3.4. Массивы - StriderAJR/StudentCpp GitHub Wiki
Массив - это именнованная последовательность элементов в памяти. Особенностью массива является, что элементы хранятся в памяти друг за другом, причем подряд. Доступ до элементов идет по индексу элемента. Индексация всегда начинается с нуля.
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 12 | 60 | 25 | 5 | 19 |
Это иллюстрация ячеек памяти массива на 5 элементов.
Массив может быть объявлен статически и динамически.
-
При статическом объявлении память под массив выделяется в стеке, массив является локальной переменной и будет уничтожен по правилам локальных переменных.
-
При динамическом объявлении память выделяется в куче программы - ее еще называют динамической памятью. Управление ею лежит полностью на совести самого программиста. Доступ до массива осуществляется через указатель.
Объявить и проинициализировать такой массив можно следюущим образом:
int array1[5];-
int- тип данных элементов массива. Это будет массив, хранящий целые числа. Тип данных элементов может быть любой. -
array1- имя переменной. Вы сами его выбираете -
[n], где n - кол-во элементов в массиве. Причем n должно быть константой так или иначе.
int n = 10;
const int m = 10;
int array01[m];
int array02[10];
int array03[n]; - А вот так не получится.Не получится, потому что компилятор не может быть на момент исполнения предсказать, какое число будет вместо n. А значит и выделить память в стеке небезопасно, а значит... Не пошел бы программист лесом. :)
Обращение к ячейке памяти происходит с помощью оператора []
Как параметр этот параметр принимает СМЕЩЕНИЕ относительно начала массива.
array1[0] = 12;
array1[1] = 60;
array1[2] = 25;
array1[3] = 5;
array1[4] = 19;Догадливые уже могли понять: имя массива является адресом начала массива в памяти.
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 12 | 60 | 25 | 5 | 19 |

Переменная array1 хранит именно АДРЕС самой первой ячейки массива (см. раздел указатели, в котором пояснено, что, например, 1 число типа int занимает не 1 ячейку памяти, а 4, потому что 1 ячейка = 1 байт).
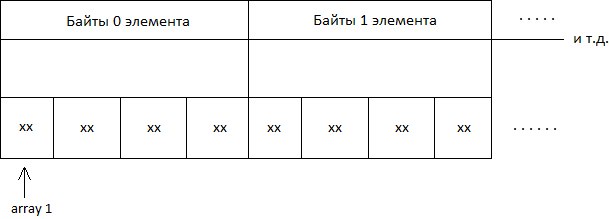
array1 - локальная переменная. А значит хранится в стеке. array1 хранит адрес ячейки в стеке.
cout << "array1 = " << array1 << endl;Естественно, что массивом можно управлять и с помощью цикла:
for (int i = 0; i < 5; i++) cout << "array1[" << i << "] = " << array1[i] << endl;Если элементы массива извесстны заранее, то объявление и инициализацию можно объединить:
float array2[3] = { 1.2, 3.6, 20.5 };А еще можно так:
double array3[] = { 1, 2, 3 }; Как и любая локальная переменная статический массив будет уничтожен по завершению блока кода, в котором был объявлен.
А теперь задумаемся вот над каким вопросом: если имя массива - это адрес самой первой ячейки в самом массиве, иными словами: имя массива - это указатель на начало массива. Но как же оператор [] по индексу элемента извлекает данные из массива? Если вы хорошо усвоили тему указателей и операций над указателями, то вы легко найдете ответ на этот вопрос.
Допустим, нам нужен самый первый элемент массива. Сам указатель массива уже хранит адрес этого элемента, нам достаточно разыменовать указатель на массив и мы получим искомый элемент.
cout << "array1[0] = " <<*array1 << endlТеперь нам нужен следующий, второй элемент. Он лежит сразу же за первым, помня о масштабировании адресов, мы знаем, что достаточно увеличить указатель на единицу, чтобы получить адрес искомого элемента, а затем разыменовать его.
cout << "array1[1] = " << *(array1 + 1) << endl;Заметили? Индекс, который передается в оператор [] - это СМЕЩЕНИЕ элемента относительно начала массива! Т.е. индексация с нуля взялась не на пустом месте, это обусловлено косвенной адресацией через указатели!
Вау!!! Магия. ^_^
Поэтому, на самом деле за строчкой
cout << "array1[0] = " <<*array1 << endl;скрывается
cout << "array1[0] = " <<*(array1 + 0) << endl;Просто ноль мы, как люди, обычно не пишем.
Так что вывести на экран можно двумя способами:
for (int i = 0; i < 5; i++) cout << "array1[" << i << "] = " << array1[i] << endl;или
for (int i = 0; i < 5; i++) cout << "array1[" << i << "] = " << *(array1 + i) << endl;Так что оператор [] это опять же пресловутый синтаксический "сахар" для программиста, и этот оператор просто прибавляет к адресу начала массива смещение и разыменовывает полученный указатель.
Естественно, никто не мешает использовать полную запись доступа до элемента массива не только для чтения элемента из массива, но и для записи:
*(array1 + 2) = 2;
cout << array1[2] << endl;Итак, со статическими массивами разобрались, теперь пора перейти к динамическим.
Основное и краеугольное отличие статических и динамических массивов в том, где каждый из них хранится.
-
Статический - в стеке.
-
Динамический - в куче.
Жизненным циклов статического управляет программа, динамическим сам программист.
Суть динамического массива в том, что программист сам, как хочет управляет памятью. Это дает безграничную гибкость в написании кода, но и безграничные возможности выстрелить себе в ногу... Sad, but true.
Раз абсолютно все находится в ведении программиста, то даже выделять, высвобождать и следить за целостностью данных (их сохранностью) должны мы сами.
Есть две основные команды по работе с динамической памятью (кучей):
- Выделить память.
- Высвободить память.
Выделение памяти.
Для выделения памяти есть оператор new. Оператор new резервирует память под хранение данных. Не трудно догадаться, что память в компьютере либо есть, либо ее нет. Поэтому сказать, что new "создает" память - неверно, он же не добавит вам новые планки оперативной память (а жаль, было бы круто). Память была еще до new. Более того, память под использование программой выделяется операционной системой в момент запуска программы: программа точно знает "куда можно ходить" ну или какую память можно, а какую нельзя использовать.
Т.е. память у программы есть. Но она "общая" для всей программы. Переменные все время создаются, программа потребляет это пространство памяти для своей жизнедеятельности, причем какие-то процессы мы не можем контролировать.
Куча - это свалка памяти, ею пользуются все процессы в вашей программе. Ячейки все время используются кем-то или чем-то. Чем больше и сложнее программа, тем хаотичнее и чаще ячейки кучи задействуются.
Скажите, вам понравится, если вы сохраните какие-то данные по адресу в куче, а потом программа без вашего ведома возьмет и поменяет эти данные? Что получится в итоге - непредсказуемо, а значит опасно.
Чтобы такого не происходило, компиляторами продуман механизм "резервирования" памяти.
При резервировании памяти некоторые ячейки помечаются "занятыми" для использования вами. Такие зарезервированные ячейки программа без вас сама трогать не будет, теперь эти ячейки можете изменить только вы своими шаловливыми ручонками.
Вот что делает оператор new. Он резервирует определенный объем памяти в куче.
Кстати, кстати.
Оператор new это опять же синтаксический "сахар". На самом деле он внутри своей реализации вызывает ф-цию выделения памяти malloc(size_to_allocate);
malloc расшифровывается как memory allocate (memory - память, allocate - выделить, зарезервировать).
В качестве параметра malloc принимает кол-во байт, которое нужно выделить.
new float; преобразуется компилятором в malloc( sizeof(float) );
А как же работает оператор new и ф-ция malloc? Как она находит место, где можно зарезервировать память? Очень просто. Поиск начинается с адреса начала кучи, находится НЕПРЕРЫВНЫЙ и свободный участок в памяти, и уже он резервируется.
С++ тупой, поэтому работает так. Это на самом деле не очень оптимально. Но вот такой это простой язык. Языки с виртуальными машинами типа c# и java работают с памятью по более сложным алгоритмам.
float* ptr1 = new float; // зарезервировали sizeof(float) байт памяти в куче
*ptr1 = 1.5;
cout << "*ptr1 = " << *ptr1 << endl;Итак, что тут произошло.
Мы создали указатель. Затем с помощью оператора new выделили память под ячейку памяти типа данных float (4 или сколько там байт - всегда можно запустить sizeof(float), чтобы узнать точно). И адрес выделенной памяти сохранился в указатель ptr1.
Что важно:
ptr1 - это локальная переменная и будет храниться в стеке.
оператор new - выделил память в куче, не в стеке.
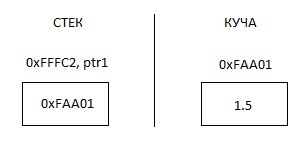
Как любая локальная переменная ptr1 будет уничтожена, когда завершится ее блок кода. А вот память в куче... Нет. Потому что вся ответственность за нее лежит на программисте. Как хочешь так и разбирайся.
Выглядеть это будет так.

Стек избавился от своей переменной ptr1, а вот зарезервированная область в памяти так и осталась зарезервированной. Программа не может использовать эту память повторно. Да и мы больше не имеем доступа до этой памяти. Мы же потеряли адрес, где эта память хранится.
Конечно, после завершения программы, вся память выделенная программе ОС, в том числе и куча, будет высвобождена, очищена и пожертвована другому процессу в ОС. Но вы правда хотите, чтобы ваша программа оставляла за собой неиспользуемый мусор, засоряла память и т.д.?
Вам нравится, когда программы жрут по 1Гб, 2Гб, 3Гб памяти причем непонятно зачем, когда они ничего такого мега сложного не делают? Конечно, не нравится. Поэтому не надо мусорить там, где вы работаете, т.е. в памяти вашей программы.
Высвобождение памяти.
Чтобы иметь возможно подчищать за собой больше ненужную нам память в куче был введен оператор delete.
delete в качестве параметра принимает указатель (читай, адрес) на ту область памяти, которую нужно высвободить.
Кстати, delete также как и new на самом деле запускает ф-цию высвобождения памяти free, которая как параметр принимает указатель.
delete pointer; эквивалентно free(pointer);
Правило обращения с динамической памятью достаточно простое: Каждому new даешь свой delete. Написали где-то new? Значит, нужно где-то эту память высвободить. Никак иначе.
Ок, если мы передаем указатель, то это адрес всего лишь 1 байта в памяти, но даже выше мы зарезервировали память под float, а это всяко больше 1 байта!
Получается, освободится только 1 байт? А потом нам в цикле нужно бегать и высвобождать все остальные ячейки? Без паники. Разработчики компилятора о вас уже позаботились.
Информация для продвинутых.
На самом деле при резервировании памяти, вам для использования выдается указатель не на первую зарезервированную ячейку, а на следующую... Потому что в самой первой ячейке хранится так называемые метаданные о памяти. В этих метаданных хранится объем выделенной памяти, тип данных, под который изначально память выделялась и некоторая еще информация.
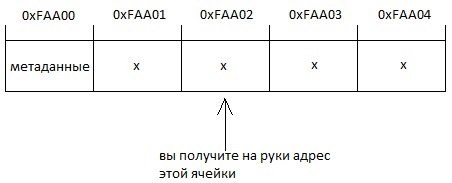
Кстати, метаданные могут занимать не 1 байт памяти, но это значение всегда фиксировано у компилятора, он знает сколько метаданных ему нужно для работы. Но для простоты сейчас используется, чтометаданные занимают 1 байт памяти.
Поэтому когда вы параметром в delete передаете указатель, программа сначала делает шаг назад, считывает из метаданных нужную информацию об объеме выделенной памяти и высвободит все 4 или сколько там было ячеек. Конец информации для продвинутых.
Так что на самом деле компилятор хранит информацию о том, под какой тип данных была зарезервирована память и соответственно при освобождении он увидит, сколько памяти начиная с данного адреса была выделено, и сколько сейчас нужно высвободить.
delete ptr1;После высвобождения памяти, флаг "занято" с памяти снимается. Соответственно, если мы попытаемся обратиться к такой памяти еще раз уже после ее освобождения, программа вывалится в ужасе с ошибкой "Access violation", что в вольном переводе означает "у меня нет прав сюда лезть".
Но скажем так, С++ далеко не всегда настолько усожлив, чтобы сообщить нам, что мы полезли куда-то не туда. Обычно предупреждающей таблички нет, мы залезаем на чужую территорию и кто-нибудь потом, когда мы уже не ждем стреляет нам в ногу... Или голову, в зависимости от критичности ошибки в коде.
// cout << "*ptr1 = " << *ptr1 << endl; // Тут будет ошибка времени исполненияЛадно, ладно. Мы немного отвлеклись, но это было необходимо.
Раз динамические массивы хранятся в куче, то память под них выделять и высвобождать будем мы сами, ручками. Ну а что вы хотели? Жизнь жестока.
int* array1 = new int[5];Итак, начнем разбирать с самого легкого. Правая половина выражения.
new int[5];
Это синтаксис выделения памяти под массив, элеметами которого являются int и таких чисел 5 штук.
Через malloc записывается так: malloc( sizeof(int) * 5 );
Таким образом выделится 20 байт памяти.
Как и положено после резервирования памяти, оператор new вернет как результат указатель на НАЧАЛО выделенной области памяти.
Все то же самое было и со статическими массивами, там тоже имя массива являлось адресом начала массива. Только хранился он в стеке, а тут в куче.
Короче, вернулся нам адрес первого элемента в массиве, он же начало всего массива.
Поэтому тип данных указателя должен быть int. Потому что элемент, адрес на который нам вернулся именно что int.
Так что слева нам и пришлось написать int* array1 - указатель на тип данных int.
Ну а в памяти все это безобразие выглядеть будет так:
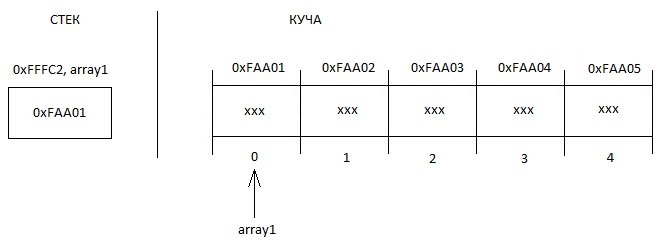
В плане работы с массивом нет никакой разницы ни по синтаксису, ни по логике по сравнению со статическим массивом.
array1[0] = 11;
array1[1] = 12;
array1[2] = 13;
array1[3] = 14;
array1[4] = 15;
for (int i = 0; i < 5; i++) cout << "array1[" << i << "] = " << array1[i] << " ";
// Не забываем высвободить память
int* ptr = array1;
delete[] array1;"Что за фигня?" спросите вы, увидев delete[], "зачем у delete написан оператор []"
Если кратко, то delete[] должен быть вызван, если выделение памяти было через new[], в частности для массивов.
delete соответственно вызывается, если память выделялась с помощью new.
Сейчас придется вам поверить мне на слово:
Для массивов из простых типов данных, вы не почувствуете разницу между delete и delete[], работать при удалении массива они будут одинаково. Но вот дальше, когда будут изучаться пользовательские типы данных, классы, там путаница с delete и delete[] может вызвать ошибки времени исполнения и повреждение памяти.
Привыкайте правильно пользоваться операторами. Если память была выделена под массив, то и высвобождать эту память нужно как для массива.
Пример, когда вызов delete для массива объектов повредит память будет в разделе "жизненный цикл объектов".
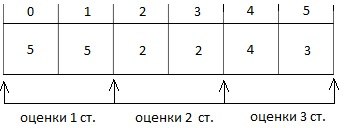
В некоторых задачах требуется хранить набор данных для набора данных. Например, допустим, нужно хранить оценки студентов по двум дисциплинам. Всего студентов 3 человек. 3 человека и у каждого по 2 оценки.
Сохранить эту информацию можно 3 способами:
- Несколько небольших массивов.
- Один большой массив.
- Двумерный массив.
Рассмотрим каждый способ по порядку;
- Несколько небольших массивов: Для каждого студента будем создавать свой собственный массив на 2 оценки.
int arrayStudent1[2];
// Первый студент пусть будет отличником
arrayStudent1[0] = 5;
arrayStudent1[1] = 5;
int arrayStudent2[2];
// Второй - двоечником
arrayStudent2[2] = 2;
arrayStudent2[3] = 2;
int arrayStudent3[2];
// Третий - перебивающийся
arrayStudent3[4] = 4;
arrayStudent3[5] = 3;Вроде, выглядит неплохо. Легко читается, код понятен. Тогда что не так? Универсальность. Допустим, мы не знаем до начала программы, сколько будет студентов. Пользователь только после запуска программы введет число студентов в группе. Сколько тогда создать переменных? 10? 50? 100? 1000? И что? Все их объявлять? А как обращаться к такому непонятному числу переменных? В общем, это не то чтобы невозможно. Но такие извращения в такой задаче излишни. Все должно быть намного проще.
- Один массив для всех данных. Чтобы сохранить оценки для 3 человек понадобится 6 ячеек памяти. Ячейки 0 и 1 будут оценками для студента 0 (индексация приведена с 0, как в массиве); Ячейки 2 и 3 - оценки 1 студента; Ячейки 4 и 5 - оценки 2 студента.
int array1[6];
array1[0] = 5;
array1[1] = 5;
array1[2] = 2;
array1[3] = 2;
array1[4] = 4;
array1[5] = 3;Итак у нас есть 3 студента у каждого по 2 оценки. Все они хранятся в одном массиве. Мы решили проблему с универсальностью (допустим, мы как-то обошли ограничение, что число элементов в массиве должно быть только константой).
Тогда, допустим, что мы можем создавать массив для n студентов и m дисциплин. Размер массива для хранения всего этого дела будет равен n * m.
Но как обратиться, скажем, к оценке по первой дисциплине у второго студента? Если индексация идет с 0, то нам нужен студент с индексом 1 и дисциплина с индексом 0.
Если посмотреть на инициализацию массива выше, то нужная оценка лежит по индексу - 2.
Далее несложно вывести формулу индекса нужной оценки в массиве: i * m + j = 1 * 2 + 0 = 2
где i - индекс искомого студента, а j - индекс нужной дисциплины.
Такую формулу можно запрограммировать. Пользователь вводит номер студента, номер дисциплины, а программа, рассчитав формулу, выдаст нужную оценку. Профит.
Но, опять же, программисты дюже ленивые существа. Каждый раз делать умножение и сложение вручную, только чтобы узнать индекс оценки... Нет, не наш способ.
Поэтому во всех языках программирования есть понятие многомерных массивов. В данном случае нам будет достаточно двумерного массива.
- Двумерный массив.
int array[3][2]; // 3 студента по 2-м дисциплинам
// Оценки 0 студента
array[0][0] = 5; // 0 дисциплина
array[0][1] = 5; // 1 дисциплина
// Оценки 1 студента
array[1][0] = 2; // 0 дисциплина
array[1][1] = 2; // 1 дисциплина
// Оценки 2 студента
array[2][0] = 4; // 0 дисциплина
array[2][1] = 3; // 1 дисциплинаКакое же преимущество дает двумерный массив? По сравнению со втором способом (один массив) мы просто получили более удобную индексацию. Да, не так много. Но читаемость кода увеличилась, теперь мы прямо во время запроса оценки видим, какой индекс студента и дисциплины запрашивается. Плюс нам не нужно производить вычислений по формуле.
Как же это работает.
На самом деле запись двумерного массива - это лишь синтаксический "сахар" для программиста. В памяти "двумерный" массив программой размещается в памяти, как один "длинный" массив, как мы сами руками делали во втором способе. Но рассчет всех формул берет на себя программа за нас.
int array[3][2]; преобразуется компилятором в строчку int array[3 * 2];
А строчка array[i][j]; преобразуется в array[i * m + j];
На самом деле, как вы помните, даже оператор [] - это тоже сахар и на самом деле это выглядит еще немного по-другому: *(array + i * m + j);
И это истинная запись такой простой команды: array[i][j];
Ну, хорошо, с использованием двумерных массивов разобрались, но как же они хранятся в памяти. Ответ на этот вопрос уже звучал: двумерный массив преобразуется компилятором в длинный двумерный массив. А значит массив int array[3][2]; в памяти выглядит так:
Еще раз:
Массив любой размерности хранится в памяти ЛИНЕЙНО. Память в принципе линейна. Ячейки идут друг за другом. Перемещаться в памяти можно либо вперед, либо назад. Никаких "верх", "вниз" в памяти быть не может по определению.
Да, двумерный массив по смыслу и использованию похож на матрицу или таблицу.
Но
НИКАКИХ ТАБЛИЦ В ПАМЯТИ БЫТЬ НЕ МОЖЕТ.
Память линейна. Все данные в массивах хранятся подряд.
Разбирая двумерные массивы, было упомянуто, что в программировании массивы многомерны. И на самом деле "мерность" массива ничем не ограничена. Размерность может быть 3, 4, 5 - хоть сколько.
Конечно, есть ограничение по логике. Редко когда требуется размерность больше 3. Но тем не менее, архитектурно ограничений нет. Трехмерные массивы могут понадобится, например, если нужно хранить оценки студентов из нескольких групп по нескольким дисциплинам.
Допустим, у нас есть 3 группы студентов в каждой по 3 человека, у каждого по 2 оценки.
int array[3][3][2];
// Заполним массив (дайте мне помечтать и представить, что все студенты - отличники):
for (int i = 0; i < 3; i++)
for (int j = 0; j < 3; j++)
for (int k = 0; k < 2; k++)
array[i][j][k] = 5;Таким образом в памяти будет создан ОДИН линейный массив на 3 * 3 * 2 = 18 элемента.
Ну или компилятор запишет это так: int array[3 * 3 * 2];
А в памяти это будет выглядеть так:

Задание для упоротых:
попробуйте записать array[i][j][k] вообще без использования оператора [], как это демонстировалось в разделе "Двумерные массивы" Подсказка: расписывайте не сразу все 3 применения [], а начините с первых двух [], т.к. их понятно как расписать.
Или нарисуйте весь массив линейно и возьмите несколько индексов для примера (это тоже демонстрировалось в разделе про двумерные массивы) - и рассчитайте формулу, по которой вычисляется индекс.
После того, как вы поймете как образуется эта формула, вы сможете рассчитывать формулу для массива любой размерности.
Строка - это массив символов, оканчивающийся символом конца строки (нулевым байтом
\0, т.е. просто нулем)
А значит, как в любом массиве, переменная "строки" - это адрес на первый символ в строке. Остальные символы располагаются сразу за первым.
Если в обычном массиве мы не знаем, где он заканчивается (для этого всегда нужно в отдельной переменной хранить кол-во элементов в массиве), то в строках для определения конца после последнего символа записывается нулевой байт, который и является признаком конца строки.
Например, строка "Hi" в памяти занимает на самом деле 3 байта: по 1 байту для каждого символа = 2 байта + 1 нулевой байт, как символ конца строки. Т.е. в памяти последовательность байт выглядит так:

В памяти все символы хранятся как код по таблице ASCII/Unicode/другая в зависимости от кодировки:
72 - это код символа 'H' в таблице ASCII
105 - это код символа 'i' в таблице ASCII
0 - это признак конца строки
Т.к. в памяти все данные хранятся только в числовом виде, то все символы кодируются через их коды. Таблицы кодировок бывают разными. Основные это ASCII и Unicode.
ASCII хранит символы в диапазоне от 0 до 255, поэтому содержит не так уж много символов: латинский алфавит, цифры и некоторое кол-во спец.символов. Поэтому для кодирования этой таблицы достаточно объема памяти в 1 байт. Это и есть тип данных char.
Unicode же может кодировать символы 2, 4 или 8 байтами. Поэтому содержит огромное кол-во символов. Все региональные алфавитные системы, включая арабские, иероглифичные, греческие и т.д. и т.д.
Нулевой байт в конце строки позволяет при работе со строкой точно знать, где она заканчивается без дополнительного параметра.
Например,
char str0[7] = "qwerty";
cout << str0 << endl;При создании строки после 6 "полезных" символов программа сама добавит еще 7 символ - нулевой байт, чтобы обозначить конец строки. При выводе строки на экран, будет выведены все байты, которые находятся до нулевого. Найдя нулевой байт в памяти, вывод остановится.
Думаете программа будет выводить ровно 6 или 7 байт, по кол-ву выведенной памяти? Давайте проверим.
char str0[7] = "qwerty";
cout << str0 << endl;
str0[6] = '!'; // Убираем нулевой байт из конца строки
cout << str0 << endl;После создания строки и вывода ее на экран, мы "затерли" нулевой байт, который находился по индексу 6 (нумерация же с нуля в массиве).
И теперь вывод на экран строки str0 будет примерно следующий:
qwerty!МММММ??qxьх
Все что идет после символа ! (вместо которого был нулевой байт) - это "мусор". Случайные цифры, которые были преобразованы в символы, потому что программы интерпретирует любые байты от адреса начала строки и до нулевого байта как символы.
Остановилась программа только тогда, когда нашла в памяти "случайный" ноль. В моем случае до этого момента вывелось 12 лишних символов.
По принципу "до нулевого байта" работают абсолютно все строковые ф-ции: strcpy, strcmp, strcat и другие.
Как вы видите в С++ работать со строками не так уж просто. Нужно всегда держать в голове состояние памяти и случайно его не испортить.
Чтобы облегчить эту задачи существует тип данных string, который по сути является оберткой вокруг обычного char*. У него есть функции получения длины, перегружены операторы для объединения строк, есть ф-ции поиска подстроки и много-много других удобных вещей.
Однако, как любая обертка, она не только упрощает вашу работу, но и не позволяет самостоятельно разобраться, как идет работа со строками.
Пока вы самостоятельно не освоите и не будете чувствовать себя уверенно с типом данных char* не используйте тип данных string. Это позволит вам отточить навыки работы со строками, указателями и памятью.
Также как и массив, строку можно создавать статическим путем:
char phone[11];или данимическим:
char* fio = new char[100];Пример создания статической строки:
char str0[7] = "qwerty";Создадим статическую строку и считаем в нее значение.
char str1[5];
cin >> str1;
cout << endl << str1 << endl;Вроде бы, все хорошо. Однако даже в таком коде уже есть потенциальная ошибка.
Для строки str1 было выделено всего 5 байт. Если ввод будет, допустим, :), то будет все хорошо. Из буфера консоли в строку запишется 3 байта: : ) 0. Последний нулевой байт нужен как символ конца строки.
Поэтому после строчки cout << str1; выведется как и положено :), хотя в строке и зарезервировано 5 байт (нулевой байт и все дела).
Однако, давайте попробуем считать с консоли, например, строку abdce. В ней же всего 5 символов. Как и положено. Ну ок, добавится 6 куда-нибудь после 5 наших. Все же должно быть хорошо? А вот фиг вам!
Будет ошибка: Run-Time Check Failure #2 - Stack around the variable 'str1' was corrupted.
По-русски это будет звучать примерно как (крайне не рекомендую пользоваться русской версией IDE, кстати): Ошибка времени выполнения #2: Стек вокруг переменной str1 поврежден.
Как так? Да очень просто. Мы выделили 5 байт под строку. Вместе с нулевым байтом у нас из буфера консоли пришло 6 байт. 6, нулевой байт, вышел за границы массива. С++, конечно, тупой, но состояние стека и кучи во время выполнения программы он все-таки отслеживает.
Во время выполнения выполнения программа ожидала, что состояние будет одно (например, что переменная str1 занимает всего 5 байт), а внезапно 6 байт после начала строки тоже оказался изменен! И программа естественно такая: Что за нафиг?! И выдала вам ошибку.
Поэтому считывать любые строковые переменные таким образом нельзя. Лучше делать это так:
char str1[5];
cin.getline(str1, 5);
cout << str1 << endl;В этом случае даже если пользователь введет больше 4 символов (5й-то нам нужен под нулевой байт), например, qwerty, то все 6 символов запишутся в буфер консоли, однако команда cin.getline(str1, 5); из буфера извлечет и запишет в переменную str1 только 5 байт (4 символа + нулевой байт).
И выведется на экран только: qwer. Ошибки уже не будет.
Статические строки (их еще называют строки фиксированной, постоянной длины) подходят для хранения только значений определенной длины!
Ну хорошо, почему нельзя хранить больше, мы разобрались - больше просто не влезет, будет ошибка, но почему нельзя, скажем, в 10 байтах символов хранить всего 2 символа?
С++ позиционируется как язык с высокой оптимизацией не только скорости работы, но и использования памяти. Каждый байт при резервировании в памяти должен быть обоснован. Если вы создаете строку на 10 байтов, все эти 10 байт "заняты", компилятор не может их использовать. И если вы будете хранить в этих 10 байтах только 2 символа, то остальные 8 будут простаивать.
Хорошо 8 "потерянных" байт это не страшно. Однако привычка - страшная вещь. Не научившись сразу бережно относиться в памяти, вы рискуете всегда "жрать память" как не в себя.
На эту тему даже есть анекдот:
Аккуратный стол, белая тарелочка на нем, на тарелочке оперативка. Сидит С++, аккуратно ножом отрезает кусочек и кушает. И ТУТ В СТОЛОВУЮ ВЛАМЫВАЕТСЯ СВИНЬЯ И СЖИРАЕТ ВСЮ ОПЕРАТИВКУ СРАЗУ - это Java. ...С++ от испуга выплевывает откушенный кусочек и кричит: Segmentation fault!!!
Поэтому не нужно так. Храните в статических строках данные, которые не будут менять своей длины: номера телефонов, номера паспортов и т.д.
Для всех остальных случаев нужно использовать динамические строки.
Динамические строки используются в случаях, когда вы не знаете, какой длины данные ждать от пользователя. В этом случае память под строку будет выделяться динамически в куче в процессе выполнения программы.
Алгоритм:
1. Считать строку в "большой" буфер
2. Определить, сколько в буфере "полезных" данных
3. Создать строку, выделив память ровно под "полезные" данные
4. Скопировать данные из буфера в строку
5. Уничтожить буфер, чтобы не занимал память
6. Профит
А теперь смысл:
Мы не знаем, сколько символов введет пользователь. Может быть, всего 10, а может быть и 100500. Но если он введет всего 10, мы не хотим иметь зарезервированную, но не используемую память. Если он введет 100500 символов, то мы не хотим случайно их потерять, потому что считываем из консоли только определенное кол-во символов.
Для этого и создается буфер с запасом памяти, чтобы точно хватило. И из консоли данные считываются в него. Если буфер у нас на 255 символов, а пользователь введет всего 10 символов, то нулевой байт даст нам знать, что "полезных" символов будет всего 10.
Поэтому после считывания данных в буфер, мы можем узнать "реальную" длину буфера по нулевому байту и выделять память под требуемую строку ровно столько, сколько нужно. Скопировав затем данные из буфера в переменную, мы получаем компактную строку, в которой ровно столько байт, сколько было введено пользователем.
А теперь как это может выглядеть в коде:
char* buf = new char[255];
cin.getline(buf, 255);
char* str2 = new char[strlen(buf)];
strcpy(str2, buf);
delete[] buf;
cout << str2;Пошаговое пояснение кода:
1. Создаем буфер с "запасом", чтобы хватило: char* buf = new char[255];
2. Читаем данные в него: cin.getline(buf, 255);
3. Выделяем ровно столько памяти, сколько "полезных" символов в буфере: char* str2 = new char[strlen(buf)];
4. strlen - ф-ция определения длины строки, которая считает символы только до нулевого байта.
5. Если пользователь ввел всего 10 символов, то strlen и вернет 10.
6. Копируем реальную строку из буфера в переменную str2: strcpy(str2, buf);
7. Удаляем ненужный больше буфер: delete[] buf;
Еще более хорошим тоном считается в программе выделить все это хозяйство в отдельную ф-цию, чтобы не писать каждый раз столько строк ради одного лишь считывания строки с экрана:
char* readString()
{
char buf[255];
cin.getline(buf, 255);
char* str = new char[strlen(buf)];
strcpy(str, buf);
return str;
}В данном случае нет необходимости создавать буфер, как динамическую строку, чтобы затем удалить ее вручную. Т.к. это ф-ция, а переменная buf - локальная переменная, она уничтожится сама, когда закончится блок кода, в котором она была объявлена, т.е. сама ф-ция.
Теперь считывать строку с экрана будет очень просто:
char* str3 = readString();
cout << str3 << endl;