Introduction - Simsso/NIPS-2018-Adversarial-Vision-Challenge GitHub Wiki
Summary of a lecture by Ian Goodfellow at Stanford University
What are Adversarial Examples?
Definition

- an example input that has been carefully constructed in order to fool the network into making a wrong decision
Where do they appear?
- not just in CNNs, but also in logistic regression, SVMs, even in nearest neighbor algorithms
- there are also fun adversarial examples for the human brain (Pinna and Gregory, 2002)
Why do Adversarial Examples Exist?
1st Idea: Overfitting
- if the model has more parameters than it needs to fit the training data, it's susceptible to misclassify new inputs
- but: If this were true, adversarial examples would be random and therefore unique to a network. Experiments have shown that the opposite is true however.
The Systematic Effect of Adversarial Examples
- adversarial examples are transferable across networks and across network architectures
- if the delta |x - x*| of a clean image x and an adversarial example x* is added to another clean image y, the resulting image is often also adversarial
Linearity in Deep Networks
- in modern deep networks, the mapping from input to output is actually very piece-wise linear (e.g. due to activation functions like ReLU)
- however, the mapping from parameters to output is very complex - which is why training is not easy
- the near-linear mapping from input to output makes adjusting input images to the output (the inverse of training) very easy
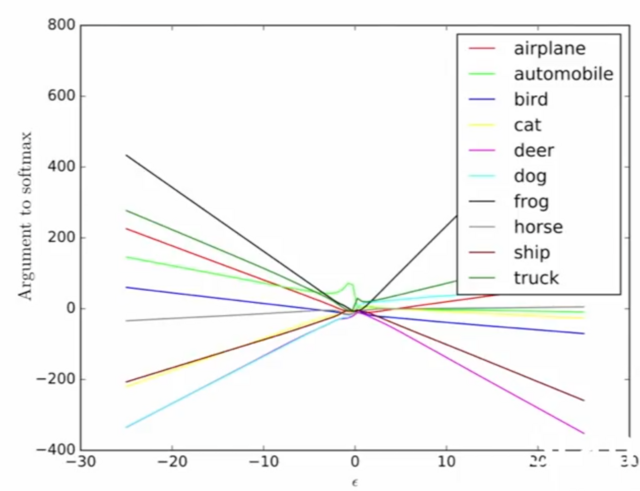
- above, one can see the logits values for specific classes - which behave very linearly as one changes the input image (a car) by eps * (small perturbation)
==> here, they found a perturbation direction that was associated with the frog class
Constructing Adversarial Examples
The Fast Gradient Sign Method
- idea: maximize the loss that a given input image causes in the network => calculate the gradient with respect to the input image and add it to the input image:
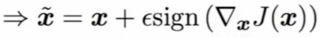
- the sign function here enforces the epsilon-constraint (the perturbation's max norm must be ≤ epsilon)
Maps of Adversarial and Random Cross Sections

-
legend on the left: FGSM vector is left-to-right and a random orthogonal direction is top-to-bottom (both applied by -eps to +eps)
-
on the right, the resulting 2D classification map (colors means incorrect class, white means correct class) of different CIFAR-10 are shown
-
observations:
- in most of the images, half of the map is classified correctly with a near-linear boundary
- FGSM has identified a direction where if we get a large dot-product with this direction, we can get an adversarial example
- adversarial examples live in linear subspaces (not tiny points in the input space) => all nearby images are also adversarial examples
-
how many dimensions do these adversarial subspaces have?
- on average: 25 (on MNIST where you have 28^2 = 784 total input dimensions)
- this tells you how likely you are to find an adversarial example from random noise
- also, the larger the subspaces for two models, the more likely it is that they intersect => transferable examples
The Idea of Clever Hans
- intuition: the model learns some distribution of training examples that seem "natural"
- with an adversarial example, one leaves this "natural" distribution which the network can't handle
Good Defense: RBFs
- when using the FGSM attack on these quadratic networks, you actually transform the image into another class
- ==> not technically an adversarial example
- however: RBFs have very poor performance
Adversarial Attacks
Black Box Attacks
- basis: cross-model and cross-dataset transferability
- idea: attacker wants to fool a network that he has no information about (architecture, type, dataset, ...)
- attack:
- train your own model mimicking target model
- create adversarial example for own model
- deploy adversarial example against the target
- in practice, about 70% of examples transfer cross-dataset
Enhancing Transfer with Ensembles
- idea: use an ensemble of many different models in order to create adversarial examples (Liu et al. 2016)
- => probability is almost 100% that the attack will be successful on another (target) model
Defenses
Defenses are very Hard
- many failed attempts
- regularization alone does not do the trick
- even using a generative model is insufficient
Adversarial Training
- neural nets can represent any function, but max-likelihood does not cause them to learn the right one
- idea: train on adversarial examples
- works quite well (for FGSM attacks), but not for other, iterative attacks
- interesting effect: training on adversarial examples makes the classification task better (it can be seen as a kind of regularization)
- these adversarially trained networks have the best empirical success rate
Virtual Adversarial Training
- use unlabeled data: use model guess for an image, create adversarial perturbation intended to change the guess
- idea of semi-supervised training: use labeled and unlabeled data
Why is Solving the Adversarial Problem so Interesting?
- on the one hand, it prevents attackers from causing the network to make a wrong decision
- but on the other hand, one could use it to design molecules, fast cars, new circuits, etc.
- why? because then the attacks do not create adversarial examples that trick the network, but instead apply a perturbation to the input that "makes sense"
- example: use the blueprint of a car as input, train network to guess the car's speed, apply perturbation to the blueprint that increases the speed the network assigns to the blueprint => get a blueprint of a fast car instead of an adversarial example