Análise dos algoritmos - Segmentation-Fault-Machine-Learning/Knowledge GitHub Wiki
Processo de escolha
Para decisão dos algoritmos, foi utilizado o mesmo mapa do scikit-learn utilizado no problema anterior. No contexto deste problema, uma predição de categoria, com dados supervisionados e textuais, chegou-se as seguintes opções: Naive Bayes, Linear SVC e SGDClassifier.
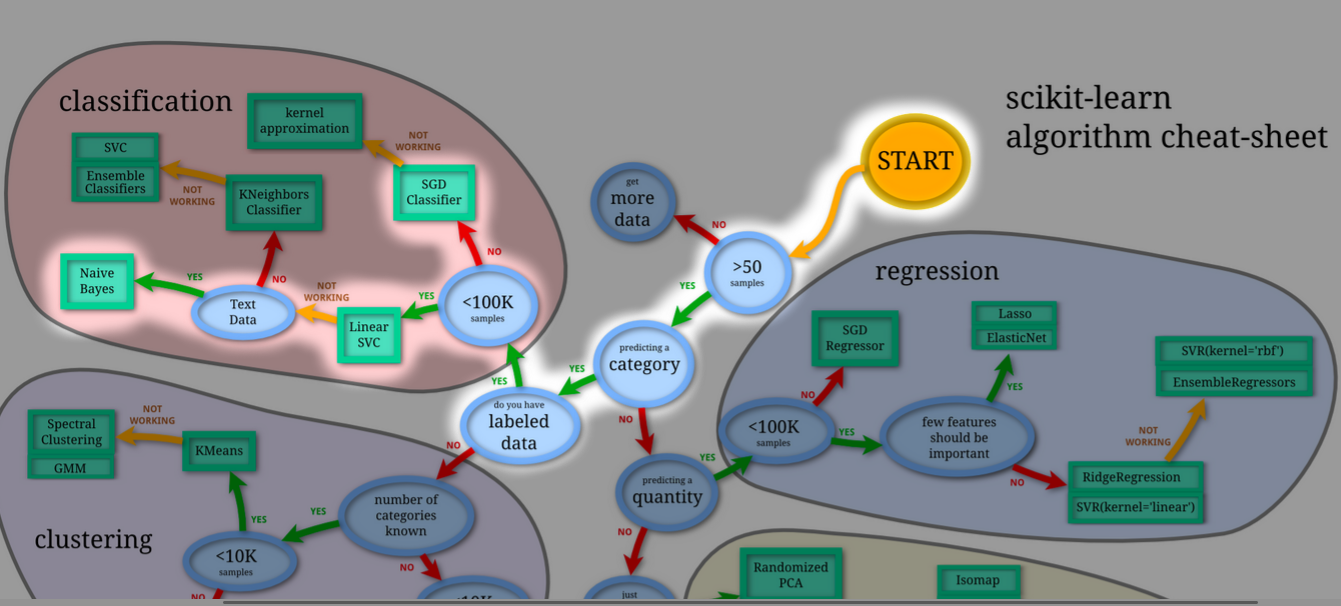
Algumas pesquisas também levaram a análise do algoritmo Passive Agressive. Os algoritmos analisados serão explicados nos tópicos abaixo e comparados no tópico de resultados.
Opções analisadas
Naive Bayes
Introdução
O algoritmo de classificação é baseado no teorema de Bayes com uma suposição de independência entre os preditores. Em termos simples, um classificador Naive Bayes assume que a presença de uma característica particular em uma classe não está relacionada com a presença de qualquer outra. Por exemplo, uma fruta pode ser considerada como uma maçã se é vermelha, redonda, e tiver cerca de 3 polegadas de diâmetro. As propriedades - cor, formato, diâmetro - contribuem de forma independente para a probabilidade de que a fruta seja uma maçã e é por isso que o classificador é conhecido como "Naive"(Ingênuo).
O modelo Naive Bayes é fácil de construir e particularmente útil para grandes conjuntos de dados. Além de simples, Naive Bayes é conhecido por ganhar de métodos de classificação altamente sofisticados.
Multinomial
O modelo multinomial é uma variante do Naive Bayes muito utilizada para classifição de textos. Essa variante é implementada no scikit-learn e usada para dados distribuidos de forma multinomial. A variante multinomial pode ser usada com contagem de palavras ou com tf-idf.
O modelo multinomial considera a propabilidade de uma classe como 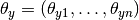 , onde a probabilidade
, onde a probabilidade 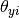 é dada por:
é dada por:
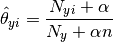
Onde Nyi é o número de vezes que a feature aparece na classe y e Ny é o numero total de features. O algoritmo polinomial foi escolhido devido a sua capacidade de utilizar mais de uma feature. No contexto, cada feature representa uma termo encontrado em um documento.
SGD Classifier
O SGD Classifier é um implementação do sklearn de um modelo de aprendizagem linear que aproxima os dados a funções lineares.
Esse módulo é utilizado para regularização de dados dando suporte a regularizações com penalidade, como por exemplo l1, l2 e elasticnet.
l1 e elasticnet: oferece de 'penalidade' à features l2: padrão do modelo sklearn, é o regulador padrão para modelos SVMs Com este módulo podemos regularizar dados aproximando-os a uma função linear de forma prática, porém, em muitos casos essa aproximação não é muito efetiva.
Bibliografia
[1] SGD - link
Passive Agressive
O algoritmo PA (Passive-Agressive) é algoritmo para aprendizados de larga escala, onde não é necessária uma taxa de aprendizado(na verdade, ele usa a perda como taxa de aprendizado), visto que ele itera sobre as predições e, a partir delas, analisa o modelo construído e, se necessário, muda para adaptar a predição incorreta.
A forma com que esse algoritmo opera é simples, ele cria um vetor, que tem como intuito separar as amostras de dados, e este vetor possui uma "zona", usada para balizar a posição que o vetor deve ser posicionado, de valor 2, sendo representada pelos valores -1, 0, 1, de forma que as predições devem ser posicionadas em um desses lados. Ao realizar uma nova predição, o algoritmo analise o valor da perdição em relação a origem e o valor que ela deveria receber, e a partir dai, se ela negativa, o modelo é alterado, e se ela for positiva, o modelo permanece o mesmo.
A formula usada para alterar o modelo pode ser representada por:
nova dTw = dT(w + yLd)
= dTw + yLdTd
= dTw + yL = y
sendo w como o vetor usado até agora para realizar as predições, L sendo o quão perto a perdição incorreta ficou da zona em que deveria estar, e y o quando o novo vetor deve ser movido. Então a partir deste cálculo, podemos perceber que o algoritmo PA move somente o necessário para o modelo a nova predição e torna-la correta.