Bagging (Boostrap Aggregating) - SoojungHong/MachineLearning GitHub Wiki
Bagging (Bootstrap aggregating) Bootstrap aggregating, also called bagging, is a machine learning ensemble meta-algorithm designed to improve the stability and accuracy of machine learning algorithms used in statistical classification and regression. It also reduces variance and helps to avoid overfitting. Although it is usually applied to decision tree methods, it can be used with any type of method. Bagging is a special case of the model averaging approach.
“Bagging predictors is a method for generating multiple versions of a predictor and using these to get an aggregated predictor.”
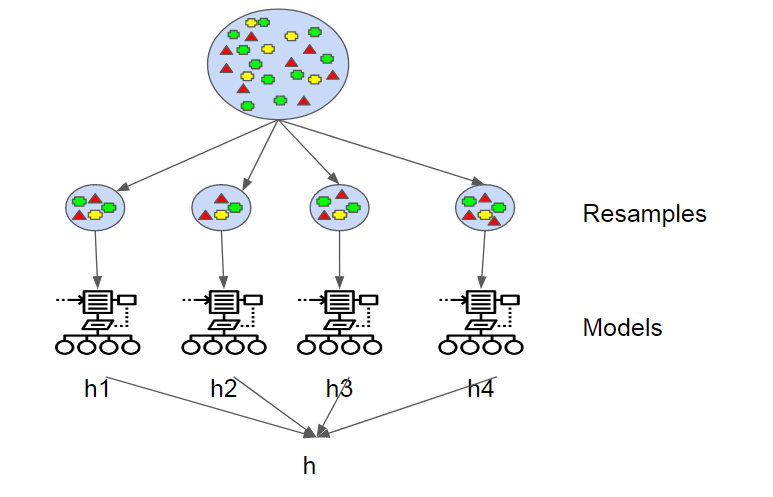
The models use voting for classification or averaging for regression. This is where the “Aggregating” in “Bootstrap Aggregating” comes into play. Each hypothesis has the same weight as all the others.
Bootstrap
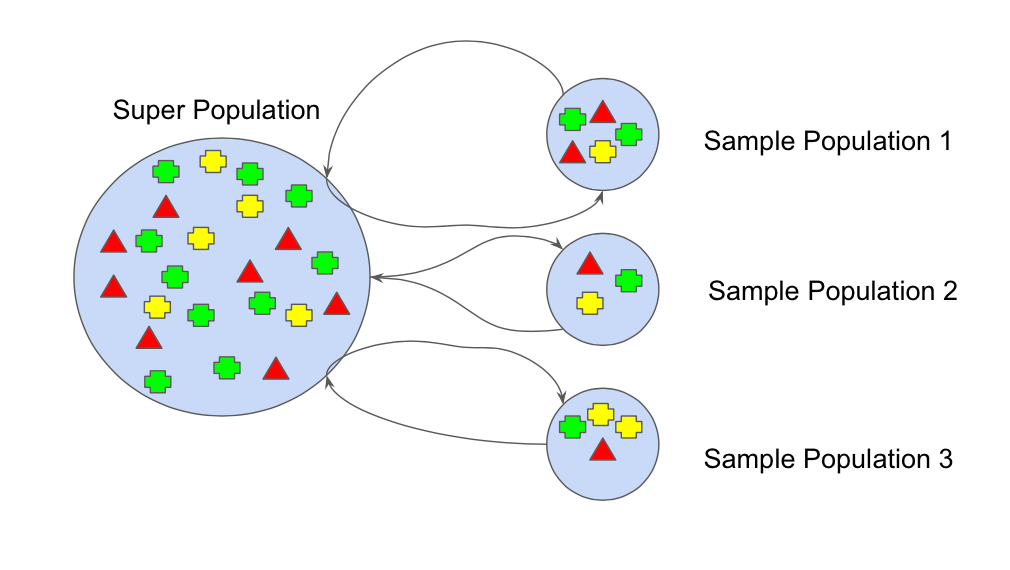
In machine learning, the bootstrap method refers to random sampling with replacement. This sample is referred to as a resample. This allows the model or algorithm to get a better understanding of the various biases, variances and features that exist in the resample. Demonstrated in figure above where each sample population has different pieces, and none are identical. This would then affect the overall mean, standard deviation and other descriptive metrics of a data set. In turn, it can develop more robust models.
Bootstrapping is also great for small size data sets that can have a tendency to overfit. In fact, we recommended this to one company who was concerned because their data sets were far from “Big Data”. Bootstrapping can be a solution in this case because algorithms that utilize bootstrapping can be more robust and handle new data sets depending on the methodology chosen.
Reference : https://hackernoon.com/how-to-develop-a-robust-algorithm-c38e08f32201