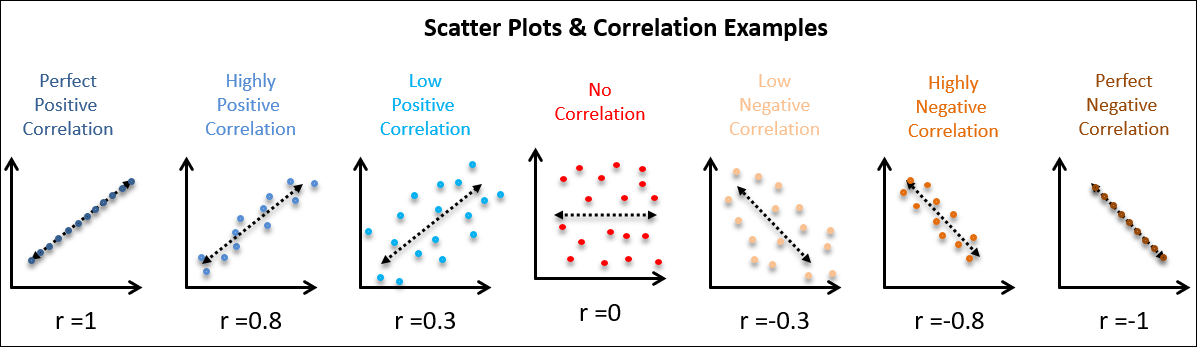
b. Multivariate Visualization: Untuk memvisualisasikan hubungan antara dua atau lebih variabel, kita dapat menggunakan scatter plot, heatmap, atau pair plot. Berikut adalah contoh kode:
# Scatter plot
plt.scatter(data['variabel1'], data['variabel2'])
plt.xlabel('Variabel 1')
plt.ylabel('Variabel 2')
plt.title('Scatter Plot Variabel 1 dan Variabel 2')
plt.show()
# Heatmap
correlation_matrix = data.corr()
sns.heatmap(correlation_matrix, annot=True)
plt.title('Heatmap Korelasi Variabel')
plt.show()
# Pair plot
sns.pairplot(data)
plt.show()
4. Grafik Visual Eksplorasi Data
4.1 Pie Chart
Metrik pada pie chart adalah proporsi atau persentase dari setiap kategori dalam dataset. Pie chart digunakan untuk memvisualisasikan bagaimana setiap kategori berkontribusi terhadap keseluruhan.
Berikut adalah contoh kode untuk membuat pie chart menggunakan library matplotlib:
import matplotlib.pyplot as plt
# Data
labels = ['Kategori 1', 'Kategori 2', 'Kategori 3']
sizes = [30, 40, 30] # Proporsi atau persentase dari setiap kategori
# Pie chart
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
plt.title('Pie Chart Kategori')
plt.show()

Dalam contoh di atas, labels adalah daftar label untuk setiap kategori, dan sizes adalah daftar proporsi atau persentase dari setiap kategori. Fungsi plt.pie() digunakan untuk membuat pie chart dengan menggunakan data tersebut. Parameter labels digunakan untuk menampilkan label pada setiap bagian pie chart, sedangkan parameter autopct digunakan untuk menampilkan persentase pada setiap bagian pie chart.
4.2 Bar Chart
Metrik pada bar chart adalah jumlah atau frekuensi dari setiap kategori dalam dataset. Bar chart digunakan untuk memvisualisasikan perbandingan antara kategori-kategori yang berbeda.
Berikut adalah contoh kode untuk membuat bar chart menggunakan library matplotlib:
import matplotlib.pyplot as plt
# Data
categories = ['Kategori 1', 'Kategori 2', 'Kategori 3']
values = [10, 20, 15] # Jumlah atau frekuensi dari setiap kategori
# Bar chart
plt.bar(categories, values)
plt.xlabel('Kategori')
plt.ylabel('Jumlah')
plt.title('Bar Chart Kategori')
plt.show()

Dalam contoh di atas, categories adalah daftar kategori yang akan ditampilkan di sumbu x, dan values adalah daftar jumlah atau frekuensi dari setiap kategori yang akan ditampilkan di sumbu y. Fungsi plt.bar() digunakan untuk membuat bar chart dengan menggunakan data tersebut. Parameter xlabel dan ylabel digunakan untuk memberikan label pada sumbu x dan y, sedangkan parameter title digunakan untuk memberikan judul pada bar chart.
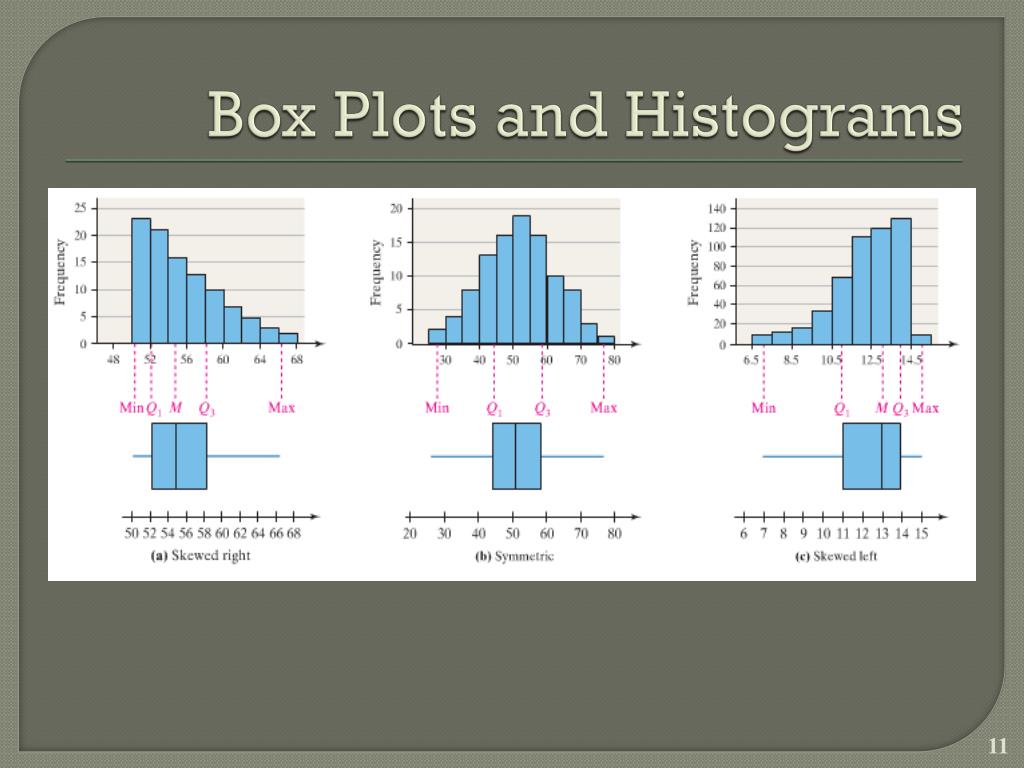
4.3 Boxplot
Metrik pada boxplot adalah rangkaian statistik yang digunakan untuk menggambarkan distribusi data. Boxplot memberikan informasi tentang median, kuartil, rentang interkuartil, serta adanya outlier dalam data.
Berikut adalah contoh kode untuk membuat boxplot menggunakan library matplotlib:
import matplotlib.pyplot as plt
# Data
data = [10, 15, 20, 25, 30, 35, 40, 45, 50]
# Boxplot
plt.boxplot(data)
plt.xlabel('Data')
plt.ylabel('Nilai')
plt.title('Boxplot Data')
plt.show()


Dalam contoh di atas, data adalah daftar nilai yang akan digunakan untuk membuat boxplot. Fungsi plt.boxplot() digunakan untuk membuat boxplot dengan menggunakan data tersebut. Parameter xlabel dan ylabel digunakan untuk memberikan label pada sumbu x dan y, sedangkan parameter title digunakan untuk memberikan judul pada boxplot.
4.4 Histogram
Metrik pada histogram adalah frekuensi atau jumlah kemunculan suatu nilai dalam dataset. Histogram digunakan untuk memvisualisasikan distribusi data dan memberikan informasi tentang frekuensi relatif dari setiap nilai.
Berikut adalah contoh kode untuk membuat histogram menggunakan library matplotlib:
import matplotlib.pyplot as plt
# Data
data = [10, 15, 20, 25, 30, 35, 40, 45, 50]
# Histogram
plt.hist(data, bins=5)
plt.xlabel('Data')
plt.ylabel('Frekuensi')
plt.title('Histogram Data')
plt.show()
Dalam contoh di atas, data adalah daftar nilai yang akan digunakan untuk membuat histogram. Fungsi plt.hist() digunakan untuk membuat histogram dengan menggunakan data tersebut. Parameter bins digunakan untuk menentukan jumlah interval atau kelas dalam histogram. Parameter xlabel dan ylabel digunakan untuk memberikan label pada sumbu x dan y, sedangkan parameter title digunakan untuk memberikan judul pada histogram.
Contoh Histogram :

5. Paket dalam software yang mampu digunakan dalam proses visualisasi data
Dalam proses visualisasi data, terdapat beberapa paket dalam software yang dapat digunakan, antara lain:
-
Matplotlib: Matplotlib adalah salah satu paket visualisasi data yang paling populer dalam bahasa pemrograman Python. Paket ini menyediakan berbagai jenis plot dan grafik yang dapat digunakan untuk memvisualisasikan data secara interaktif. Matplotlib dapat digunakan untuk membuat plot garis, scatter plot, histogram, box plot, dan masih banyak lagi.
-
Seaborn: Seaborn adalah paket visualisasi data yang dibangun di atas Matplotlib. Paket ini menyediakan antarmuka yang lebih sederhana dan intuitif untuk membuat plot yang menarik dan informatif. Seaborn memiliki fitur-fitur seperti pemetaan warna otomatis, plot kategorikal yang lebih baik, dan dukungan untuk plot multivariat.
-
Plotly: Plotly adalah paket visualisasi data yang kuat dan interaktif. Paket ini memungkinkan pengguna untuk membuat plot yang dapat diinteraksikan, seperti plot yang dapat digerakkan, zoom, dan memperlihatkan detail saat diarahkan. Plotly juga menyediakan fitur kolaborasi yang memungkinkan pengguna untuk berbagi plot dengan orang lain secara online.
-
ggplot: ggplot adalah paket visualisasi data yang dibangun di atas bahasa pemrograman R. Paket ini mengadopsi gaya pemrograman yang konsisten dengan tata letak grammar of graphics, yang memungkinkan pengguna untuk membuat plot dengan sintaks yang mudah dipahami dan fleksibel. ggplot menyediakan berbagai jenis plot seperti scatter plot, bar plot, dan line plot.
-
Tableau: Tableau adalah perangkat lunak visualisasi data yang populer dan kuat. Perangkat lunak ini menyediakan antarmuka yang intuitif dan mudah digunakan untuk membuat visualisasi data yang menarik dan interaktif. Tableau juga memiliki fitur-fitur analisis yang kuat, seperti pemodelan prediktif dan integrasi dengan sumber data yang berbeda.