A Survey on Machine Reading Comprehension: Tasks, Evaluation Metrics and Benchmark Datasets - Songwooseok123/Study_Space GitHub Wiki
MRC survey 논문(링크)
1. MRC task 분석 및 분류 Taxonomy 제시
2. Evaluation metric 요약
3. Discuss open issues in MRC research and future research directions
4. Benchmark Dataset
1. MRC Tasks
기계독해(Machine Reading Comprehension)?
주어진 지문(Context)을 이해하고, 주어진 질의(Query/Question)의 답변(Answer)을 추론하는 문제
- Search engine 및 Dialogue system(Chatbot)에서 사용
STEP 1. Retrieval: Query에 대한 정보가 담긴 지문을 찾은 후 STEP 2. Read: 그 지문을 읽어서(Read) 답변을 찾는다.
1.1 Definition
목표: Learn predictor $f$ $$a = f(p,q)$$
- Training examples ${(p_i,q_i,a_i)}$
- $p$ : passage of text(text의 어떤 부분)
- $q$ : text p에 관한 질문
- $a$ : answer
1.2. MRC vs. QA(Question Answering)
- 대부분 MRC task는 textual question task로 QA와 비슷한 형식.
- 하지만 포함관계는 아님
- MRC는 주어진 Context가 꼭 있고 관련된 질문에 답을 하는 문제.
- QA는 Answer를 얻기 위해,Context를 꼭 읽지 않아도 되는 task가 있음 (사람들이 흔히 알고있는 정보(상식, 생활정보 등)을 미리 알고있다고 가정하고, 때문에 규칙이나 상식과 같은 문제를 푸는 것들도 있음)
1.3. Classification of MRC Tasks
- 1.3.1. Type of corpus
- 1.3.2. Type of questions
- 1.3.3. Source of answers
- 1.3.4. Type of answers
Definition of each category
[Notations]
- $V$ : Pure textual vocabulary
- $M$ : Multi-modal dataset(consists of images or other non-text information)
- $P$ = { $C_i,Q_i,A_i$ } $_{i=1}^{n}$ : corpus
- $C_i$ = { $c_0, c_1,..., c_{l_{ci}}$ } : i-th context
- $Q_i$ = { $q_0, q_1,..., q_{l_{qi}}$ }: i-th question
- $A_i$ = { $a_0, a_1,..., a_{l_{ai}}$ }: answer to question $Q_i$ according to context $C_i$
- $l_{ci}, l_{qi},l_{ai}$ : the length of the i-th context $C_i$, question $Q_i$ ,answer $A_i$
1.3.1. Type of Corpus
(1) Multi-modal corpus : entities in the corpus consists of text and images at the same time
- $P ∩ V ≠ ∅$ and $P ∩ M ≠ ∅$
(2)Textual
- $P ∩ V ≠ ∅$ and $P ∩ M = ∅$

1.3.2. Type of Questions
(1) Cloze form
- 빈칸(placeholder)을 뚫어 노고 적절한 답(image, word, phrase)을 찾는다.
- 평서문 or 명령문
- multi-modal cloze style question(왼쪽) / textual cloze question(오른쪽)
- Given the context $C$ = { $c_0, c_1,...,c_j...c_{j+n},...,c_{lc}$ } ( $0 ≤ j ≤ lc, 0 ≤ n ≤lc − 1, c_j ∈ V ∪ M$ )
- $A$ = { $c_j...c_{j+n}$ } : short span in Context $C$
- Context $C$ 중에서 span $A$ 부분을 placeholder $X$ 로 대체하면 , 'cloze question $Q$ ' for context $C$ is formed.
- $Q$ = { $c_0, c_1,...,X,...,c_{lc}$ }
- $A$ = { $c_j...c_{j+n}$ } : answer to question $Q$
(2)Natural form
- Placeholder 없이, 문법을 잘 따르는 완벽한 문장
- 대부분 의문문
- exception ex) "please find the correct statement from the following options."
(3)Synthesis form
combination of words
not a complete sentence that fully conforms to the natural language grammar

1.3.3. Type of Answers
(1)Multi-choices form(객관식)
- Given the candidate answers $A$ = { $A_1,...A_j,..., A_n$ }
- n denotes the number of candidate answers for each question
- The goal of the task is to find the right answer Aj (0 ≤ j ≤ n) from A
(2)Natural form (주관식, 서술형)
- The answer is a natural word, phrase, sentence or image
1.3.4. Source of Answers
(1)Spans
- 답을 Context 내에서 추출하면 span
(2)Free-form
- A free-form answer may be any phrase, word, or even image (not necessarily from the context).

1.4. Statistics of MRC Tasks

"A fundamental characteristic of human language understanding is multimodality. At present, the proportion of multi-modal reading comprehension tasks is still small, about 10.53% ㅠ "
2. Evaluation Metrics
2.1. Accuracy
$$Accuracy = {M \over N}$$
- N :MRC task contains N questions (each question corresponds to one correct answer)
- M : the number of questions that the system answers correctly is M
2.2. Exact Match
- 정답이 문장이나 구문일 때 쓰임 -> Span prediction task에서 쓸 수 있음
- 모든 word가 같아야 정답임.
- multi-choice task 에서는 쓰이지 않음, because there is no situation where the answer includes a portion of the correct answer.
- 각 QUESTION마다 정답을 많이 만들어 놓으면 점수가 올라가겠다.
- bdml 연구실, bdml 랩실, bdml 랩 $$EM = {M \over N}$$
2.3. Precision ,Recall & F1-score
-
Precision: True라고 예측한 것 중에 진짜 True인 갯수 $$Precision = {TP \over TP + FP}$$
-
Recall : 실제 True 인 것 중 True라고 예측한 갯수 $$Recall = {TP \over TP + FN}$$
-
F1 score : Precision과 Recall의 조화 평균 $$F1 score = {2 \over {1 \over Precision} + {1 \over Recall}}$$
2.5.1. Token-level
- TP :denotes the same tokens between the predicted answer and the correct answer
- FP : denotes the tokens which are not in the correct answer but the predicted answer
$$Precision_{TS} = {TP_T \over TP_T + FP_T}$$
- ex) True label : 우석이의 다리 , Predicted label : 우석이의 어깨 Precision = 1/2
2.5.2. Question-level
- The question-level precision represents the average percentage of answer overlaps (not token overlap) between all the correct answers and all the predicted answers in a task
- TP : denotes the shared answers between all predicted answers and all correct answers $$Precision_{Q} = {TP_Q \over TP_Q + FP_Q}$$
- ex) True label : bdml 연구실, bdml, 빅데이터마이닝 연구실, 빅데이터마이닝 랩 , Predicted label: bdml 연구실, bdml, mcc Precision = 2/3
2.6 ROUGE & BLEU & Meteor
- summary task, 기계번역 같은 생성 모델 평가할 때 쓰이는 평가방법으로 mrc 평가에도 쓰임.
2.6.1. Rouge
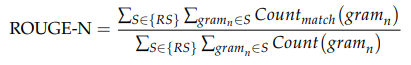

2.6.2. BLEU

- $P_n$ : modified n-gram precision


- $w_n$ : weight of n-gram -> summing to 1
- BP : 문장 길이에 대한 과적합 보정 reference가 10단어가 넘는 문장인데 candidate가 너무 짧으면 precision이 높은 점수를 받으니까 패널티를 주기위함 . candidate가 너무 짧으면 exp(음수) -> 1 보다 작음 .

2.6.3. Meteor
Unlike the BLEU using only Precision bleu의 단점 보완.


α 작은 수 줘서 , recall에 weight 많이 줌.

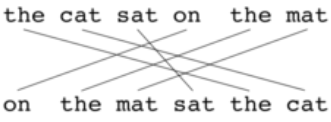
- ch : 3
- m : 6
- parameters α, β, and γ are tuned to maximize correlation with human judgment
2.9 HEQ Human Equivalence Score
- in which questions with multiple valid answers, the F1 may be misleading $$HEQ = {M \over N}$$
2.10 Statistics of Evaluation Metrics

3. Discuss open issues in MRC research and future research directions
4. Benchmark Dataset
이 섹션에서는 앞서 제안한 taxonomy 외에 데이터셋에 대한 속성들을 서술한다.
- 4.1. 데이터셋의 사이즈
- 4.4. 컨텍스트 타입 (paragraph, document, multi-paragraph 등)
4.9. Characteristics of Datasets
4.9.2. MRC with Unanswerable Questions
대답할 수 없는 질문에 대해 대답할 수 없음을 말하는 것도 MRC 모델에 요구하는 능력이다.
4.9.3. Multi-hop Reading Comprehension
단일 지문과 비교했을 때, 보다 여러 지문을 통한 정답 추론을 요구한다. (단서들을 통해 단계적으로 추론해야 알 수 있는 정답)
- A deep cascade model for multi-document reading comprehension (AAAI 2019)
- Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification (ACL 2018)
- Looking Beyond the Surface: A Challenge Set for Reading Comprehension over Multiple Sentences (NAACL 2018)
4.9.4. Multi-modal Reading Comprehension
오직 텍스트만 주어졌을 때, 정보가 부족한 문제들이 있다. 예를 들어, 이미지와 텍스트 양쪽에 대한 이해가 필요한 경우가 있다.
Multi-modal machine reading comprehension is a dynamic interdisciplinary field that has great application potential.
4.9.5. Reading Comprehension Require Commonsense or World knowledge
주어진 지문 속에서만 답을 찾는 전통적인 MRC와 달리, commonsense를 요구하는 데이터셋도 등장하기 시작한다. 논문에서는 이 분야에 대한 접근 방법은 서술하지 않음.
4.9.6. Complex Reasoning MRC
실제로 컨텍스트를 이해하고 추론을 수행하는 지 확인하는 데에 목적을 둔 데이터셋이다.
4.9.7. Conversational Reading Comprehension ⭐️
Conversational machine reading comprehension (CMRC). 저자가 말하길, 최근 NLP 분야에서 새로운 토픽으로 대두된다고 한다.
일련의 대화로부터 정보를 얻어내는 태스크이다. (최종 정답을 예측하기 위한 스무고개?)
여기서 대화(conversation)가 QA로 이루어져 있는 지는 확인해볼 필요가 있다.
사람이 특정 목적에 대한 정보를 얻기 위해 계속해서 질문을 던지는 것처럼, 모델도 연속적인 대화에서 필요한 정보를 추출할 수 있어야 한다.
이 때, 모델이 할 수 있는 것은
- 새로운 대화에 대한 적절한 대답 (ChatGPT?)
- 의미있는 새로운 질문을 묻기
원문 :
It is a natural way for human beings to exchange information through a series of conversations. In the typical MRC tasks, different question and answer pairs are usually independent of each other. However, in real human language communication, we often achieve an efficient understanding of complex information through a series of interrelated conversations. Similarly, in human communication scenarios, we often ask questions on our own initiative, to obtain key information that helps us understand the situation. In the process of conversation, we need to have a deep understanding of the previous conversations in order to answer each other’s questions correctly or ask meaningful new questions. Therefore, in this process, historical conversation information also becomes a part of the context.
In recent years, conversational machine reading comprehension (CMRC) has become a new research hotspot in the NLP community, and there emerged many related datasets, such as CoQA [49], QuAC [68], DREAM [83] and ShARC [39].
4.9.8. Domain-specific Datasets
컨텍스트가 특정 도메인인 데이터셋이다. 예를 들어, 과학이나 메디컬 리포트가 있다.
- CliCR: a Dataset of Clinical Case Reports for Machine Reading Comprehension (NAACL 2018)
4.9.9. MRC with Paraphrased Paragraph
같은 내용을 다른 말로 바꿔서 표현한 쌍을 포함하는 데이터셋이다.
4.9.10. Large-scale MRC Dataset
Large-scale dataset은 딥러닝 학습에 용이하다.
4.9.11. MRC dataset for Open-Domain QA
The open-domain question answering was originally defined as finding answers in collections of unstructured documents.