使用说明 | ASR 测试集制作 - TencentCloudAIGroup/aistudio GitHub Wiki
ASR 测试集,包含两部分内容:音频文件,以及与之对应的标注文本文件
一、测试集模板
测试集模板可通过如下链接下载(提供中英文模板)
打开模板,可以看到
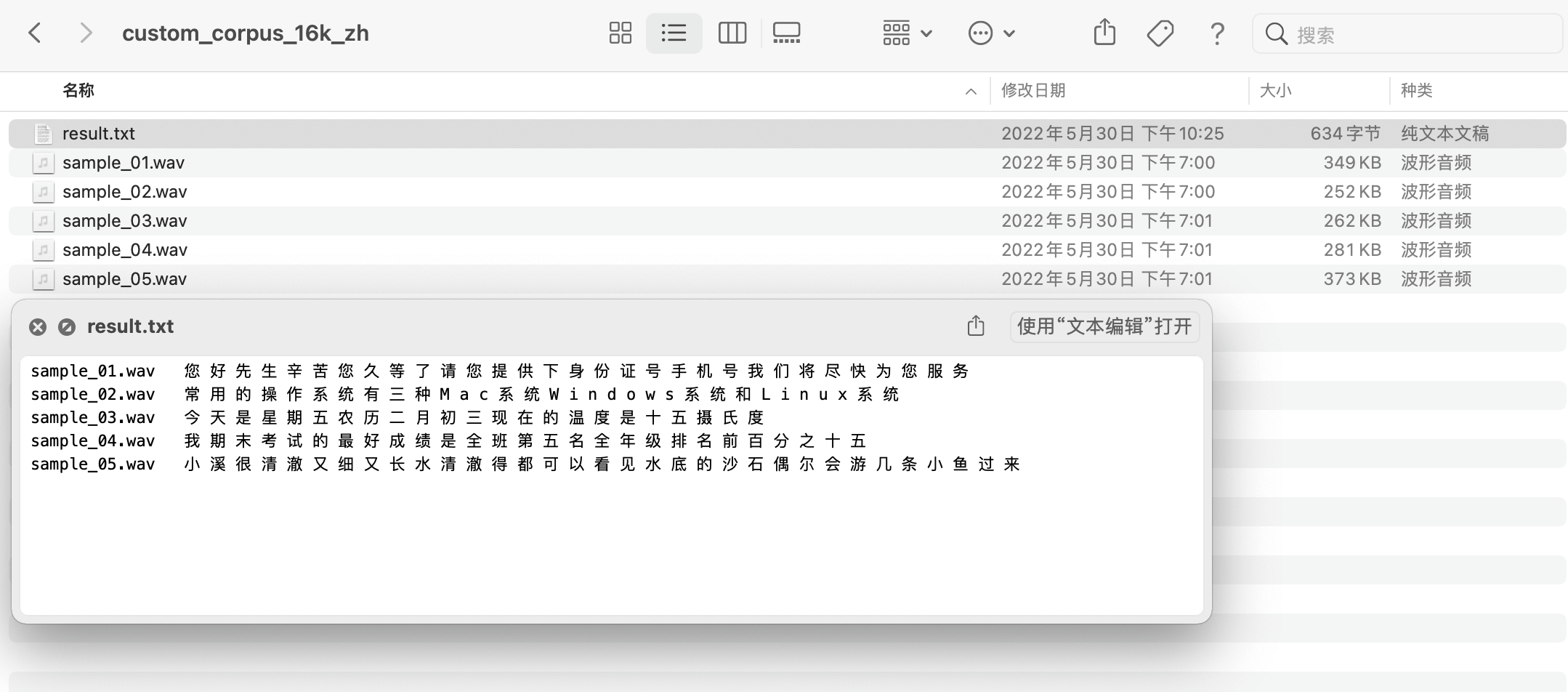
该测试集包含 5 个测试样例,共计 6 个文件
音频文件:sample_01.wav 到 sample_05.wav
标注文件:result.txt
其中标注文件 result.txt 中包含每个音频对应的语音内容。
二、音频文件
音频文件,即为用户业务侧使用的音频。
为使评测报告为精确地反映用户业务环境的效果,建议尽量选择_线上实际的音频数据_。
关于音频本身,需要满足如下要求
| 音频信息 | 要求 |
|---|---|
| 格式 | 支持 wav 格式 |
| 采样率 | 支持 16k/8k 两种采样率 |
| 声道 | 支持单声道 |
| 位深 | 支持 16 bit 位深 |
用户可以使用常用音频处理软件查看音频相关元信息,如 FFmpeg, Adobe Audition 等,在 Linux 系统中,用户也可以使用 file 命令查看

注:其中 mono 即为单声道。
若音频不满足要求,建议通过 FFmpeg 开源工具,对音频进行转码等处理。参见:Download FFmpeg
三、标注文件
标注数据,即通过人工的方式,将音频中实际包含的语音内容,按照特定格式,标注到文本文件中。
ASR 效果指标(例如 WER、字正确率等),就是通过对比 ASR 识别结果和标注数据,找到其中的各类错误(替换/插入/删除)所占的比例,计算得出的百分比。
可见,标注数据是否准确,直接关系到 ASR 效果指标的准确性。
下面我们看下,标注数据的格式是什么样的,以及在标注过程中需要的注意事项。
3.1 标注文件

通过上面模板可见,标注数据是一个文本文件,包含多行数据。
每行包含两部分:音频文件名、音频文件对应的文本内容,中间用空格分开(空格数不限制)
文件要求如下:
| 文件信息 | 要求 |
|---|---|
| 格式 | .txt |
| 编码 | utf-8编码 |
| 文件名 | 必须为 result.txt |
3.2 标注文本
标注文本,即通过人工听的方式,将业务音频中包含的人声发音内容,记录到标注文件中。
标注过程需注意以下事项:
- 文本需要以空格分开,中文按照字符分割,英文按照单词分割
- 文本不包含标点符号,仅保留发音文字内容
- 数字,需要标识为中文大写形式,例如文本“小明考了98分”,需要标注为“小明考了九十八分”
- 发音不完整,比如某个字发音发了一半,但没有完全发出来,需要把没完全发音的字写出来
- 笑声,如果发出笑声哈哈哈,有几个哈声就转写几个哈
- 语气词,如呀、啊等,需要原样录入,不可以删除
- 重复词,语需要如实转写,例如“我的我的作业没交”
- 儿化音需要把“儿”字写出来
- 脏话需如实转写
- 音频中出现 ta 时,需要根据语境标注对应的 ta(他、她、它);如果不能分辨,统一用“他”
附录
- 中文16k测试集模板:https://iai-frontend-static-1258344699.cos.ap-guangzhou.myqcloud.com/custom_corpus_16k_zh.zip
- 中文8k测试集模板:https://iai-frontend-static-1258344699.cos.ap-guangzhou.myqcloud.com/custom_corpus_8k_zh.zip
- 英文16k测试集模板:https://iai-frontend-static-1258344699.cos.ap-guangzhou.myqcloud.com/custom_corpus_16k_en.zip
- 英文8k测试集模板:https://iai-frontend-static-1258344699.cos.ap-guangzhou.myqcloud.com/custom_corpus_8k_en.zip