Array - Seaven/incubator-doris GitHub Wiki
Clickhouse支持的复合数据类型:
- array
- tuple(tuple只能在临时表中使用)
- 嵌套数据类型Nested
ClickHouse会自动检测数组元素,并根据元素计算出存储这些元素最小的数据类型。如果在元素中存在 NULL 或存在 Nullable 类型元素,那么数组的元素类型将会变成 Nullable。
Block 是表示内存中表的子集(chunk)的容器,是由三元组:(IColumn, IDataType, 列名) 构成的集合。在查询执行期间,数据是按 Block 进行处理的。如果我们有一个 Block,那么就有了数据(在 IColumn 对象中),有了数据的类型信息告诉我们如何处理该列,同时也有了列名(来自表的原始列名,或人为指定的用于临时计算结果的名字)。
ColumnArray的数据结构:
class ColumnArray {
private:
// wrappedPtr是一个copy on write的指针
WrappedPtr data;
// offset记录了每行数据在data中的偏移
WrappedPtr offsets;
}
ColumnArray中没有指定数组元素的类型,类型在Block中其他数据结构指明,在访问ColumnArray数据时,传入的行号需要先通过offset确定偏移,再计算取出数据。
Array<T>, T可以是任意类型,包含数组类型,在MergeTree的存储中,Array列实际上还是一个包装类型,实际存储的序列化操作依赖具体类型T
Clickhouse将所有的IO/网络输入输出流都包装成BlockStreamIO,对数据的保存和读取都是通过BlockStreamIO处理,一个Block中包括了(IColumn, IDataType, column name),IColumn用于描述具体数据,IDataType用于数据类型的序列化/反序列化。
Array中存储的数据包括两列:ArraySizes(Array长度,int),ArrayElements(连续的所有元素),相应的Array写入时,BlockStreamIO会分为两个,一个用于写入ArraySizes,一个用于写入ArrayElements。
Clickhouse可以支持多维嵌套的Array,比如二维的array,构成结构:
- array sizes; (sizes of top level arrays)
- array elements / array sizes; (sizes of second level (nested) arrays)
- array elements / array elements; (the most deep elements, placed contiguously)
但是没有在MergeTree引擎中实现,需要重写datatype的serialize/deserialize方法实现
Array列的写入流程:
- 根据column setting创建column写入流,由于array的数据流分为两类(sizes/element),因此会相应创建出两个列存储数据
- 序列化Array sizes & 写入sizes substream
- 调用T类型的序列化方式写入elements substream
读取流程:
- 读取ColumnArray时,需要叠加写入的Array size,计算出array的offset
- 通过offset和size,读取Array
- 调用T类型的反序列化方式读取数据
- 从Clickhouse的代码上看,写入array size列时,只写入了size,并没有对应行的offset,此处有offset效率是否会更高?
API上有Array push、append、pop等修改操作,MergeTree引擎的update数据操作(ALTER TABLE)会重写相关的整个data parts(代价相当大),不确定是否可以用与修改array、nest数据
- Clickhouse的文档上看,string类型(相当于不限长度的varchar,且没有编码)实现和Array类似
Clickhouse对array数据查询直接以[x1, x2, ...]数组形式显示。对于Array列join,可以使用ARRAY JOIN子句(本质上等同于INNERT JOIN)完成,查询结果会按照array子元素打平成多行结果数据。
// DDL
CREATE TABLE arrays_test (s String, arr Array(UInt8)) ENGINE = Memory
// QUERY:
SELECT * FROM arrays_test
// RESULT:
┌────s────┬───arr───┐
│ Hello │ [1,2] │
│ World │ [3,4,5] │
│ Goodbye │ [] │
└─────────┴─────────┘
// ARRAY JOIN子句
SELECT s, arr, a FROM arrays_test ARRAY JOIN arr AS a
// RESULT:
┌───s───┬───arr───┬─a─┐
│ Hello │ [1,2] │ 1 │
│ Hello │ [1,2] │ 2 │
│ World │ [3,4,5] │ 3 │
│ World │ [3,4,5] │ 4 │
│ World │ [3,4,5] │ 5 │
└───────┴─────────┴───┘
注意: group by子句,DISTINCT不支持Array列
https://clickhouse.yandex/docs/zh/data_types/array/
Array相关code:
// 序列化相关
dbms/src/DataTypes/DataTypeArray.cpp : 199
dbms/src/DataTypes/IDataType.h : 59
// 存储
dbms/src/Storages/MergeTree/IMergedBlockOutputStream.cpp : 82
// 数据结构
dbms/src/Columns/ColumnArray.cpp
Presto提供了一个数据存储的抽象层,实际的存储还是由底层的hive/Hbase...完成
存储单元:
- Page: 多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储,一个Page最大1MB,最多16*1024行数据。
- Block:一列数据,根据不同类型的数据,通常采取不同的编码方式,每个Block对象是一个字节数组,存储一个字段的若干行。多个Block横切的一行是真实的一行数据。
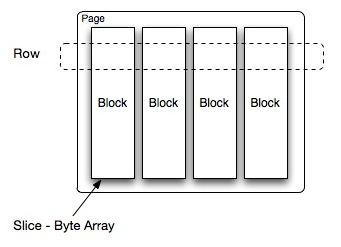
Presto支持三种结构化的数据类型:
- ARRAY:要求元素类型必须一致
- MAP:要求所有key的类型一致,所有的的Value类型一致(通过指定两个有序的array创建)
- ROW:表示为一行数据,元素类型可以不一致
AbstractArrayBlock是Presto中array存储单元的抽象结构,具体实现以ArrayBlock为例:
public class ArrayBlock
extends AbstractArrayBlock
{
//...
private final int arrayOffset;
// Array元素个数
private final int positionCount;
// bitmap,标识是否为空元素
private final boolean[] valueIsNull;
// Array元素数据(可以指向IntArrayBlock, BlockByteArrayBlock等,实际核心是一个数组)
private final Block values;
// 每个Array数组的偏移
private final int[] offsets;
// 数据大小
private volatile long sizeInBytes;
// Block实例大小
private final long retainedSizeInBytes;
// .....
}
ArrayBlock中的values字段指向的数据,以IntArrayBlock为例,其组成字段:
public class IntArrayBlock
implements Block
{
// 用于key去重
private final int arrayOffset;
private final int positionCount;
private final boolean[] valueIsNull;
// 实际存储数据值
private final int[] values;
private final long sizeInBytes;
private final long retainedSizeInBytes;
}
MapBlock, RowBlock与ArrayBlock最大的区别在于values的类型上,其他字段大同小异
RowBlock的values定义为:
private final Block[] values;
由于Row中元素类型不同,因此是一个Block类型的数组,可以指向IntBlock, LongBlock等多个类型
而MapBlock中的字段为:
private final Block keyBlock;
private final Block valueBlock;
// 用于key去重
private HashTables hashTables;
分别记录keyBlock和valueBlock,两者指向的类型和ArrayBlock中的values一样(IntArrayBlock, ByteArrayBlock......,这也是Key/Value只能是一种类型的原因),
此外,Presto提供了connector接口,用于接入到实际的存储系统中。对接Hive的connector实现了三种:Parquet connector, ORC connector, RCFile connector。
以ORC connector为例,在写入ORC file时,会将Array结构拆分为两部分数据写:一部分为Array结构的长度,一部分为具体元素数据,具体序列化方式通过具体类型实现。在实际落地为ORC file时,同样分为两列数据写。
Array的检索上Presto与Clickhouse相似,查询array列以数组形式展现,提供UNNEST函数,用于嵌套类型数据打平。UNNSET使用多个参数时,会将参数列都扩展为与对多元素的参数列一样多的行,元素个数不足的用空值补充。
// QUERY
SELECT numbers, animals, n, a
FROM (
VALUES
(ARRAY[2, 5], ARRAY['dog', 'cat', 'bird']),
(ARRAY[7, 8, 9], ARRAY['cow', 'pig'])
) AS x (numbers, animals)
CROSS JOIN UNNEST(numbers, animals) AS t (n, a);
// RESULT
numbers | animals | n | a
-----------+------------------+------+------
[2, 5] | [dog, cat, bird] | 2 | dog
[2, 5] | [dog, cat, bird] | 5 | cat
[2, 5] | [dog, cat, bird] | NULL | bird
[7, 8, 9] | [cow, pig] | 7 | cow
[7, 8, 9] | [cow, pig] | 8 | pig
[7, 8, 9] | [cow, pig] | 9 | NULL
(6 rows)
https://prestodb.io/docs/current/develop/types.html https://zhuanlan.zhihu.com/p/60813087 https://prestodb.io/docs/current/sql/select.html
相关code:
// https://github.com/prestodb/presto
// presto-spi:
// 内存中抽象数据类型
MapType.java
RowType.java
ArrayType.java
// block数据类型
ArrayBlock.java
IntArrayBlock.java
ByteArrayBlock.java
RowBlock.java
MapBlock.java
// presto-orc:
ORCWrite.java
ListColumnWriter.java
Druid的数据模型包括:时间戳,维度列,指标列,其中维度列支持 arrays of Strings。
Druid的解析维度列通过DimensionSpec指定解析方式。
数据结构和存储Druid没有仔细看,这里以Druid多值列的查询为主 这里是按照理解,将Druid的文档中的query转换为对应的SQL,可能会有不对的地方,原文已经附在来源上了
// data
{"timestamp": "2011-01-12T00:00:00.000Z", "tags": ["t1","t2","t3"]} #row1
{"timestamp": "2011-01-13T00:00:00.000Z", "tags": ["t3","t4","t5"]} #row2
{"timestamp": "2011-01-14T00:00:00.000Z", "tags": ["t5","t6","t7"]} #row3
{"timestamp": "2011-01-14T00:00:00.000Z", "tags": []} #row4
条件过滤规则:
- 值过滤器(select选择器(=),boud子句(or),in子句)匹配粒度为array中的元素
- The Column Comparison filter will match a row if the dimensions have any overlap.
- 空值过滤器(null or "")将匹配空元素的行
- 逻辑表达式过滤器的行为和在单值列上相同,and需要行满足所有的条件,or需要满足任一条件,not这是任何条件都不满足
example:
// Q: or子句,匹配row1, row2
select * from table where tags = t1 or tags = t3;
// Q: and子句,匹配row1
select * from table where tags = t1 and tags = t3
// Q: = 子句, 匹配row4
select * from table where tags = null
Group规则: 多值列可以支持topN和groupBy查询。在多值列上group时,会将array打平成多行,相当于在Array上使用了UNNSET函数。
// Case 1. group by without filter
select count(1), tags from table group by tags
// RETURN
┌─count(1)─┬─tags─┐
│ 1 │ t1 │
│ 1 │ t2 │
│ 2 │ t3 │
│ 1 │ t4 │
│ 2 │ t5 │
│ 1 │ t6 │
│ 1 │ t7 │
└──────────┴──────┘
// Case 2. group by with filter on multi-value
// 虽然指定了tags = t3, 但是可以看到查询的结果包含了t1,t2,t4,t5, 是因为在where
// 子句在group by之前执行
select count(1), tags from table where tags = t3 group by tags
// RETURN
┌─count(1)─┬─tags─┐
│ 1 │ t1 │
│ 1 │ t2 │
│ 2 │ t3 │
│ 1 │ t4 │
│ 1 │ t5 │
└──────────┴──────┘
// Case 3. group by with filter
// 对于Case 2的问题,druid是使用了filtered dimension spec去做结果过滤达到目的,
// 映射在SQL中类似在where子句中执行一个list_filter的算子,以多值列的元素而不是
// 整个多值列值做计算
select count(1), tags from table where list_filter(tags, 3) group by tags
// RETURN
┌─count(1)─┬─tags─┐
│ 2 │ t3 │
└──────────┴──────┘
https://github.com/apache/druid/issues/7525 https://druid.apache.org/docs/latest/querying/multi-value-dimensions.html
Impala支持Array,Struct,Map,而且支持嵌套类型。
Array的存储分为Item和POS两列数据,可以通过SQL查看:
DESCRIBE array_demo;
+--------------+---------------------------+
| name | type |
+--------------+---------------------------+
| id | bigint |
| name | string |
| pets | array<string> |
| marriages | array<struct< |
| | spouse:string, |
| | children:array<string> |
| | >> |
| places_lived | array<struct< |
| | place:string, |
| | start_year:int |
| | >> |
| ancestors | map<string,array<string>> |
+--------------+---------------------------+
DESCRIBE array_demo.pets;
+------+--------+
| name | type |
+------+--------+
| item | string |
| pos | bigint |
+------+--------+
DESCRIBE array_demo.marriages;
+------+--------------------------+
| name | type |
+------+--------------------------+
| item | struct< |
| | spouse:string, |
| | children:array<string> |
| | > |
| pos | bigint |
+------+--------------------------+
- 多值列不能作为分区表中的分区列
- ORDER BY,GROUP BY,HAVING或WHERE子句无法直接使用多值列/列名,必须引用多值列的元素名,例如ITEM,POS,KEY或VALUE伪列,或STRUCT中的元素字段名。
- 最深嵌套层级为100层
- 最多存储4000字符
- Impala的内置函数和UDF不支持传入嵌套数据
- 不支持使用Create Table As Select/Insert....Select这样的语句直接插入多值列
与Clickhouse不同,Impala查询Array时,似乎会将多值列自动打平成多行数据,例如:
// DDL
CREATE TABLE complex_array (country STRING, city ARRAY <STRING>) STORED AS PARQUET;
// QUERY
SELECT country, city.item FROM complex_array, complex_array.city;
// RESULT
+---------+-------------+
| country | item |
+---------+-------------+
| Canada | Toronto |
| Canada | Vancouver |
| Canada | St. John's |
| Canada | Saint John |
| Canada | Montreal |
| Canada | Halifax |
| Canada | Winnipeg |
| Canada | Calgary |
| Canada | Saskatoon |
| Canada | Ottawa |
| Canada | Yellowknife |
| France | Paris |
| France | Nice |
| France | Marseilles |
| France | Cannes |
| Greece | Athens |
| Greece | Piraeus |
| Greece | Hania |
| Greece | Heraklion |
| Greece | Rethymnon |
| Greece | Fira |
+---------+-------------+
来源: http://impala.apache.org/docs/build/html/topics/impala_array.html http://impala.apache.org/docs/build/html/topics/impala_complex_types.html#item http://impala.apache.org/docs/build/html/topics/impala_complex_types.html#complex_sample_schema
当前Doris上有不少ArrayType的定义,但是都比较少,缺少的功能点:
SQL相关:
- 相关SQL语法(select,create table,in,like,join),访问API(下标?ArrayElements?)
- 嵌套类型支持嵌套层级?
执行规划相关:
- Array是否支持聚合函数(MAX,MIN,COUNT....)
- Impala对Array的实现导致Array和ScalarType类型区别很大
计算相关:
- 相关执行算子
存储相关: Array的存储实现可以参考Doris的varchar:存储一列offset和数据列。
- Array类型数据存储(序列化,反序列化的encoding_page_builder支持嵌套类型)
- 对于bitmapindex,是需要使用Array的元素建立?还是使用整体的Array数组建立?
- BloomFilter,meta按照Array粒度写入?还是使用元素建立?
导入相关:
- 导入格式(解析,序列化)
相关code:
// Segment V1
cloumn_writer.h
cloum_reader.h
// Segment V2
segment_v2/encoding_info.cpp