Hash Table (Java) - ShuweiLeung/Thinking GitHub Wiki
ArrayList<Entry<Character, Integer>> list = new ArrayList<>(map.entrySet());
Collections.sort(list, new Comparator<Entry<Character, Integer>>(){
public int compare(Entry<Character, Integer> a, Entry<Character, Integer> b) {
return b.getValue() - a.getValue();
}
});
1.(771:Easy)Jewels and Stones
- 该题很简单,一种通常的做法是用HashMap来存储宝石及其对应数量,然后遍历石头判断是否为宝石,若是则将宝石数量加1。
- 另一种更便捷的方法是,直接使用字符串的indexOf方法来定位石头中的字符,若返回值大于等于0,说明该石头是宝石,将总数加1即可。
2.(811:Easy)Subdomain Visit Count
- 该题也是HashMap键值映射的简单应用,此外还需要用到字符串的split方法。
3.(500:Easy)Keyboard Row
- 该题只需要将每一行的字母放作各自的字符串中,然后对每一个单词的每一个字母都作定位,查看是在哪一行里,若前后两个字母不在同一行,则该单词不符合条件。
- 将ArrayList列表转化成字符串数组有两种方法:一种是朴素解法,新建一个相同长度的字符串数组,然后一个元素一个元素的赋值;另一种方法是(String[]) list.toArray(new String[list.size()]),但该方法非常耗时,虽然简单,但效率极低。
4.(575:Easy)Distribute Candies
- 该题只需要在遍历过程中控制两个条件:1. 搜索范围是整个candies数组 2. 姐姐持有的糖果种类要小于等于糖果总数的二分之一。 在上面两个条件同时满足的情况下,我们才进行求解姐姐持有的糖果种类
- 我们用HashMap来存储姐姐持有的糖果种类(理论上使用candies长度+1的数组也是可以的,效率可能会更高),key为糖果种类,value为糖果数量,我们通过containsKey方法可以直接判断姐姐是否有该类型糖果,一次读取便可获得信息。
5.(463:Easy)Island Perimeter
- 通过观察我们可以发现,对一个land方块而言,它所贡献的边长是“4-与它相邻的land个数”。因此,我们从遍历grid,若当前的grid[i][j]=0,直接略过,否则计算该快land共享的边长数。
6.(136:Easy)(非常经典题)Single Number
- 最直接的方法就是设立一个HashMap,key是nums中的元素值,value是该值的出现次数,最后返回出现次数为1的值即可。
- 因为该题没有说长度为n的nums数组元素在[1,n]之间,所以我们不能用Array类一道题目中的,置下标索引与其值相同的元素值为自身的相反数。
- 没有使用额外空间的解法是:利用异或操作Bit Manipulation。异或的性质1:交换律a ^ b = b ^ a,性质2:0 ^ a = a(相同元素异或为0,不同元素异或为1)。于是利用交换律可以将数组假想成相同元素全部相邻(调换元素位置不影响异或结果),于是将所有元素依次做异或操作,相同元素异或为0,最终剩下的元素就为Single Number。
7.(690:Easy)Employee Importance
- 该题首先用一个HashMap来存储每个员工的信息以便之后一次性存取,key是员工id,value是该员工对象。之后我们用递归来求给定id的员工及其下属的价值总和。
8.(389:Easy)(经典题)Find the Difference
- 自己设置一个ArrayList,然后将s中的每一个字符都存储进去,接着遍历t字符串,只要list中存在t的当前字符,则删除它,若不存在,答案就是该字符。
- 另一种Map的解法和String类型题的套路一样,用长度为26的数组记录每个单词的出现次数,首先根据s记录每个字符的频率,然后再遍历t字符串,减少频率,最后若某个字符的频率不为0,则答案就是该字符。
9.(349:Easy)Intersection of Two Arrays
- 该题利用Set/Map来存储nums1中元素和一个ArrayList存储返回结果,通过在nums2中判断nums1中是否有该元素,来决定是否将该元素加入结果集中。
10.(242:Easy)Valid Anagram
- 用长度为26的int数组作为Map来统计字母频率即可。
11.(447:Easy)(非常经典题)Number of Boomerangs
- 该题要求得每两点间的距离,并取得相同点距离的集合。我们可以把每个点都看作一个参考点a,用HashMap存储其他点到参考点的距离及对应的其他点的数量,然后遍历当前参考点的map映射集合,对于某个距离d而言,与参考点距离为d的点的个数有m个,则从中任取两个元素与参考点构成一个tuple的情况有m*(m-1)种。按上面的思路,需要把每个点都当做一次参考点,最后所有情况的数量就是结果。
12.(599:Easy)(经典题)Minimum Index Sum of Two Lists
- 我们用一个map存储list1中的所有字符串及其下标索引,当我们遍历list2时,维护一个最小索引和的变量,并且当list2中字符串已经存在于map集合中的情况下,才去更新这个最小索引变量(一边遍历list2,一边比较更新该索引和变量),当当前“字符串的索引和”比之前“字符串索引和”还小的时候,我们清空res结果集之前的记录,重新添加与当前“索引和”相等的字符串。
13.(409:Easy)(非常非常经典题)Longest Palindrome
- 维护一个最长回文串长度变量sum。对于每个字符都统计其数量,一开始只将出现偶数次的字符算在sum中,此外,只选取出现奇数次最高的字符加入到回文串中,显然这是"错误"的。
- 正确的思路应为:当某个字母出现次数为偶数次数的时候,这个最大回文子串必定会使用全部的出现次数;当某个字母出现的次数为奇数次数的时候,生成的最大回文子串必定会使用次数-1次出现次数(将奇数次转化为偶数次);当某些字母出现1次的时候,这个只会使用其中的一个字母(实际上这是在将奇数次字符全部转化为偶数次字符后,看看是否有出现1次的字符加到回文序列的中央,其实是将最后遍历的奇数次字符全部都加到回文序列中)。
14.(350:Easy)Intersection of Two Arrays II
- 该题只是在第9题(349)的基础上,要求返回的结果集中,重复的字符出现次数要和在两个数组出现次数的最小值相等。
15.(720:Easy)(非常非常经典题)Longest Word in Dictionary
- 该题最好先做过Leetcode 第208题,因为有一种思路会用到前缀树。
- 前缀树的思路其实会更复杂,还有更简单的方法。其实该题的题意个人感觉比较难理解,简单来说,该题满足条件的字符串应有如下特点:对与"apple",它的所有前缀均满足条件,即"a","ap","app","appl",即他们均可以一步一步由其他word构建。当我们从0构建集合的过程中,只要"appl"存在于集合,那么"apple""apply"就是满足条件的,因为"appl"及其前缀也是迭代的满足条件的。
- 为了方便处理,我们应先将输入的数组按"长度大小"和"字典序"排序,让短的字符串考前,让长度相同的情况下,字典序小的字符串靠前排列。这样当我们从左至右遍历数组的过程中,遍历到某个单词"abcd",只要可建立集合set中存在它的前缀"abc",那么"abcd"就是可构建的(根据集合的迭代构建)。具体实现细节可以参看代码实现和参考讲解视频。
- 参考链接:简单方法讲解 复杂全面方法讲解
16.(594:Easy)(非常经典题)Longest Harmonious Subsequence
- 该题虽然涉及到Subsequence,但其实与subsequence没有多大关系,或者说subsequence中的元素位置对该题没有影响。题目中说道最大最小元素值只能差1,所以说明该subsequence只能由一种或者两种元素构成。
- 题目的关键就是用一个map集合来存储数组中各个元素以及各个元素的出现次数,然后遍历map集合,看看是否有比当前元素值大1的元素存在,若存在则计算这两个元素出现的次数之和(即subsequence的长度),并与之前已求出的longest subsequence长度进行比较。
- 这里的map集合可以选择TreeMap,该集合在存储时自动按照key值升序来排列,所以之后遍历的时候我们只需要比较后一个元素的值与前一个元素的值是否差1,若相差1则求其出现次数之和。当然也可以用普通的HashMap,之后遍历的时候只需要通过map.contains(key+1)判断是否有比当前元素大1的元素值存在。
- 从上面的分析可以看出,元素在数组中的位置并不影响结果,即3223和2233效果是一样的。
<17>.(205:Easy)(非常经典题)Isomorphic Strings
- 一开始解决问题的思路是:把类似于“paper”和“title”的单词全部转化为“ABACD”形式表示,然后比较他们转化为统一表示后值是否对应相等 beat 10%
- 之后在accept答案中非常高效的一种解法:存储每个字符最后一次出现的位置,而不是严格意义上的寻找映射关系。即对于s字符串和t字符串的第i个位置字符,我们判断这两个串中对应的字符上次出现的位置是否相同,若不相同说明这两个字符不能严格对应,若相同就可以继续比较。该思路beat 80%。
- 上面的第二个思路并不是严格意义上的字符映射,我们可以也设立两个长度为257的数组(ascii表共256个字符,数组初始化为0):一个是int类型的smap,它代表s串中字符与t串字符的映射关系;一个是boolean类型的tmap,它代表t串中字符与s串中字符是否已经建立了映射关系。该思路beat 84%,具体思路见下边代码及注释:
public boolean isIsomorphic(String s, String t) {
int[] smap = new int[257]; //asc码的值从1-256,代表s中字符映射的字符
boolean[] tmap = new boolean[257]; //true代表该字符已经被映射使用
for(int i = 0; i < s.length(); i++) {
if(smap[s.charAt(i)] == 0) {
if(tmap[t.charAt(i)] == true) //即t串中该字符之前已经被映射使用过了,不能再映射。即一个字符不能映射两个值,返回false
return false;
smap[s.charAt(i)] = t.charAt(i); //t串中该字符之前没有被映射过才能继续比较
tmap[t.charAt(i)] = true;
}
else {
if((char)smap[s.charAt(i)] != t.charAt(i)) //对于已经建立映射关系的字符,查看s中该字符之前映射的字符与当前t中第i个字符是否相同
return false;
}
}
return true;
}
<18>.(438:Easy)(非常经典题)Find All Anagrams in a String
- 该题最直接的方法是:从左至右遍历s串,对于每一个位置,都比较s中从当前位置开始长度为p的子串是否与p相等。比较的方法也同样是利HashTable,在某一时刻看当前元素出现的次数是否与另外一个子串中对应元素相同,代码如下,比较a、b两个字符串是否相等:
public boolean helper(String a, String b) {
if (a == null || b == null || a.length() != b.length()) return false;
int[] dict = new int[26];
for (int i = 0; i < a.length(); i++) {
char ch = a.charAt(i);
dict[ch-'a']++;
}
for (int i = 0; i < b.length(); i++) {
char ch = b.charAt(i);
dict[ch-'a']--;
if (dict[ch-'a'] < 0) return false;
}
return true;
}
上面该粗暴的直接做法也能accept,但只beat 8.72%。Discuss中高效解法是滑动窗口算法,且有人给出了滑动窗口算法的模板,没怎么看懂,下次复习时再和同学一起研究讨论
参考链接:Sliding Window algorithm template to solve all the Leetcode substring search problem.
19.(290:Easy)(非常经典题)Word Pattern
- 该题其实和第17题(205)的本质一模一样,但因为该题中str是一个以空格分隔的单词组合,即我们将str分隔成数组后,元素是长度大于1的字符串,所以只能使用第17题(205)的第三种思路来解决。又考虑到str分解后的数组元素是单词而不是字符,所以我们这里将smap作为单词向pattern中字符映射的HashMap,key是String单词,value是其映射到pattern的字符;同样用pmap来表示pattern中字符是否已经有映射关系,只不过此处pmap仍是长度为257的boolean数组。具体实现过程参看代码实现,breat 96%。
20.(739:Medium)(非常经典题)Daily Temperatures
- 该题使用堆栈,从左往右遍历,对不能处理的元素先存入堆栈,堆栈中元素是降序排列的,即栈顶元素最小。直接看代码实现和备注来理解该题的求解思路,beat 73%:
public int[] dailyTemperatures(int[] temperatures) {
Stack<Integer> stack = new Stack<>();
int[] res = new int[temperatures.length]; //数组初始化时元素值为你0,所以在下面for循环中未处理的元素值就为0,同时也说明这些元素的值非常大,后面没有比它们更大的元素
for(int i = 0; i < temperatures.length; i++) {
//注意是while循环,当i位置比之前位置元素值大的时候,循环判断是否比之前堆栈里所有元素都大,而不是只判断和当前栈顶一个元素的关系
while(!stack.isEmpty() && temperatures[i] > temperatures[stack.peek()]) {
int top = stack.pop();
res[top] = i - top; //注意处理的是数组下标为top的结果
}
stack.push(i); //注意存入的是i,位置下标,若temperatures[i] > temperatures[stack.peek()],则在上面的while循环中已经处理了比temperatures[i]小的元素,所以堆栈中元素是降序的,栈顶元素最小
}
return res;
}
- 该题好像是leetcode 496题的扩展
21.(451:Medium)(非常经典题)Sort Characters By Frequency
- 该题其实解决思路还是比较简单的,就是统计每个字符的频率,然后按频率从高到低输出字符即可,但关键是如何获取词频并由高到低进行排序。
- 该题显然使用Map来解决,但在初始化Map时无法建立一个按value值排序的比较器,只能建立按key值排序的比较器。若需要按value值排序,我们需要另外借用Collections的方法,在使用Collections.sort()方法时,参数中传入一个比较器对象参数才可以。(beat 52%)
- 参考链接:Map按Key和Value分别进行排序
该题除了利用比较器进行排序以外,Discuss中貌似还有不借用比较器进行排序的方法,下次复习时研究学习
22.(748:Medium)(经典题)Shortest Completing Word
- 因为licensePlate中存在非字母字符,所以一开始想用正则表达式过滤出非字母字符,但后来发现并没有必要,我们在遍历licensePlate的时候判断当前字符的asc码是大于等于'a'同时小于等于'z',那么该字符一定就是字母。正则表达式过滤很耗时。过滤出字母后,我们就可以统计出每个字符的频率map,该map集合用长度为26的int数组实现。
- 之后遍历words数组,因为每个word都需要以map数组作参照,所以我们并不直接在map数组上进行运算,而是对每个word都新建一个长度为26的int数组,通过统计出单词字符的频率后与map数组作比较,求出答案。具体的实现细节直接参看代码实现。(beat 55%)
23.(347:Medium)(非常经典题)Top K Frequent Elements
- 该题一种思路和第21题(451)一样,通过使用Comparator自定义比较器,将map集合中键值对按value值大小降序排列,最后输出前k个key即可。(beat 50%+)
- 另外一种方法是,建立好map集合后,再次遍历map的keyset,建立一个以频率排序的数组,数组元素存储的是频率为当前下标的元素列表集合,之后从该数组的最后一个位置往前遍历,当元素值不为null时,添加进res结果集中,直到res结果集中有k个元素为止。简单来说,先建立key-value映射,之后又根据keu-value映射关系建立value-key映射。具体实习参考代码。(beat 89%)
24.(676:Medium)Implement Magic Dictionary
- 我这道题的实现思路是,构建一个map集合,key存储dict数组中单词的长度,value是该长度的单词集合。那么在搜索某个单词时,首先判断map中是否有该长度单词存在,若不存在直接返回false。之后遍历map中该长度单词集合,比较相同位置字符是否相等,若不相等则将diffNum(专门记录不相同字符数的变量)加1,若diffNum > 1,则该单词一定不可能只修改word的一位获得,所以直接跳过该单词。
- 注意:即使输入的word与map中对应长度的某个单词一模一样,也判定为false,因为题目要求一定要改变一位,若相同单词改变一位后肯定就不同了。
上面的实现思路beat 95%,discuss中可能还有其他思路,下次复习时再参看
<25>?.(648:Medium)Replace Words
- 该题容易想到的方法是:将字符串以空格作为间隔拆分成数组,然后对每个单词,使用indexOf()方法搜索dict前缀中有没有匹配项,有则将匹配项加入结果集中,没有则将原来单词加入结果集中,beat 17%。
- 另外一种思路是使用前缀树。
该思路之前没有接触过,相关算法及数据结构也没有学习,等下次复习时再研究,该方法更高效,大概是第一种思路的四到五倍。
26.(648:Medium)(非常经典题)4 Sum II
- 该题一开始尝试按照Leetcode 第18题4 sum的思路求解,但需要做一些额外的准备工作:将四个数组中的元素及其所属集合分别在map中记录,然后将4个数组合并为一个数组并排序,之后使用4指针解法(同LC 18题),只是在每次求得一个符合条件的4元素元组后,需要判断4个元素是否来自4个不同的集合。但是,该方法涉及到大量的集合建立、读取、以及数组元素复制的操作,理论上思路正确,但“超时”。
- 正确的方法并不是使用集合的复制、合并等,而是从A、B集合中各取两个值存入map集合,value是该两数和的数量,同时从C、D集合中各取两个值,它应该是A、B集合中两元素和的相反数。即,Take the arrays A and B, and compute all the possible sums of two elements. Put the sum in the Hash map, and increase the hash map value if more than 1 pair sums to the same value.Compute all the possible sums of the arrays C and D. If the hash map contains the opposite value of the current sum, increase the count of four elements sum to 0 by the counter in the map.
- 注意:What about the other combinations like (B,C), (A,D), (A,C) and (B,D)?
Let us take the four numbers as :1,2,-6,3
Possible combinations are:
(1+2) and (-6+3) (1-6) and (2+3) (1+3) and (2-6) (2-6) and (1+3) (2+3) and (1-6)
In all the above cases, as you can see, the total sum is Zero. So, we can choose to combine any two arrays and we get the same result.
该题好像还有binary search的解法,下次复习时再研究
27.(554:Medium)(非常经典题)Brick Wall
- 该题其实需要从每行公共长度最多的位置切下,那么穿过的砖块数量就是最少的。因此我们用一个HashMap来存储每一行以砖块为分界点的不同长度数量,取其中公共长度数量最多的地方向下且,即是答案,墙的高度减去这个公共长度最多的数量就是答案,具体的思路见下边代码:
public int leastBricks(List<List<Integer>> wall) {
if(wall.size() == 0) return 0;
int count = 0;
Map<Integer, Integer> map = new HashMap<Integer, Integer>(); //key是每一行的每一块砖块截止位置的长度,value是该长度在每一行的个数
for(List<Integer> list : wall){
int length = 0;
for(int i = 0; i < list.size() - 1; i++){
length += list.get(i);
map.put(length, map.getOrDefault(length, 0) + 1);
count = Math.max(count, map.get(length)); //取公共长度最多的位置来切,count是每一行有该长度的数量
}
}
return wall.size() - count;
}
28.(525:Medium)(非常经典题)Contiguous Array
- 该题一开始想要DP动态规划做,但发现递推式并不容易推导出来,每一项状态互相牵扯的因素有很多。
- 正确的思路当然还是使用Hash表:先将所有的0元素全部都改为-1,这样的话,如果找到sum(i,j)==0,那么说明从i到j是一个连续的满足条件的子数组。累计计算从开始位置到目前遍历位置的所有元素值之和,然后查看map集合中有没有与当前sum和值一样的记录,若有的话,说明从之前求得该sum值的索引下标start开始,到当前遍历位置的索引下标end之间的元素值之和为0。例如前10个元素和为10,前20个元素和也为10,说明从第11到第二十之间的元素和为0,且是连续的。map集合的key是sum值,value是第一次求得该sum值的位置索引。
- 注意:当我们当前求得的sum已经存在于Map集合中时,并不更新该sum值对应的value(最开始的下标索引),因为我们要取最长的contiguous Array。
29.(692:Medium)(非常经典题)Top K Frequent Words
- 该题完全参照第23题(347)第二种思路做即可,beat 85%。同样也是先建立word-frequency的map集合,然后再遍历一遍map集合,建立frequency-words的映射集合(用数组实现),然后根据频率从高到低添加进结果集中返回即可。
30.(36:Medium)(非常经典题,面经题)Valid Sudoku
- 该题复杂中透着简单,简单中透着复杂。其实,如果该题只考虑行列两方向的元素不重复情况,时间复杂度一定降低很多,但现在题目还要求小的3*3九宫格元素也不能重复,于是就衍生出两种方法。
- 我在解决这道题的时候,用的是相对容易想到的方法,但却又比容易想到的方法更高级一些,因为我用到了哈希表来判断当前元素行、列方向的元素重复情况,而对sub-box则是用最粗暴的暴力解法来判断的。具体来讲,我设立了两个二维数组rowCheckbox和colCheckbox来判别行列方向的重复情况,每个二维数组共9行、10列,rowCheckbox行号与board行号对应,rowCheckbox列号是该行中出现的数字;同样,colCheckbox行号与board列号对应,colCheckbox列号是该列中出现的数字。元素值为1代表出现,0代表未出现。而对于元素(i,j),它属于的sub-box在“行方向”上一定是第i/3个,“列方向”上一定是第j/3个。该题的具体思路直接参看代码实现,里面有详细注释,该思路beat 85%。
- 该题另外一种思路是利用set来判别行列方向元素重复情况,但在判断行情况的时候,利用坐标的交换来同时判断列的情况,即当前元素是(i,j),i不动,增加j,扫描的是第i行。但交换i、j后变成了(j,i),i不动,增加j,扫描的是第i列。此外在判断sub-box时,也巧妙使用了i、j坐标和sub-box的关系进行3*3九宫格的判断。该方法具体思路请参看“参考链接”。不知道为什么该题目的运行时间还不如第一种情况。
- 注意:数字字符(如:'5')转int型只能用c-'0',Integer.valueOf()函数只能解析字符串不能解析字符!
参考链接:两种方法的详细思路讲解,该视频中第二种方法与自己实现有区别,他讲的是纯暴力的,但自己的却使用了Hash Table
31.(299:Medium)(非常经典题)Bulls and Cows
- 该题其实讲解的比较复杂,在实现时,如果整理好思路,解法还是非常清晰的。该题需要注意的一点是:对于例子中的secret = "1123", guess = "0111",hints是"1A1B",说明对于guess中未完全匹配的第二个与第三个'1',我们只能取其中一个算作cow,因为在secret中,总共只有两个'1',而secret的第二个'1'已经算作bull,所以算作cow的数量只能有1个。在理解该混淆处之后,我们就可以写代码进行实现了。
- 总的思路就是遍历两个字符串,看在某个位置是否相等,如果相等,就A++;如果不相等,就把secret中的字符和guess中的字符再分别存起来;然后再遍历第二遍,第二遍的遍历就是,经过处理的guess字符,会不会在经过处理的secrets的字符里面。如果在,就B++,表明只是放错了位置而已。
- 具体而言,“第一次遍历”时,我们选出符合条件的字符,即位置相同且字符相等的位置,并且算出A的系数,并将secret中未匹配的字符及对应数量存储map集合中,同时将guess中未匹配的数量存入list集合中。“第二次遍历”时,现在guess中的字符与map中的字符一定是不完全匹配的,最多只是字符相同但位置不同,但又考虑到不匹配字符数量的问题,所以我们遍历list集合,如果该集合未出现在map集合中,则直接跳过,否则说明这是一个cow,将该字符在map集合中的value值减1,当该字符数量减1后变为0时,说明即使之后再出现该字符,我们也不会将其算作一个cow,所以将该字符的key-value在map集合中删去。
32.(274:Medium)(非常经典题)H-Index
- 我的实现方法是暴力破解,即因为题目中的要求是"at least"和"no more than",所以h是一个边界条件,对于当前遍历的文章,既可以有一部分文章当做at least,也可以有一部分文章当作no more than,即脚踏两条船,所以对于每一个有着相同引用数量的文章,我们都用一个for循环,将其一部分归为“no more than”类别,一部分归为“at least”类别。假设我们当前遍历的文章有t个引用,即这里假设有t个引用的文章有n个,那么其中i个被归为"no more than"类,其他n-i是"at least"类,那么当满足t >= 总文章数 - (已遍历文章数 + i篇有t个引用的文章)时,h=总文章数 - (已遍历文章数 + i篇有t个引用的文章)。具体思路细节参看代码。(效率很低,只beat 5%)
- 其实我们可以简化上面的思路,我们先将输入数组排序,我们就可以知道对于某个引用数,有多少文献的引用数大于这个数。对于引用数citations[i],大于该引用数文献的数量是citations.length - i,而当前的H-Index则是Math.min(citations[i], citations.length - i),我们将这个当前的H指数和全局最大的H指数来比较,就可得到最大H指数。(beat 55%)
上面的第二种思路是将第一种思路进行了简化,思想基本一致 。此外还有省去数组排序而使用其他数据结构的方法,效率会更高,下次复习时再研究。个人感觉上面的第31题(299)和第32题(274)题意都比较绕,比较难理解
33.(187:Medium)(经典题)Repeated DNA Sequences
- 该题还算比较简单,通常的做法是,用一个map来存储已经遍历的字符串,key是已遍历字符串,value是出现次数,在遍历过程中我们会多次存取map以判断该字符串序列是否已出现过,若出现过则加入res集合即可。
- 简化的方法是,我们不用map存储已遍历集合,而是使用set,若当前字符串已出现在set集合,则将其直接加入res结果集中即可,省去了多余的修改map中value值出现次数的操作,大大提高了效率。
34+.(355:Medium)(非常非常经典题)Design Twitter
- 该题应该是常见的FLAG面试题,System Design。
- 我们用两个Map集合存储两种关系,一种是follower-followee关系,另一种是user-tweet关系(这里只是指某一个user发过的消息)。开始的时候尝试使用user-recentTweets关系,虽然getNewsFeed操作在这样的设计下实现非常简单,但unfollow等操作实现非常复杂,即使实现的思路正确,却被OJ判为超时。此外,为了辨别所有的tweets中,哪个tweet是先发的,我们需要设立一个成员变量(全局变量)作为时间戳,每有一个user发布了一个tweet,我们将tweet标记为当前时间戳,并将时间戳加1。在这样的结构设计下,核心难点在于实现getNewsFeed操作。
- getNewsFeed操作需要遍历指定user的所有followee的tweet,并取其中时间戳最大的10个(因为时间戳越大,说明越是最新发布的)。对于时间戳的比较,这里使用了优先队列并自定义了一个比较器,从而实现最小堆,维持堆中元素的数量最大为10个。当堆元素已经有10个时,我们比较当前的tweet时间戳和堆顶(时间戳最小)的tweet,如果当前tweet时间戳大,则加入堆,并删去当前的堆顶tweet,否则说明该followee的所有tweet发布时间都早于当前堆顶的tweet发布时间,直接break,进行下一个followee的遍历。
该题其实设计起来还是有一些复杂的,下次复习时需要再看,beat 21%
35.(138:Medium)(非常非常经典题)Copy List with Random Pointer
- 该题一开始想把它看成一棵树,根据dfs来进行深度拷贝,但是,每个节点的random指针还可能回指到自己的父节点或者祖先节点,因此逻辑非常混乱,递归结束条件不好判断,栈溢出。
- 一种非常直观的方法是,用Map存储链表中的结点,key是原结点,value是根据key的结点建立的新结点。两次遍历链表,第一次沿next指针方向建立标签label值与key节点相等的新节点,第二次同样根据next指针方向,建立value新节点的next和random指向。(beat 49%)
- 如果要求O(1)空间复杂度,我们就不能采取上面的HashMap来进行存储结点,应采取如下的方式,详情参看博客:O(1)空间复杂度实现方法:
如图分三步:
1. 插入拷贝节点
2. 复制random指针
3.分解至两个独立列表
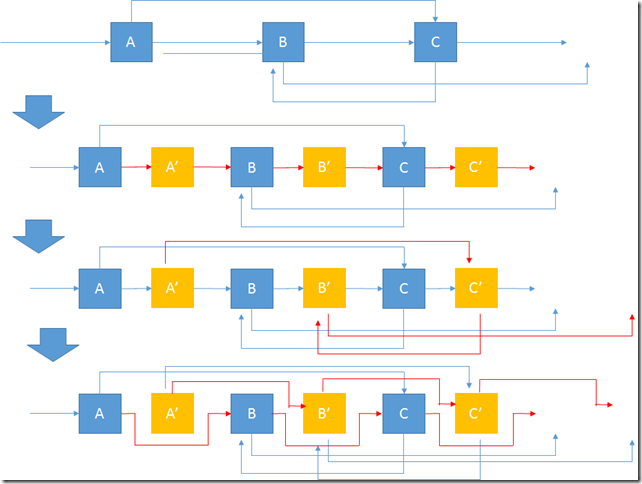
该题还可以简化上述的空间复杂度,可以参看discuss中最高票答案,下次复习时再学习研究
36.(726:Hard)(非常非常经典题)Number of Atoms
- 该题说明了一种处理字符串中括号的方法:对于字符串中"多层括号嵌套"的问题,我们可以使用递归来模拟这样的过程。递归本身就是栈,所以也可以用栈来模拟这样一个递归过程。其实该题算作String类型题。
- 该题设立两个函数getName()和getCount()函数,分别来解析元素名称和元素个数。设立一个全局变量i作为指向字符串当前位置的指针,因此当我们解析完name后,i自然就指向了count的首位置,它是全局同步的。我们在每一层都设立一个map集合,统计当前层及嵌套括号内层的所有元素和个数,然后返回给上一层。当遇到'(',调用递归函数;当遇到')',返回当前层的map集合给上层,上层会进行map集合的merge操作;当未遇到左右括号时,正常getName()、getCount()解析字符即可。
- 参考链接:中文讲解视频
37.(37:Hard)(非常经典题)Sudoku Solver
- 其实该题是在第30题(36)基础上进行了DFS,对每个元素为'.'的位置,尝试填充'1'-'9'数字字符,并判断当前字符是否满足Sudoku条件,若满足则进行更深层次的遍历,否则尝试下一个数字字符。若所有数字字符尝试都失败,则返回false,说明该board就不是一个sudoku。验证某个位置填充某个数字字符后是否满足sudoku条件的函数和第30题(36)中的验证函数思路一样,不过可以参考该题的实现代码,个人认为要更简洁易懂。
- 自我感觉这道题的方法就是暴力破解,因为使用DFS尝试了所有的数字。但却beat 87%,具体实现思路细节看代码及注释。
参考链接:中文视频讲解
38.(734:Easy)Sentence Similarity
- 该题建立一个同义词映射关系的map即可,但需要注意,可能同一个单词会对多个不同的单词是similar pairs,所以map的key是String,value则是set,存储key的所有同义词。
39.(760:Easy)Find Anagram Mappings
- 用一个map存储B中元素出现的位置即可,且可以通过map的数据结构快速判断某单词是否在B中出现过
40.(939:Medium)(经典题)Minimum Area Rectangle
- 该题用一个map存储坐标信息,key是行位置,value是该行的坐标点列位置。然后用两个for循环解决该题,思路是寻找一个矩形的对角坐标,然后进而判断另外两个矩形的顶点是否存在。
41.(340:Hard)(经典题)Longest Substring with At Most K Distinct Characters
- 该题就是典型的滑动窗口的题,我们可以统计窗口内不同字符的出现频率或者不同字符最后一次出现的位置,当窗口包含新的字符时,若此时distinct characters的数量大于K,则将左窗口右移到第一个distinct的右边1个位置,按此思路一直右滑窗口即可。
42.(706:Easy)Design HashMap
- 因为key是int类型,所以能简单的设置一个很长的数组作映射。
43.(953:Easy)(经典题)Verifying an Alien Dictionary
- 通过遍历一遍order字符串,用一个hashmap或一个长度为26的数组来存储每一个字符的优先级。然后两两比较words中的相邻字符串。
- 注意:需要特殊处理这种前缀相同的反序情况,"apple","app",此时应返回false
44.(359:Easy)Logger Rate Limiter
- 该题只需要初始化一个HashMap,使得key是log,value是该log打印的时间。当每次输入一个新的log的时候,查找map中是否之前存在,若不存在则将该log和打印时间输入map;否则判断上一次的打印时间和当前输入时间是否差10,若差10,则更新打印的timestamp为当前时间并返回true,否则返回false,不修改map。
45.(981:Medium)(经典题)Time Based Key-Value Store
- 该题的关键是如何设计数据结构,采取两层TreeMap,利用TreeMap的key值自动排序的性质,调用floorKey方法获得小于给定timestamp的最大prev_timestamp。在第二层的TreeMap中使用timestamp作为key值,是因为传入的string类型value可能会有重复,但timestamp理论上来讲不会出现duplicate.
private Map<String,TreeMap<Integer,String>> map;
/** Initialize your data structure here. */
public TimeMap() {
map = new HashMap<>();
}
public void set(String key, String value, int timestamp) {
if(!map.containsKey(key)) {
map.put(key,new TreeMap<>());
}
map.get(key).put(timestamp,value);
}
public String get(String key, int timestamp) {
TreeMap<Integer,String> treeMap = map.get(key);
if(treeMap==null) {
return "";
}
Integer floor = treeMap.floorKey(timestamp);
if(floor==null) {
return "";
}
return treeMap.get(floor);
}
46.(987:Medium)(经典题)Vertical Order Traversal of a Binary Tree
- 该题是典型的二叉树DFS和HashTable结合的一道题,我们利用TreeMap和PriorityQueue的自动排序特性,根据坐标(x,y),将对应位置的values都整理到一起,最后依次遍历建立res结果集返回即可。
47.(288:Medium)(经典题)Unique Word Abbreviation
- 该题在初始化时,将字符串的key和字符串本身存到一个Map里即可,之后判断是否unique时直接读取。
HashMap<String, String> map;
public ValidWordAbbr(String[] dictionary) {
map = new HashMap<String, String>();
for(String str:dictionary){
String key = getKey(str);
// If there is more than one string belong to the same key
// then the key will be invalid, we set the value to ""
if(map.containsKey(key)){
if(!map.get(key).equals(str)){
map.put(key, "");
}
}
else{
map.put(key, str);
}
}
}
public boolean isUnique(String word) {
return !map.containsKey(getKey(word))||map.get(getKey(word)).equals(word);
}
String getKey(String str){
if(str.length()<=2) return str;
return str.charAt(0)+Integer.toString(str.length()-2)+str.charAt(str.length()-1);
}
48.(957:Medium)(非常经典题)Prison Cells After N Days
- 核心思路就是根据当前的状态计算下一轮变化的状态,对于prison[i],我们只关注是否
prison[i-1]==prison[i+1],并进行相应的状态变化。另外一个需要注意的点是,可能在N次状态循环变化的过程中,状态出现循环,这样的话如果N=7,那么我们应该将其转化成N=N%3=2,这样我们应该找到其循环过程中的第二个状态并返回。
public int[] prisonAfterNDays(int[] cells, int N) {
if(cells==null || cells.length==0 || N<=0) return cells;
boolean hasCycle = false;
int cycle = 0; //判断在状态变换期间是否有循环
HashSet<String> set = new HashSet<>();
for(int i=0;i<N;i++){
int[] next = nextDay(cells);
String key = Arrays.toString(next);
if(!set.contains(key)){ //store cell state
set.add(key);
cycle++;
}
else{ //hit a cycle
hasCycle = true;
break;
}
cells = next;
}
if(hasCycle){ //如果有循环,将N转换成一个循环内的特定状态
N%=cycle;
for(int i=0;i<N;i++){
cells = nextDay(cells);
}
}
return cells;
}
private int[] nextDay(int[] cells){
int[] tmp = new int[cells.length];
//注意我们不特别的改变prison第一个和最后一位置的状态,在进行下一次状态变换时,都将它们设为0
for(int i=1;i<cells.length-1;i++){
tmp[i]=cells[i-1]==cells[i+1]?1:0; //本质上是比较间隔prison的状态
}
return tmp;
}