computing_template - TaiBON/portal_webpages GitHub Wiki
生物多樣性指標計算模組概念
當我們在檢視計算生物多樣指標所需要的原始資料時,發現資料來源的型態、格式甚至是收集方法的異質性非常高,例如:海域的珊瑚礁總體檢的資料、陸域的鳥類指標(來源為鳥類繁殖大調查)或蛙類指標(東華大學楊懿如老師研究室)。若要根據上述高度異質性的資料,設計一套共同的指標計算或視覺化模組相對上困難許多。因此我們希望把科學研究上的資料整理、分析及產製出圖表的步驟透過具體的程式碼撰寫及文字註解來整合,簡單的說就是將上述處理過程結構化、程序化並加上說明文件,使得特定的生物多樣性指標的計算過程能容易再現(reproduction)、重複使用(reuse)及公開透明(transparency)。
實際範例
我們拿島嶼生物地理學中經典的物種數與面積的關係來說明如果透過 jupyter notebook 來實作(下方取自 使用 R 計算總數面積方程式的部分)
1. 撰寫說明,本例子中使用 R 撰寫一個函式(function)來計算種數面積曲線方程式
3.2 建立自定的 function 來自動計算種數面積曲線方程式
接下來我們使用 function() 來直接顯示計算出來的種數面積曲線方程式。假設今天我們有許多筆調查資料,
希望能快速求得種數面積方程式,該如何做呢?
解析:
目標:
輸入調查數值(面積、累積物種數)之後就能自動算出調查區域的種數面積方程式
做法:
先將資料(data frame 格式)取 log10()
用 lm 適配出方程式的 log10(k), z 值
還原本來的 k 值 (即 10log10(k))
將方程式存成「扁平」的文字變數,即 y = k*x^z 這樣的格式
因為我們希望輸出的是一個 function() 而非扁平的文字(character),
所以必須使用 eval() 及 parse() 來處理並解析內容
2. 撰寫 R 的函式
接下來我們開始撰寫一個函式來實作輸入一個地區的累積物種數與面積資料後,會自動計算出這個地區的種數面積曲線。R 的 code 如下(如果你不懂 R 也沒關係,你可以想像就是把西瓜和水丟進果汁機,按了攪拌鍵之後會產生西瓜汁。果汁機就是一個函式,西瓜和水是輸入的資料,西瓜汁則是產出的結果),在此函式中同時也在每個步驟撰寫註解,以利後續使用者了解其意義:
find_sa_curve_function = function(sparea_data) {
# 1. 先取 log10
log_sparea = log10(sparea_data)
# 2. fit linear regression model: y = k*x^z
sparea.lm = lm(spnum ~ area, data=log_sparea)
# 取出係數
sparea.lm$coefficients
# 算出的 z 值
z = sparea.lm$coefficients[2]
# 3. 還原算出的 k 值
log10_k = sparea.lm$coefficients[1]
k = 10^(log10_k)
# 4. 將數值存成方程式,注意,這裡是文字(character)格式,並不具有真正的函數功能
# %.4f 代表數值的格式,floating number ,小數點下四位
sparea_formula = sprintf('function(x) {y = %.4f*x^%.4f; return(y)}', k, z)
print(sparea_formula)
# 5. 用 parse 來處理文字格式的 function expression,再用 eval() 來 evaluate expression
sparea_curve_formula = eval(parse(text=sparea_formula))
return(sparea_curve_formula)
}
# 輸入數值
find_sa_curve_function(sa_df)
3. 引用其他的 jupyter notebook 當成函式庫
使用 python 核心,透過 rpy2 來呼叫 R
%reload_ext jupyter_cms
%reload_ext rpy2.ipython
from jupyter_cms.loader import load_notebook
apicook = load_notebook('../interesting_notebook.ipynb')
在 jupyter notebook 中,可使用 %%R 來執行 R 的程式碼
%%R
pkgTest("ggplot2")
...
...
若要使用外部的 notebook 函式,可以採用以下的方法:
# 載入 jupyter notebook: find_a_curve_function.ipynb
fsc = load_notebook('find_sa_curve_function.ipynb’)
apicook.register_function(fsc.r_find_sa_curve_function)
情境
情境一、計算某一特定指標,例如森林覆蓋比例。
Literate APIs 設計架構
綜合以上的說明及範例,我們建構 TaiBON 計算生物多樣性指標的文字式 APIs 概念架構圖:
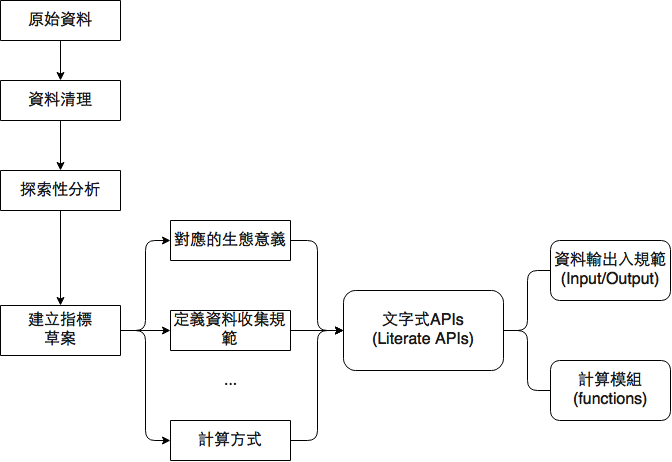
{kind=link}
facebook 討論
(文字有稍微潤飾過)
mutolisp:「想了一想,我覺得我們應該要堅持一下先把一些生態資料,用 jupyter notebook 的方式分析,
寫成幾個範例,告訴大家怎麼來應用資料、收集資料的時候需要注意到什麼。準備資料的時候,需要有哪些
data cleaning 的前置作業、要用哪些分析法、對應到哪些指標,以及其生態上的意義。」
jasonmai:「我想順便試literal api,就那些分析法應該用獨立頁面講解跟實作」
jasonmai:「簡單說就是在 jupyter 下可以寫一些文字跟實際計算的部分」
mutolisp:「那不就跟我之前上課的範例有點類似?」
jasonmai:「計算的部分可以用一些註解式的 annotation。
一個 jupyter notebook 可以去引用其他 jupyter notebook 上的東西撈進來使用,
所以我們只要定義一堆IO(input/output) 然後寫一堆 code,理論上就能拉來拉去實際運算」
jasonmai:「實現看起來是文字模式 但又可以當API的徹底模組化功能」