Stanford Self Taught Learning - SummerBigData/MattRepo GitHub Wiki
In this exercise we used the sparse autoencoder we created earlier to train on the MNIST data, but this time we only trained the autoencoder on numbers 5-9 in the training set. Then, we had to train half of the 0-4 numbers in the training set using softmax regression and tested our weights on the other half of the 0-4 numbers. We used the weights from our autoencoder in our softmax classifier with a hidden layer consisting of 200 nodes. In summary, our autoencoder consisted of an input layer (m, 784), a hidden layer (m, 200), and an output layer (m, 784). Our softmax regression had an input layer (m, 784), middle layer (m, 200), and an output layer (m, 5). Here our a2 was calculated using the weights from the autoencoder. When we ran our backpropagation we only updated our second weights since our first weights were done in the autoencoder. This is what the inputs that cause a max activation look like for 196 out of the 200 nodes for our autoencoder. We used a lambda of 3e-3, beta of 3, and rho (sparsity parameter) of 0.1.
Then, we ran multiple lambda values for our softmax classifier and these were the results for the average accuracies:
Here are what the accuracies of each individual number were:
We then decided to use the entire MNIST training set to train both our sparse autoencoder and softmax classifier and tested them on the provided MNIST testing set. We ran our autoencoder through multiple lambda values, picked out the best value, tested different beta values with that lambda value, picked out the best values, and used the weights generated from them in our softmax classifier. Our rho (sparsity parameter) value stayed the same with a value of 0.1 and here are the inputs that would maximally activate one of the nodes in our hidden layer with different lambda values (These were done with a beta value of 3).

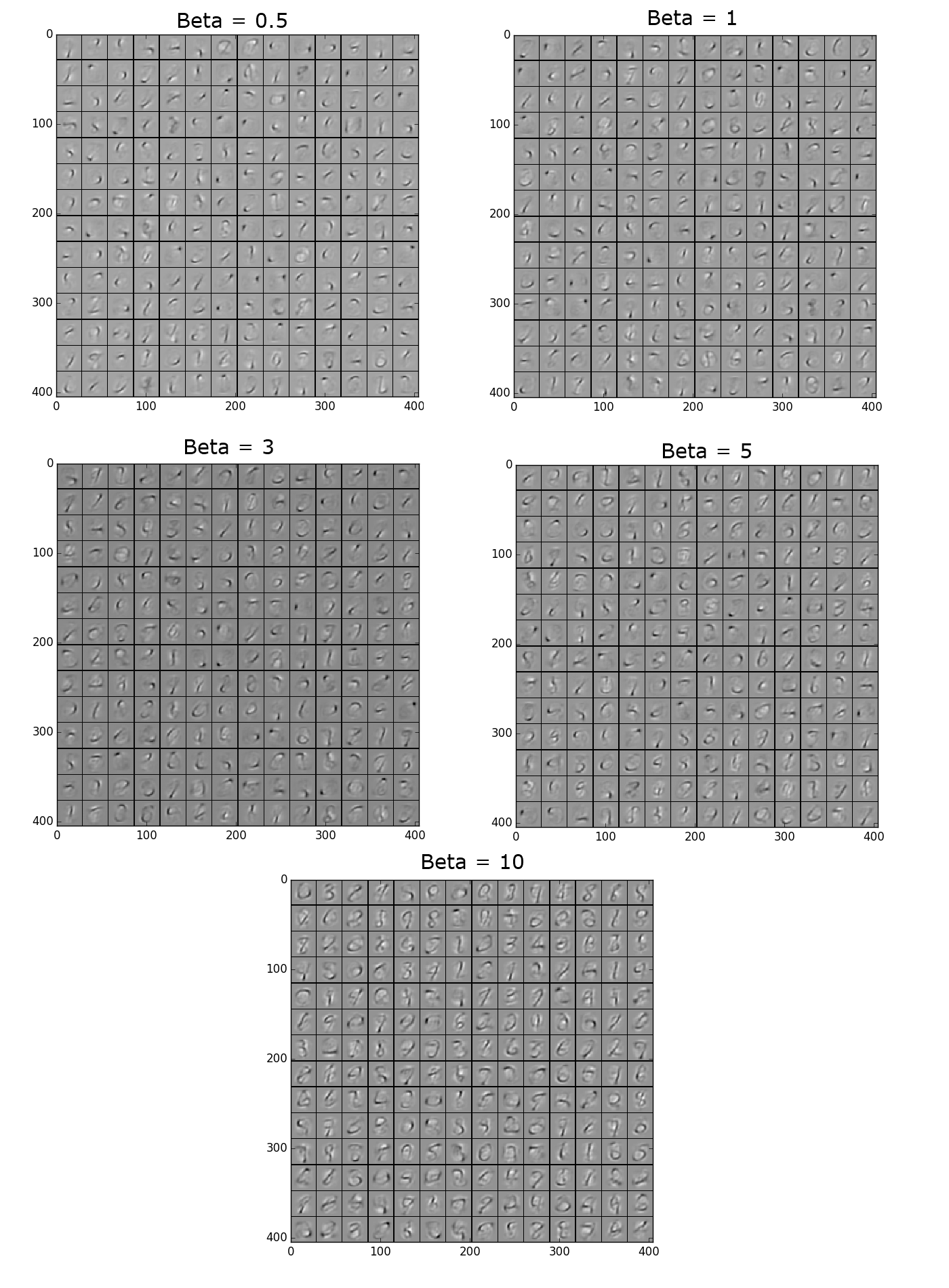
We picked a lambda value of 3e-3 as the best one. Using this value here are the max activations from different beta values. We picked a beta value of 0.5 as the best one.
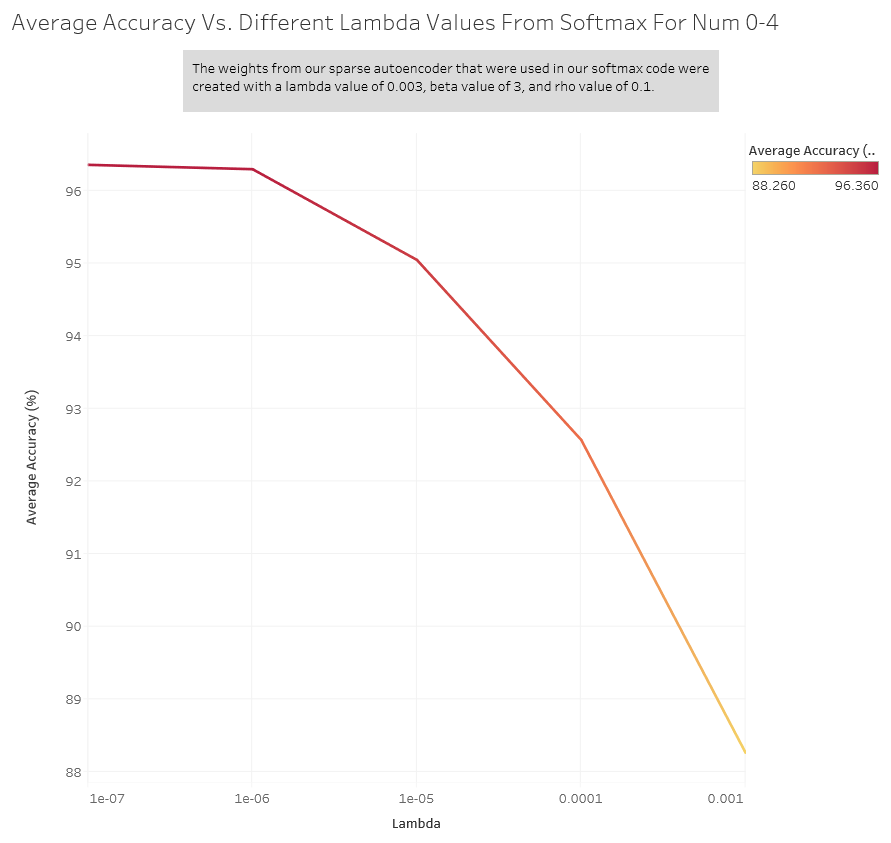
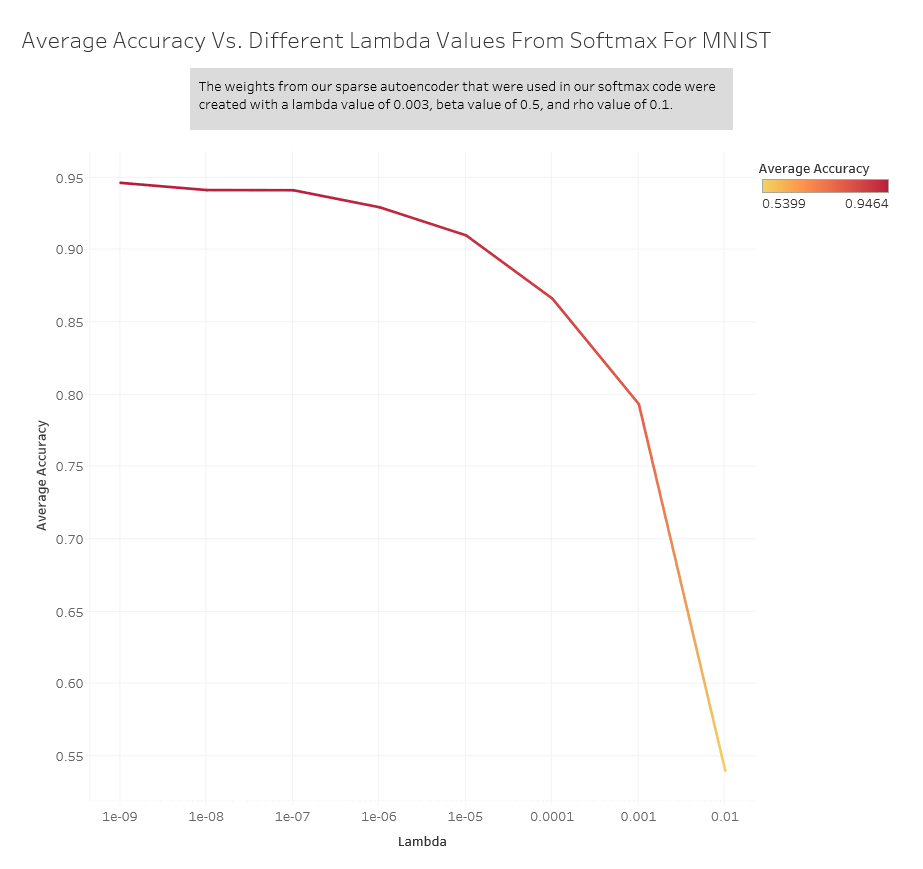
We ran our softmax classifier with the weights obtained from these values and here is the average accuracy:
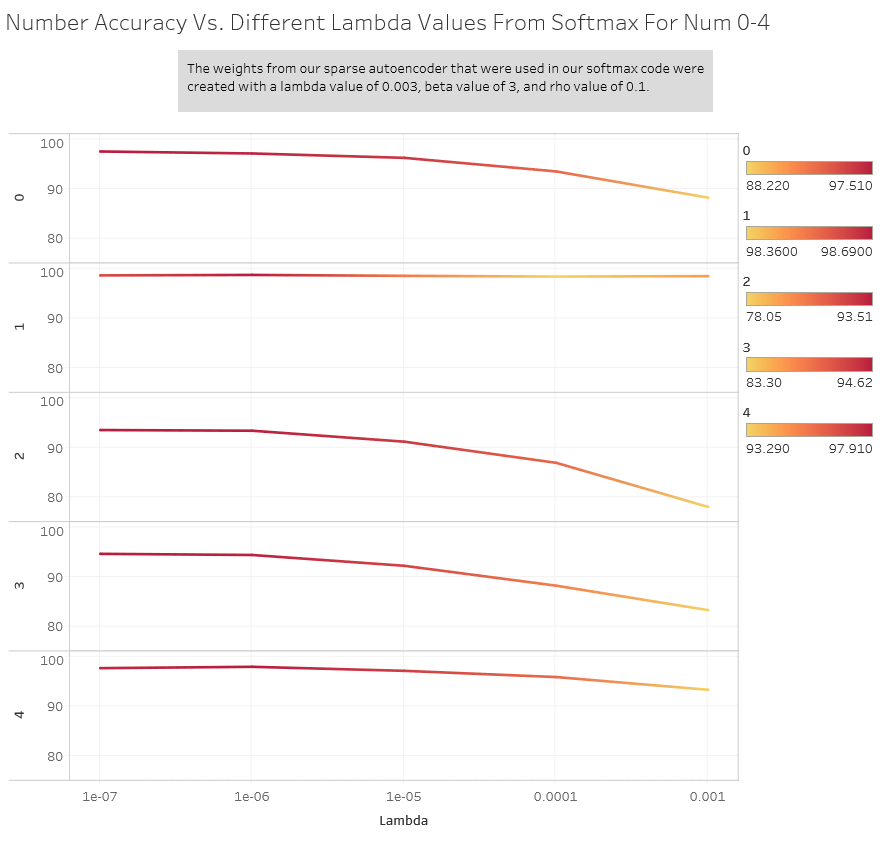
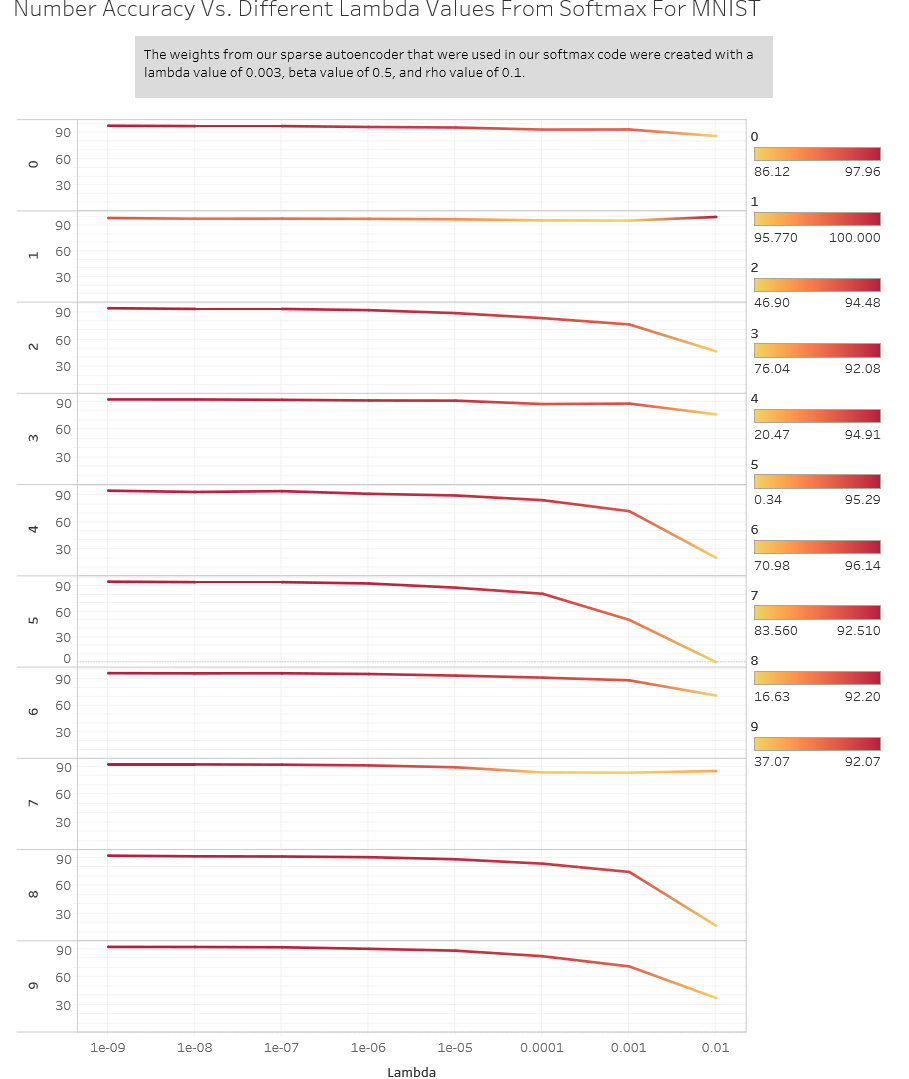
Here are what the accuracies of each individual number were:
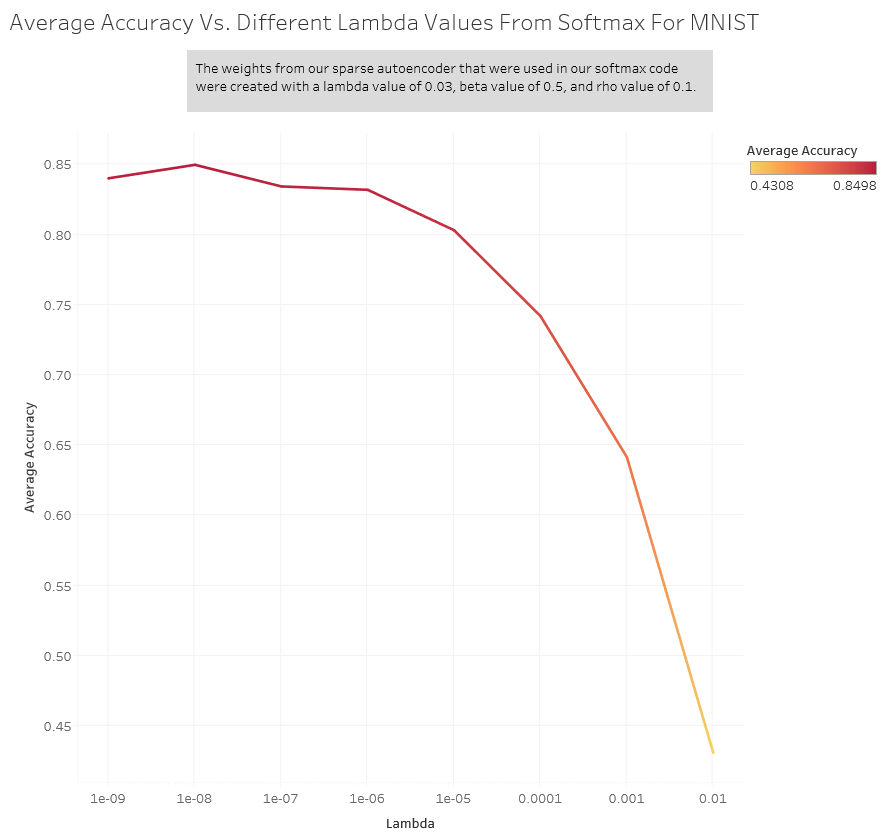
Afterwards, we tested with a lambda value of 0.03 for our sparse autoencoder and set beta at 0.5 and rho at 0.1. These are the max activations:

This is the average accuracy we received for each lambda value for our softmax classifier.