Google Cloud Platform - Simsso/NIPS-2018-Adversarial-Vision-Challenge GitHub Wiki
Google Cloud Platform: Products and Capability Analysis
Intro
This section analyses the products and overall capabilities of Google Cloud Platform. It will cover all products, but delve into products, which could be more interesting for our specific use case. A profound objective analysis of GCP is required, because a decision regarding the choice the deployment infrastructure has to be made soon, which will ultimately affect future research.
Our Use-Case
Attention: These requirements are general and not final!
The goal is to create and deliver a CNN-model, which is immune against adversarial examples generated using the delivered model and different attack methods. The process of creation of such a CNN-models includes besides programming the actual model using Python/TensorFlow, the training, testing and generating of scores.
Training
Every given model has to be trained against the given dataset. Due to the fact there is currently no planning in using different datasets for different models, a single storage of all training jobs is sufficient. This single storage should have a reliable and fast connection to all training processes and no problems with concurrent reads. The training is the most time and computation consuming phase. As we expect fast response in generating final scores to leverage our capability to test new ideas instantly, each training process should be optimised in model and use GPUs to help achieve our goals. As we plan to train large number of models with different parameters, cost-functions and ideas, a streamlined parallelizable training process and monitoring of the training, testing and evaluation (generating scores) is urgently needed.
Testing
Once a model was trained successfully is has to be tested and validated against a subset of samples from the given dataset. This process has the same process requirements as the training process. It should start right after the training process. Afterwards the model should be saved into a central storage.
Evaluation
The evaluation of the model should start right after the validation. As the model is attacked using the top-five attacks submitted by others in the competition, it is necessary to integrate these attacks into the evaluation process. The evaluation process should be implemented for each attack as already discussed in the 1. Working Group Meeting. The results (generated scores) and any further information about each attack should be stored in a central storage for future analysis. As the top-five attacks are chosen bi-weekly by the jury and the calculation of the score for each attack is the same process, it is necessary to be able to inject attacks dynamically and run attacks on our chosen models again.
General
All kind of information about the infrastructure (such as resource consumption), deployments, training, testing and evaluation should be saved.
Google Cloud Platform Products
Google Compute Engine (GCE)
General Information
- Create VM instances of public or private images
- Own images can be uploaded to GCP and consumed instantly
- VM instances creation is very fast (ca. 15 secs for a full started instance GCP at IO 2017)
- Each instance belongs to GCP project, a project can contain one or more instances
- There are several machine types one can chose from (up to 160 cores, 360 GB of RAM and GPUs)
- By default each VM has a small persistent disk, which can be dynamically extended on need using different storage options
- In General a GCP project can have up to five VPC (= Virtual Private Cloud) networks (literally the same as a VPN)
- Instances of the same network can directly communicate using the VPC, any other communication is done using the internet
- It is possible to run Docker containers on VM instances. GCP takes care of all configuration and starting overhead. VM instances which run containers are treated like a normal instance. This kind of deployment allows the user to have full control over their underlying VM infrastructure. By creating so called instance groups, one is capable of autoscaling, rolling updates, etc.
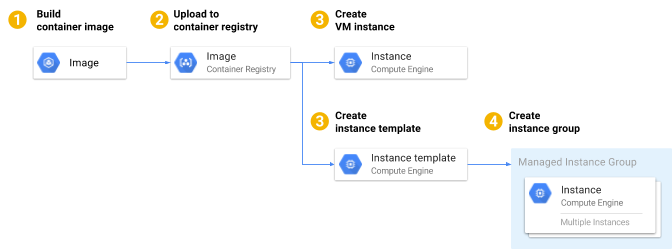
Peek: Deploying Containers on VM instances in GCP Compute Engine
- Developers bundles application and all required libraries into Docker image and upload it to the GCP Container Registry.
- Specify the
docker run-command. - Request Compute Engine to spin up an instance.
- Compute Engine creates the instance or an instance template with Container-Optimized OS image
- Compute Engine pulls the container image from the GCP container registry and starts it using the previously specified
docker run-command.
Limitations
- Only one container for each VM instance
- Only container-optimised OS images
- Not accessible using GCloud API
Please consider the comment of GCP before using VM instances to deploy Docker Containers:
Running each microservice on a separate VM on Compute Engine could make the operating system overhead a significant part of your cost. Kubernetes Engine allows you to deploy multiple containers and groups of containers for each VM instance, which can lead to more efficient host VM utilization for microservices with a smaller footprint.
Google K8s Engine (GKE) (previously Google Container Engine)
General about GKE
- Reduces the overhead to setup a whole K8s cluster to zero by providing managed K8s clusters. User just deploys the cluster with a specific number of nodes/pods and configuration they want. It consists of multiple Compute Engine instances, which are coupled together to a K8s Cluster.
- Specialised hardware accelerators are generally available (in our case GPUs) and are managed automatically by the underlying infrastructure.
- Fully configurable: User decides how much resources should be assigned to single node (containing pods), pods (containing group of containers)
- The Container Engine works in full harmony with the Google Private Container Registry, where one can securely upload Docker Images.
- Not only made for stateless applications: Persistent storages can be dynamically added during runtime.
- High availability: Due to automatic health check by K8s, crashed Containers can be restarted automatically.
- Scalable: During high-load K8s can spin up new containers to handle all incoming requests asap.
- Secure: Configure one publicly exposed IP, all other communication is made in the VPC. This means containers running in K8s can easily connect with services running in the same VPC.
- Logging: Output of the Docker containers can be automatically persisted to a central data storage
- Monitoring: Using the so-called Stackdriver API by GCP, one is able to collect in-depth metrics
- K8s Master Nodes are automatically upgraded, once a stable and not breaking version is available
K8s Cluster Architecture
- Consists of (at least) one cluster master and several workers (aka nodes)
- Master and nodes represent the whole K8s cluster. The containerized applications run on top of them.
K8s Master
- The master represents the center of K8s control plane containing the unified endpoint mapping to the K8s API server, scheduler and core resource controllers.
- The cluster master is responsible for deciding what runs on all of the cluster's nodes. This can include scheduling workloads, like containerized applications, and managing the workloads' lifecycle, scaling, and upgrades.
- The K8s API Server represents an endpoint where all interactions with the cluster is done from extern. It can be directly accessed using HTTP,
kubectl, or the K8s cluster UI. Furthermore, all internal communication is being handled by the master K8s API server, where internal components such as nodes act as clients. The K8s API server is the single source of truth for the entire cluster. - A cluster's master lifecycle is managed while creating and deleting a K8s cluster
K8s Node
- A typical cluster has one or more nodes, which are responsible for running containerized applications (GCP: workloads). A K8s Master represents a node too.
- Each node is an individual GCE VM instance and is fully managed by the K8s Master.
- Each node runs a full environment to run Docker containers and the node agent
kubelet(for communicating with the master)
K8s Pod
- A pod is the smallest architectural unit in K8s, which is associated with a node. This means that pods run on K8s nodes.
- Generally speaking each pod runs exactly one container such as a Docker container. But still there are advance use-cases, where multiple containers run in one pod, sharing resources and are treated as one entity by K8s master.
- Each pod is automatically assigned to a unique IP address. Containers within a pod can communicate over
localhostand share the given storage in the pod. - In general K8s creates replicas of a given pod for better availability, distribution of incoming workload and possibility to roll updates without shutting down your services.
- K8s pods are one shot / ephemeral. This means, once a pod dies due to some unknown error K8s master deletes it without trying to fix the error and starts the same container again. This can be only done, due to microservice architecture, where applications do not have a state.
You can consider a Pod to be a self-contained, isolated "logical host" that contains the systemic needs of the application it serves.
Google Container Registry
- GCR is a private Docker image registry running on top of the GCP infrastructure.
- It includes the Google Container Builder and Google Container Builder Triggers.
- One only pays for the storage (GCR uses the products GCS for storing images), build time if automatic builds are used and egress.
- Images pushed to GCR are available project-wide in GKE and GCE, cached in the given data-center for highspeed deployments.
Google Container Builder
GCB is part of Google Container Registry, but due to it's advanced functionality it will be explained as a standalone solution.
- GCB is a service to build container images from several sources on GCP infrastructure
- The main focus is on executable application, which can be imported directly into GCP from diverse platforms such as Github, GCS and Google Source Repositories
- In GCB one can use a build config. Primarily a build config consists of multiple build steps, which are sequentially executed by GCP.
- Each build step is either a build step provided by GCB, a community-driven build step or an own build step. One can think of a build step as an application, which runs in its own docker container and providing the tools to perform a specific task on your source code e.g. mvn build, Docker build, .. .
- Beside a build config one can simply use a Dockerfile to specify the Docker image.
- Build processes can be started by using the gcloud console or initiating a build using Google Container Build Triggers.
Example build config:
{
"steps": [
{
"name": "gcr.io/cloud-builders/docker",
"args": ["build", "-t", "gcr.io/nips-2018-207619/$TAG_NAME", "deployment/$TAG_NAME/"],
"timeout": "500s"
},
{
"name": "gcr.io/cloud-builders/docker",
"args": ["push", "gcr.io/nips-2018-207619/$TAG_NAME"]
}
]
}
In the following example two separate build steps are sequentially executed:
- A Docker image is generated using a GCP-provided build step and using a Dockerfile located at
deployment/$TAG_NAME. Furthermore it is tagged for later reuse. Environment variables such as$TAG_NAMEare automatically injected by GCB during runtime. - The previously generated image is now pushed to the Google Container Registry.
Google Container Build Triggers
- Beside executing build steps manually by using gcloud-console, one can initiate automatic building of images using so called triggers.
- One can specify where (branch, global) and when (each commit, specified tag-name with regex) a specified build should be triggered. These rules are called triggers. GCP uses webhooks to detect these.
- Please refer to this for an example on GCP.
- Build triggers are the heart piece of Continues Delivery. Continues Delivery means that the amount of time spent in operations is reduced to a minimum.
- Developer does a bugfix / implements a feature in a branch.
- Unit tests and integration tests are run for each commit.
- Developer creates a PR, which is also tested against the target branch.
- Once the target branch has reached a development status, the Product Owner tags the latest commit as new release in the release branch (should include manual testing such as e2e-testing).
- The pipeline is automatically triggered, executing all defined build steps e.g. testing the tagged commit again with all tests, stress tests, aliveness tests, measurements m.m.
- If defined as a build step, the pipeline can roll-out (deployment) the new given image on production, which should be stable enough. (Using GKE there is no down time, users won't even notice changes in the application)
Cloud Machine Learning Engine
- The ML Engine builds on top of GKE and enables developers to train machine learning models at scale
- As ML Engine represents another abstraction layer, developers don't need to configure the underlying infrastructure as GCP completely takes the responsibility for this.
Cloud ML Engine manages the computing resources that your training job needs to run, so you can focus more on your model than on hardware configuration or resource management.
- Trained models can be hosted directly using Cloud Machine Learning Engine.
- Developers develop their python trainers as it would be any other Tensorflow application with regard to some guidelines for the best ML Engine integration and make them accessible through GCS for the ML Engine.
- Training Jobs are divided and run on multiple K8s Nodes. Specification regarding the deployment are predefined in the trainer by the developer. This includes e.g. number of instances, GPUs or amount of RAM.
- Once a training fails or exits successfully, allocated resources are automatically freed up. Meaning no additional costs, due to forgotten VMs.