Chapter 03 CUDA execution model - SaoYan/Learning_CUDA GitHub Wiki
- 1. GPU hardware architecture overview
- 2. Profile-driven optimization
- 3. Understanding warp execution
- 4. Avoiding branch divergence
- 5. Unrolling loops
- 6. Dynamic parallelism
- 7 Notes of exercises
How to maximize the performance?
- Avoid warp divergence (refer to 3.2 warp divergence, 4. Avoiding branch divergence)
- Note The size of the innermost dimension of a thread block (ie. blockDim.x) plays a key role in performance. For example, block(256,1) will outperform block(1,256), because the in the former configuration the innermost dimension is a multiple of 32.
- Striking a balance between latency hiding and resource utilization
- Maximize the number of active warps to hide latency (refer to 3.4 Latency hiding)
- (and at the same time) Should be aware of the limitation of conpute resources. (refer to 3.3 Resource partitioning)
- Choose proper grid and block dimension

- Unrolling loops to expose more parallelism (refer to 5. Unrolling loops)
Some advanced features of GPU for better performance (refer to 1 GPU hardware architecture overview)
- Concurrent kernel execution
- Dynamic parallelism
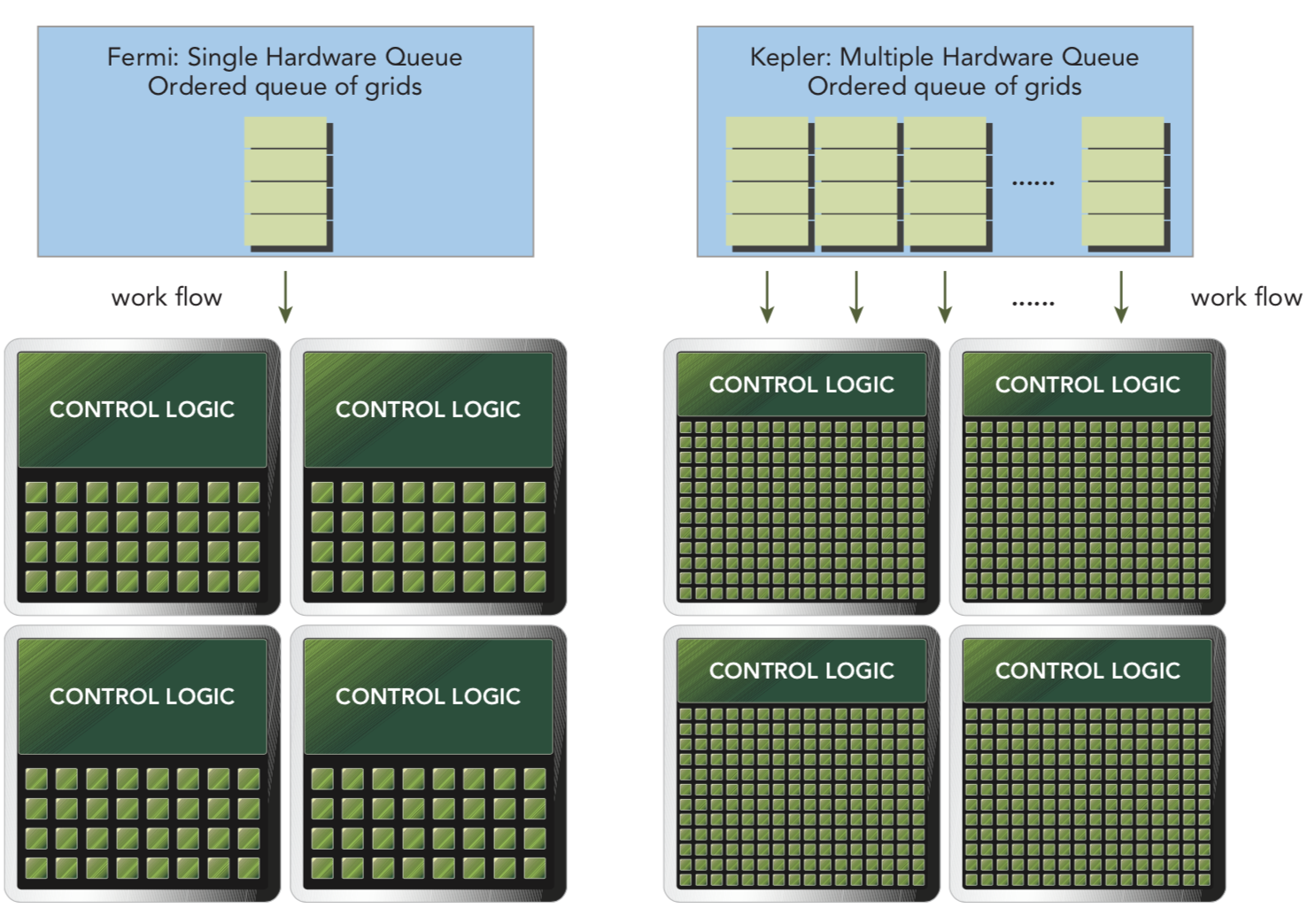
- Hyper-Q
- GPU performance attributes
There are two important features that describe GPU capability:
- Number of CUDA cores
- Memory size
There are two different metrics for describing GPU performance:
- Peak computational performance: measuring computational capability; defined as how many single-precision or double-precision floating point calculations can be processed per second; usually expressed in gflops (billion floating-point operations per second) or tflops (trillion floating-point calculations per second).
- Memory bandwidth: the ratio at which data can be read from or stored to memory; usually expressed in GB/s (gigabytes per second).
- From logic view to hardware view:
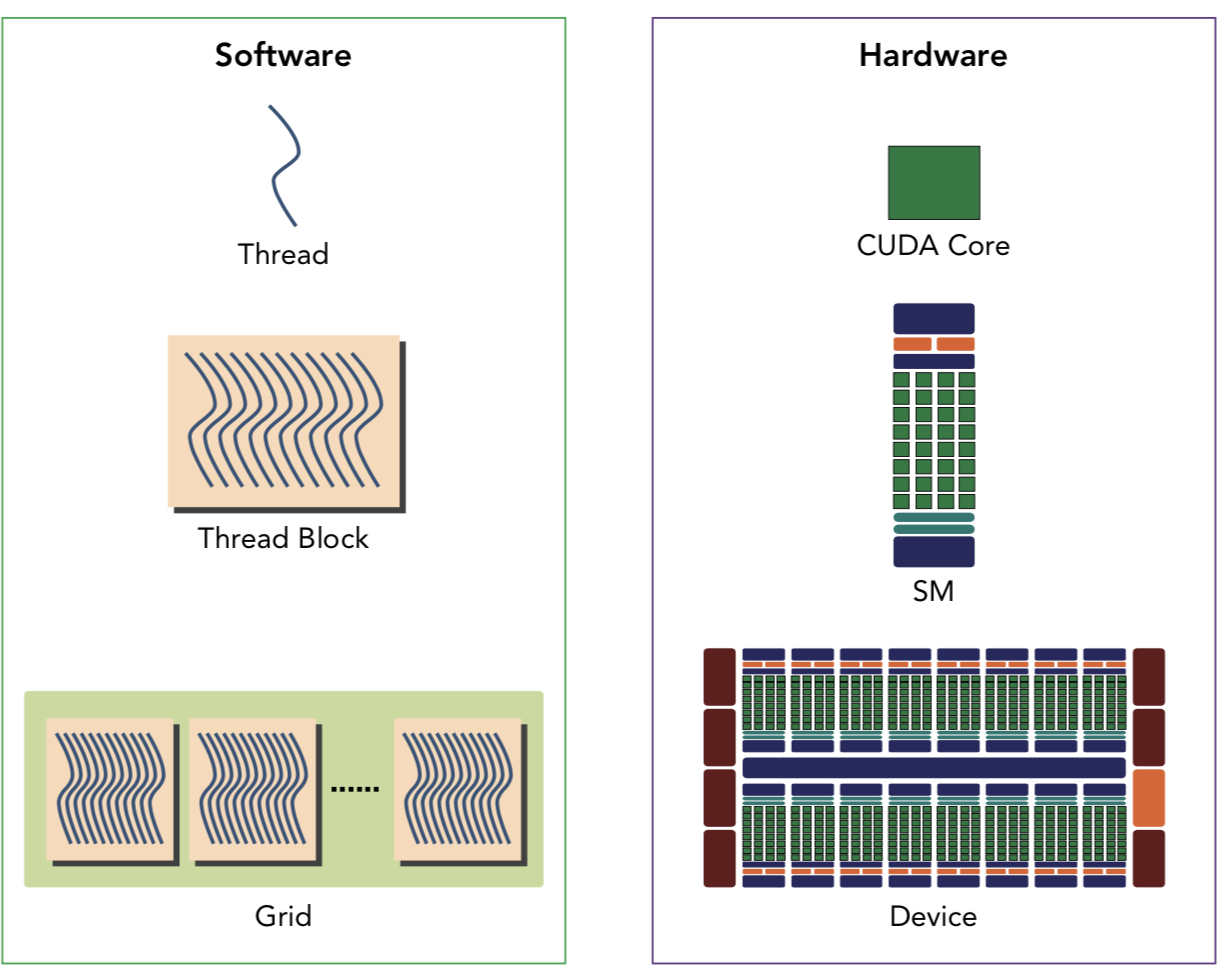
- Streaming Multiprocessor (SM): architectural building block of GPU
- One GPU can have multiple SMs.
- When a kernel grid is launched, the thread blocks of that kernel grid are distributed among available SMs for execution.
- A thread block is scheduled on only one SM; an SM can hold more than one thread block at the same time.
- Shared memory and registers are resources in each SM. Shared memory is partitioned among thread blocks resident on the SM and registers are partitioned among threads.
- While all threads in a thread block run logically in parallel, not all threads can execute physically at the same time (because the number of active warps is limited by SM resources).
- Single Instruction Multiple Thread (SIMT)
- Threads are executed in groups of 32 called warps. All threads in a warp execute the same instruction at the same time.
- Optimizing your workloads to fit within the boundaries of a warp (group of 32 threads) will generally lead to more efficient utilization of GPU compute resources.
- SIMT vs. SIMD (Single Instruction, Multiple Data)
- Same: broadcasting the same instruction to multiple execution units.
- Different: SIMD requires that all vector elements in a vector execute together in a unified synchronous group, whereas SIMT allows multiple threads in the same warp to execute independently.
-
Concurrent kernel execution: multiple kernels launched from the same application context executing on the same GPU as the same time; allows programs that execute a number of small kernels to fully utilize the GPU.

-
Dynamic parallelism
On GPUs that support this feature, any kernel can launch another kernel and manage any inter-kernel dependencies needed to correctly perform additional work. This feature makes it easier to create and optimize recursive and data-dependent execution patterns.

-
Hyper-Q Hyper-Q adds more simultaneous hardware connections between the CPU and GPU, enabling CPU cores to simultaneously run more tasks on the GPU.
Official document for CUDA profile
-
Developing an HPC application usually involves two major steps: developing the code for correctness; improving the code for performance. It is natural to use a profile-driven approach for the second step.
-
Profiling is the act of analyzing program performance by measuring:
- The space (memory) or time complexity of application code
- The use of particular instructions
- The frequency and duration of function calls
-
Terms

To identify the performance bottleneck of a kernel, it is important to choose appropriate performance metrics and compare measured performance to theoretical peak performance.
(More details about the usage of profile tools need to be added for this section...)
- nvvp - a standalone visual profiler
- displaying a timeline of program activity on both the CPU and GPU, helping you to identify opportunities for performance improvement
- analyzing your application for potential performance bottlenecks and suggests actions to take to eliminate or reduce those bottlenecks
- nvprof - a command line profiler
- collecting a timeline of CUDA-related activities on both the CPU and GPU, including kernel exe- cution, memory transfers, and CUDA API calls
- collecting hardware counters and performance metrics for CUDA kernels
- NVIDIA Nsight Compute & NVIDIA Nsight Systems
Visual Profiler and nvprof will be deprecated in a future CUDA release. It is recommended to use next-generation tools NVIDIA Nsight Compute for GPU profiling and NVIDIA Nsight Systems for GPU and CPU sampling and tracing.
Warps are the basic unit of execution in an SM. When you launch a grid of thread blocks, the thread blocks in the grid are distributed among SMs. Once a thread block is scheduled to an SM, threads in the thread block are further partitioned into warps. A warp consists of 32 consecutive threads and all threads in a warp are executed in Single Instruction Multiple Thread (SIMT) fashion; that is, all threads execute the same instruction, and each thread carries out that operation on its own private data.

Thread blocks can be configured to be one-, two-, or three-dimensional. However, from the hardware perspective, all threads are arranged one-dimensionally. Each thread has a unique ID in a block. (computing global thread index)
A warp is never splited between different thread blocks. If thread block size is not an even multiple of warp size, some threads in the last warp are left inactive, but they still consume SM resources, such as registers.
For example: a two-dimensional thread block with 40 threads in the x dimension and 2 threads in the y dimension

- Introduction
Consider the following statement within a kernel:
if (cond) {
...
}
else {
...
}
Suppose for 16 threads in a warp executing this code, cond is true, but for the other 16 cond is false. Then half of the warp will need to execute the instructions in the if block, and the other half will need to execute the instructions in the else block. This is called "warp divergence"
Warp divergence: threads in the same warp executing different instructions.
- Warp divergence can cause significantly degraded performance!
- Different conditional values in different warps do not cause warp divergence.
Q: What if we must need conditional statement within a kernel?
A: Since warp assignment of threads in a thread block is deterministic, it may be possible (though not trivial, depending on the algorithm) to partition data in such a way as to ensure all threads in the same warp take the same control path in an application.
- Case study
Case 1: The following code is a poor partitioning of data with an even and odd threads approach, causing warp divergence.
__global__ void myKernel(float *c) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0f, b = 0.0f;
if (idx % 2 == 0) a = 100.0f;
else b = 200.0f;
c[idx] = a + b;
}
Case 2: interleaving data using a warp approach (instead of a thread approach). The condition (tid/warpSize)%2==0 forces the branch granularity to be a multiple of warp size; the even warps take the if clause, and the odd warps take the else clause.
__global__ void myKernel(float *c) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0f, b = 0.0f;
if ((idx / wrapSize) % 2 == 0) a = 100.0f;
else b = 200.0f;
c[idx] = a + b;
}
- Overserve warp divergence using profile
We can observe warp divergence by using the nvprof profiler to collect metrics from the GPU
Branch Efficiency: the ratio of NON-divergent branches to total branches
nvprof --metrics branch_efficiency ./simpleDivergence
We can also obtain the event counters for branch and divergent branch:
nvprof --events branch,divergent_branch ./simpleDivergence
- nvcc compiler can automatically optimize branch divergence for short conditional code segments ("short" means the number of instructions in the body of conditional statement is less than a certain threshold).
We can force nvcc to not optimize the kernel:
nvcc -g -G simpleDivergence.cu -o simpleDivergence
- registers: partitioned through threads
- shared memory: partitioned through blocks
- If there are insufficient registers or shared memory on each SM to process at least one block, the kernel launch will fail.


Summary: Resource availability generally limits the number of resident thread blocks per SM, so we must be aware of the restrictions imposed by the hardware, and the resources used by your kernel.
Some of the key limits:

- Basis
- instruction latency: the number of clock cycles between an instruction being issued and being completed
- There are two types of instructions we need to consider: arithmetic instruction and memory instruction. The corresponding latencies for each case are approximately: 10-20 cycles for arithmetic operations; 400-800 cycles for global memory accesses.
- bandwidth and throughput: They are all rate metrics; bandwith is usually used to refer to a theoretical peak value, while throughput is used to refer to an achieved value.
- Apply Little’s Law to estimate the required parallelism in order to hide latency: Number of Parallelism = Latency × Throughput
Full compute resource utilization is achieved when all warp schedulers have an eligible warp at every clock cycle. This ensures that the latency of each instruction can be hidden by issuing other instructions in other resident warps.

- Estimate required number of active warps - arithmetic instruction
Example: given the following device properties:

Take Fermi for example:
- Required parallelism: 20 (latency) * 32 (throughput) = 640 (operations)
- One warp executing one instruction corresponds to 32 operations
- The required number of warps per SM to maintain full compute resource utilization: 640 (operations) / 32 (operations/warp) = 20 (warps)
How to increase parallelism (hide latency):
- Instruction-level parallelism (ILP): more independent instructions within a thread
- Thread-level parallelism (TLP): more concurrently eligible threads
- Estimate required number of active warps - memory instruction
Example: given the following device properties:

Take Fermi for example:
- Check the device's memory frequency:
nvidia-smi -a -q -d CLOCK | fgrep -A 3 "Max Clocks" | fgrep "Memory"
- Convert the throughput into gigabytes per cycle: 144 (GB/Sec) / 1.566 (GHz) ~ 92 (Bytes/Cycle)
- Required parallelism: 800 * 92 = 73600 (bytes) ~ 74 (kb) (Note: This value is for the entire device, not per SM, because memory bandwidth is given for the entire device.)
- Connecting these values to warp or thread counts depends on the application. Suppose each thread moves one float of data (4 bytes):
- Required active threads: 74kb / 4 ~ 18500 threads
- Required active warps: 18500 threads / 32 (threads/warp) ~ 579 warps
- The Fermi architecture has 16 SMs --> requiring 579 / 16 ~ 36 warps per SM
How to increase parallelism (hide latency):
- creating more independent memory operations within each thread/warp
- creating more concurrently active threads/warps
- Occupancy
Occupancy = active warps (per SM) / maximum warps (per SM)
- Code sample to get some device infomation (including maximum warps per SM)
int main(int argc, char *argv[]) {
int iDev = 0;
cudaDeviceProp iProp;
CHECK(cudaGetDeviceProperties(&iProp, iDev));
printf("Device %d: %s\n", iDev, iProp.name);
printf(" Number of multiprocessors: %d\n",
iProp.multiProcessorCount);
printf(" Total amount of constant memory: %4.2f KB\n",
iProp.totalConstMem / 1024.0);
printf(" Total amount of shared memory per block: %4.2f KB\n",
iProp.sharedMemPerBlock / 1024.0);
printf(" Total number of registers available per block: %d\n",
iProp.regsPerBlock);
printf(" Warp size: %d\n",
iProp.warpSize);
printf(" Maximum number of threads per block: %d\n",
iProp.maxThreadsPerBlock);
printf(" Maximum number of threads per multiprocessor: %d\n",
iProp.maxThreadsPerMultiProcessor);
printf(" Maximum number of warps per multiprocessor: %d\n",
iProp.maxThreadsPerMultiProcessor / 32);
return EXIT_SUCCESS;
}
- Nvidia provides a tool called CUDA Occupancy Calculator to help us select grid and block dimensions to maximize occupancy for a kernel. Read the instructions in the spreadsheet. Also, here are more infomation you'll find useful:
- The registers per thread and shared memory per block resource usage can be obtained from nvcc with the compiler flag: --ptxas-options=-v
- The number of registers used by a kernel can have a significant impact on the number of resident warps. Register usage can be manually controlled using the nvcc flag: –maxrregcount=NUM. This tells the compiler to not use more than NUM registers per thread. You can use the number of registers recommended by the Occupancy Calculator in conjunction with this compiler flag to potentially improve the performance of your application.
- System-level synchronization: Wait for all work on both the host and the device to complete.
Many CUDA API calls and all kernel launches are asynchronous with respect to the host. We can use cudaDeviceSynchronize to block the host application until all CUDA operations (copies, kernels, and so on) have completed.
- Block-level synchronization: Wait for all threads in a thread block to reach the same point in execution on the device.
Because warps in a thread block are executed in an undefined order, CUDA provides the ability to synchronize their execution with a block-local barrier. You can mark synchronization points in the kernel using __device__ void __syncthreads(void);
- When __syncthreads is called, each thread in the same thread block must wait until all other threads in that thread block have reached this synchronization point.
- All global and shared memory accesses made by all threads prior to this barrier will be visible to all other threads in the thread block after the barrier.
- __syncthreads is used to coordinate communication between threads in the same block, but it can negatively affect performance by forcing warps to become idle.
- There is no thread synchronization among different blocks.
- Race conditions (hazards): unordered accesses by multiple threads to the same memory location
For example: read-after-write hazard occurs when an unordered read of a location occurs following a write. Because there is no ordering between the read and the write, it is undefined if the read should have loaded the value of that location before the write or after the write. If thread A tries to read data that is written by thread B in a different warp, you can only be sure that thread B has finished writing if proper synchronization is used.
More details about synchronization issues are in Chapter 4.
- Scalability
Scalability: providing additional hardware resources to a parallel application yields speedup relative to the amount of added resources
Transparent scalability: the ability to execute the same application code on a varying number of compute cores
Scalability depends on algorithm design and hardware features. Considering GPU devices:
When a CUDA kernel is launched, thread blocks are distributed among multiple SMs. Thread blocks in a grid can be executed in any order, in parallel or in series. This independence makes CUDA programs scalable across an arbitrary number of compute cores.

- Check metrics of kernel: nvprof --metrics xxx. See all metric reference here.. Eg.
- achieved_occupancy: the average active warps per cycle / the maximum number of warps supported on an SM
- gld_throughput: global memory load throughput
- gld_efficiency: global load efficiency; requested global load throughput / required global load throughput. It measures how well the application’s load operations use device memory bandwidth (if the throughput is high but the efficiency is low, the performance will still not be good).
- The size of the innermost dimension of a thread block (ie. blockDim.x) plays a key role in performance. For example, block(256,1) will outperform block(1,256), because the in the former configuration the innermost dimension is a multiple of 32.

In this section we examine a case: the parallel reduction problem.
reduction problem: performing a commutative and associative operation across a vector
when the operation is addition:
int sum = 0;
for (int i = 0; i < N; i++)
sum += array[i];
In the following discussion, suppose addition operation.
How to implement this in parallel?
- iterative pairwise implementation: A chunk contains only a pair of elements, and a thread sums those two elements to produce one partial result. These partial results are then stored in-place in the original input vector. These new values are used as the input to be summed in the next iteration.
- tow different types of pairwise implementation: neighbored pair (left figure); interleaved pair (right figure, where the stride is half of the length of the input at each step)

Implementing neighbored pair approach:
- Use two global memory arrays: one large array for storing the entire array to reduce, and one smaller array for holding the partial sums of each thread block.
- The reduction is done in-place, which means that the values in global memory are replaced by partial sums at each step.
- __syncthreads ensures that all partial sums for every thread in the current iteration have been saved to global memory before any threads in the same thread block enter the next iteration.
- Because there is no synchronization between thread blocks, the partial sum produced by each thread block is copied back to the host and summed sequentially there.


__global__ void reduceNeighbored(int *g_idata, int * g_odata, const int n) {
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= n) return;
const int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2) {
if (tid % (stride * 2) == 0) {
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
What's wrong with the above implementation?
if (tid % (stride * 2) == 0) causes thread divergence (left figure). In the first iteration, 1/2 of the threads are active; in the second iteration, 1/4 of the threads are active; ...
Modification: (right figure) forcing the usage of neighborhood threads; the store location of partial sums has not changed, but the working threads are updated.

__global__ void reduceNeighboredLessDiv(int *g_idata, int * g_odata, const int n) {
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= n) return;
const int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2) {
int i = tid * stride * 2;
if (i < blockDim.x) {
idata[i] += idata[i + stride];
}
__syncthreads();
}
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
Q: Why less divergence in this implementation?
A: Suppose block size is 512 (16 warps). In the first iteration, the first 8 warps are active; in the second iteration, the first 4 warps are active, ... The key point is, all threads in a thread perform the same execution, so there is no divergence (in the first few iterations).
Q: Is this implementation perfect?
A: No. Imagine in the last several iterations, the number of active threads < 32, there will be divergence.
How to deal with this? See 5.3 Parellel reduction with unrolled warps

__global__ void reduceInterleaved(int *g_idata, int * g_odata, const int n) {
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= n) return;
const int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
reduceInterleaved maintains the same amount of warp divergence as reduceNeighboredLess, but its performance is better than reduceNeighboredLess due to the global memory load and store patterns. More details will be discussed in Chapter 4.
- instead of writing a for loop, repeat the loop body multiple times
- loop unrolling is most effective where the number of iterations is known prior
A CPU example:
for (int i = 0; i < 100; i++) {
a[i] = b[i] + c[i];
}
when unrolling factor = 2
for (int i = 0; i < 100; i += 2) {
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
}
The reason for performance gains from loop unrolling may not be readily apparent by looking at the high-level code. The improvement comes from low-level instruction improvements and optimizations that the compiler performs to the unrolled loop. Because the two instructions are independent, the memory operations can be issued simultaneously by the CPU.
For CUDA, the main goals of loop unrolling are
- reducing instruction overheads
- creating more independent instructions to schedule
Each thread block in the reduceInterleaved kernel handles just one portion of the data, which you can consider a data block. What if you manually unrolled the processing of two data blocks by a single thread block?
__global__ void reduceUnrolling2(int *g_idata, int * g_odata, const int n) {
const int idx = blockIdx.x * blockDim.x * 2 + threadIdx.x;
if (idx >= n) return;
const int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x * 2;
// unrolling 2 data blocks
if (idx + blockDim.x < n) g_idata[idx] += g_idata[idx + blockDim.x];
__syncthreads();
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
Unrolling with higher factor yields better performance as memory latency can be better hidden:
__global__ void reduceUnrolling4(int *g_idata, int * g_odata, const int n) {
const int idx = blockIdx.x * blockDim.x * 4 + threadIdx.x;
if (idx >= n) return;
const int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x * 4;
// unrolling 4
if (idx + 3 * blockDim.x < n){
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4;
}
__syncthreads();
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
__global__ void reduceUnrolling8(int *g_idata, int * g_odata, const int n) {
const int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;
if (idx >= n) return;
const int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x * 8;
// unrolling 8
if (idx + 7 * blockDim.x < n) {
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int a5 = g_idata[idx + 4 * blockDim.x];
int a6 = g_idata[idx + 5 * blockDim.x];
int a7 = g_idata[idx + 6 * blockDim.x];
int a8 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8;
}
__syncthreads();
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
Now let's consider the following situation: in the last few iterations, the number of active threads < 32 (that is, only a single warp will be scheduled).
- There will be divergence in this case.
- Because warp execution is SIMT, there is implicit intra-warp synchronization after each instruction.
Using warp unrolling can avoid executing loop control and thread synchronization logic when there is only one active warp. (The stall_sync metric in nvprof can be used to verify that fewer warps are stalling due to __syncthreads synchronization.)
__global__ void reduceUnrollWraps8(int *g_idata, int * g_odata, const int n) {
const int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;
if (idx >= n) return;
const int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x * 8;
// unrolling 8
if (idx + 7 * blockDim.x < n) {
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int a5 = g_idata[idx + 4 * blockDim.x];
int a6 = g_idata[idx + 5 * blockDim.x];
int a7 = g_idata[idx + 6 * blockDim.x];
int a8 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8;
}
__syncthreads();
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 32; stride >>= 1) {
if (tid < stride) {
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
// unrolling warp
if (tid < 32) {
volatile int *vmem = idata;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
Note that the variable vmem is declared with the volatile qualifier, which tells the compiler that it must store vmem[tid] back to global memory with every assignment. If the volatile qualifier is omitted, this code will not work correctly because the compiler or cache may optimize out some reads or writes to global or shared memory.
Why not unroll warps like this:
if (tid < 32) {
int a1 = idata[tid];
int a2 = idata[tid + 32];
idata[tid] = a1 + a2;
}
if (tid < 16) {
int a1 = idata[tid];
int a2 = idata[tid + 16];
idata[tid] = a1 + a2;
}
if (tid < 8) {
int a1 = idata[tid];
int a2 = idata[tid + 8];
idata[tid] = a1 + a2;
}
if (tid < 4) {
int a1 = idata[tid];
int a2 = idata[tid + 4];
idata[tid] = a1 + a2;
}
if (tid < 2) {
int a1 = idata[tid];
int a2 = idata[tid + 2];
idata[tid] = a1 + a2;
}
if (tid < 1) {
int a1 = idata[tid];
int a2 = idata[tid + 1];
idata[tid] = a1 + a2;
}
because there are at least 32 threads scheduled, even if the used threads are less than 32, so such unroll will not save more time.
This part can be further unrolled because we know the number of iterations prior compiling.
For GeForce GTX 1080 Ti, the maximum number of threads per block is 1024.
for (int stride = blockDim.x / 2; stride > 32; stride >>= 1) {
if (tid < stride) {
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
unrolled as:
if (blockDim.x >= 1024 && tid < 512) idata[tid] += idata[tid + 512];
__syncthreads();
if (blockDim.x >= 512 && tid < 256) idata[tid] += idata[tid + 256];
__syncthreads();
if (blockDim.x >= 256 && tid < 128) idata[tid] += idata[tid + 128];
__syncthreads();
if (blockDim.x >= 128 && tid < 64) idata[tid] += idata[tid + 64];
__syncthreads();
Define a template function using block size as template. Modify the following code:
if (blockDim.x >= 1024 && tid < 512) idata[tid] += idata[tid + 512];
__syncthreads();
if (blockDim.x >= 512 && tid < 256) idata[tid] += idata[tid + 256];
__syncthreads();
if (blockDim.x >= 256 && tid < 128) idata[tid] += idata[tid + 128];
__syncthreads();
if (blockDim.x >= 128 && tid < 64) idata[tid] += idata[tid + 64];
__syncthreads();
On host side, must invoke the kernel using switch-case:
switch (blockSize) {
case 1024:
reduceCompleteUnroll<1024><<<grid.x / 8, block>>>(d_idata, d_odata, evenSize);
break;
case 512:
reduceCompleteUnroll<512><<<grid.x / 8, block>>>(d_idata, d_odata, evenSize);
break;
case 256:
reduceCompleteUnroll<256><<<grid.x / 8, block>>>(d_idata, d_odata, evenSize);
break;
case 128:
reduceCompleteUnroll<128><<<grid.x / 8, block>>>(d_idata, d_odata, evenSize);
break;
case 64:
reduceCompleteUnroll<64><<<grid.x / 8, block>>>(d_idata, d_odata, evenSize);
break;
}
Why template function is more efficient?
The if statements that check the block size will be evaluated at compile time and removed if the condition is not true. Also, the kernel must be called with the switch-case structure as shown above. This allows the compiler to automatically optimize code for particular block sizes, but means it is only valid to launch this kernel with certain block sizes.
- Basic concepts
CUDA Dynamic Parallelism allows new GPU kernels to be created and synchronized directly on the GPU.
- Using dynamic parallelism can make your recursive algorithm more transparent and easier to understand.
- With dynamic parallelism, you can postpone the decision of exactly how many blocks and grids to create on a GPU until runtime, taking advantage of the GPU hardware schedulers and load balanc- ers dynamically and adapting in response to data-driven decisions or workloads.
- The ability to create work directly from the GPU can also reduce the need to transfer execution control and data between the host and device, as launch configuration decisions can be made at runtime by threads executing on the device.
- Basic rules
- A child grid must complete before the parent thread, parent thread block, or parent grids are considered complete. A parent is not con- sidered complete until all of its child grids have completed.
- If the invoking threads do not explicitly synchronize on the launched child grids, the runtime guarantees an implicit synchronization between the parent and child. (In this figure below, a barrier is set in the parent thread to explicitly synchronize with its child grid.)
- Grid launches in a device thread are visible across a thread block. This means that a thread may synchronize on the child grids launched by that thread or by other threads in the same thread block.
- When a parent launches a child grid, the child is not guaranteed to begin execution until the parent thread block explicitly synchronizes on the child.
- Parent and child grids share the same global and constant memory storage, but have distinct local and shared memory.
- Parent and child grids have concurrent access to global memory, with weak consistency guarantees between child and parent. There are two points in the execution of a child grid when its view of memory is fully consistent with the parent thread: at the start of a child grid, and when the child grid completes.
- All global memory operations in the parent thread prior to a child grid invocation are guaranteed to be visible to the child grid. All memory operations of the child grid are guaranteed to be visible to the parent after the parent has synchronized on the child grid’s completion.
- Shared and local memory are private to a thread block or thread, respectively, and are not visible or coherent between parent and child.

- Restrictions

__global__ void nestedHelloWorld(const int size, int depth) {
printf("Recursion level %d: Hello World from thread %d block %d\n", depth, threadIdx.x, blockIdx.x);
if (size == 1) return;
// reduce block size to half
int nthreads = size >> 1;
// thread 0 launches child grid recursively
if(threadIdx.x == 0 && nthreads > 0) {
nestedHelloWorld<<<1, nthreads>>>(nthreads, depth+1);
printf("-------> nested execution depth: %d\n", depth);
}
}
Compiling:
nvcc nestedHelloWorld.cu -o nestedHelloWorld -arch=sm_61 -lcudadevrt -rdc=true
- -arch=sm_61: dynamic parallelism is only allowed on the compute_35 architecture or above
- -lcudadevrt: explicitly link with -lcudadevrt as dynamic parallelism is supported by the device runtime library
- -rdc=true: forces the generation of relocatable device code, a requirement for dynamic parallelism
- One block

Recursion level 0: Hello World from thread 0 block 0
Recursion level 0: Hello World from thread 1 block 0
Recursion level 0: Hello World from thread 2 block 0
Recursion level 0: Hello World from thread 3 block 0
Recursion level 0: Hello World from thread 4 block 0
Recursion level 0: Hello World from thread 5 block 0
Recursion level 0: Hello World from thread 6 block 0
Recursion level 0: Hello World from thread 7 block 0
-------> nested execution depth: 0
Recursion level 1: Hello World from thread 0 block 0
Recursion level 1: Hello World from thread 1 block 0
Recursion level 1: Hello World from thread 2 block 0
Recursion level 1: Hello World from thread 3 block 0
-------> nested execution depth: 1
Recursion level 2: Hello World from thread 0 block 0
Recursion level 2: Hello World from thread 1 block 0
-------> nested execution depth: 2
Recursion level 3: Hello World from thread 0 block 0
- Two blocks

Execution Configuration: grid 2 block 8
Recursion level 0: Hello World from thread 0 block 1
Recursion level 0: Hello World from thread 1 block 1
Recursion level 0: Hello World from thread 2 block 1
Recursion level 0: Hello World from thread 3 block 1
Recursion level 0: Hello World from thread 4 block 1
Recursion level 0: Hello World from thread 5 block 1
Recursion level 0: Hello World from thread 6 block 1
Recursion level 0: Hello World from thread 7 block 1
Recursion level 0: Hello World from thread 0 block 0
Recursion level 0: Hello World from thread 1 block 0
Recursion level 0: Hello World from thread 2 block 0
Recursion level 0: Hello World from thread 3 block 0
Recursion level 0: Hello World from thread 4 block 0
Recursion level 0: Hello World from thread 5 block 0
Recursion level 0: Hello World from thread 6 block 0
Recursion level 0: Hello World from thread 7 block 0
-------> nested execution depth: 0
-------> nested execution depth: 0
Recursion level 1: Hello World from thread 0 block 0
Recursion level 1: Hello World from thread 1 block 0
Recursion level 1: Hello World from thread 2 block 0
Recursion level 1: Hello World from thread 3 block 0
Recursion level 1: Hello World from thread 0 block 0
Recursion level 1: Hello World from thread 1 block 0
Recursion level 1: Hello World from thread 2 block 0
Recursion level 1: Hello World from thread 3 block 0
-------> nested execution depth: 1
-------> nested execution depth: 1
Recursion level 2: Hello World from thread 0 block 0
Recursion level 2: Hello World from thread 1 block 0
Recursion level 2: Hello World from thread 0 block 0
Recursion level 2: Hello World from thread 1 block 0
-------> nested execution depth: 2
-------> nested execution depth: 2
Recursion level 3: Hello World from thread 0 block 0
Recursion level 3: Hello World from thread 0 block 0
Q: Why are the block ID for the child grids all 0?
A: The launch configuration within the parent kernel is nestedHelloWorld<<<1, nthreads>>>(nthreads, depth+1); While the parent grid contains two blocks, all nested child grids still contain only one.
CPU sequential implementation:
int interleavedPairReduce(int *data, const int size) {
if (size == 1) return data[0];
const int stride = size / 2;
for (int i = 0; i < stride; i++) {
data[i] += data[i + stride];
}
return interleavedPairReduce(data, stride);
}
- First try
- Children are invoked by thread 0 of each parent block
- Each child has 1 block
- After the in-place reduction is complete, the block is synchronized to ensure all partial sums are computed.
- After the child grid is invoked, a barrier point is set for all child grids. Because only one child grid is generated by one thread in each block, this barrier point only synchronizes with the one child grid.
__global__ void gpuRecursiveReduce (int *g_idata, int *g_odata, const int n) {
int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
int *odata = g_odata + blockIdx.x;
// int *odata = &g_odata[blockIdx.x];
// stop condition
if (n == 2 && tid == 0) {
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
int stride = n >> 1;
if(stride > 1 && tid < stride) {
// in place reduction
idata[tid] += idata[tid + stride];
}
__syncthreads(); // sync at block level
// nested invocation to generate child grids
if (tid == 0) {
gpuRecursiveReduce<<<1, stride>>>(idata, odata, stride);
// sync all child grids launched in this block
cudaDeviceSynchronize();
}
__syncthreads(); // sync at block level again
}
The performance is unacceptably poor (even slower than CPU execution!) because of large amount of kernel invocation and synchronization.
Modification: When a child grid is invoked, its view of memory is fully consistent with the parent thread. Because each child thread only needs its parent’s values to conduct the partial reduction, the in-block synchronization performed before the child grids' launch is unnecessary.
- Second try: remove all synchronizations
__global__ void gpuRecursiveReduceNosync (int *g_idata, int *g_odata, const int n) {
int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
int *odata = g_odata + blockIdx.x;
// int *odata = &g_odata[blockIdx.x];
// stop condition
if (n == 2 && tid == 0) {
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
int stride = n >> 1;
if(stride > 1 && tid < stride) {
// in place reduction
idata[tid] += idata[tid + stride];
if (tid == 0) {
gpuRecursiveReduceNosync<<<1, stride>>>(idata, odata, stride);
}
}
}
The performance is still poor due to overhead caused by the large number of child grid launches.
Modification: currently, the dynamic parallelism is in the form of left figure, where each parent block invokes a child grid, resulting in a large number of child grid launches. Instead, we can take the form of right figure, where only the first parent block invokes child grid.

- Third try
__global__ void gpuRecursiveReduce2 (int *g_idata, int *g_odata, const int stride, const int blkDim) {
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blkDim;
// stop condition
if (stride == 1 && threadIdx.x == 0) {
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
// in place reduction
idata[threadIdx.x] += idata[threadIdx.x + stride];
// nested invocation to generate child grids
if(threadIdx.x == 0 && blockIdx.x == 0) {
gpuRecursiveReduce2<<<gridDim.x, stride / 2>>>(g_idata, g_odata, stride / 2, blkDim);
}
}
- Avoiding a large number of nested invocations helps reduce overhead and improve performance.
- Synchronization is very important for both performance and correctness, but reducing the number of in-block synchronizations will likely lead to more efficient nested kernels.
- Because the device runtime system reserves extra memory at each nesting level, the maximum number of kernel nestings will likely be limited.
- Metrics mentioned in this chapter
- branch_efficiency: NON-divergent branches / total branches
- stall_sync: warps that are stalling due to __syncthreads
- dram_read_throughput: device memory read throughput
- achieved_occupancy: the average active warps per cycle / the maximum number of warps supported on an SM
- gld_throughput: global memory load throughput; gst_throughput: global memory store throughput
- gld_efficiency: requested global load throughput / required global load throughput. It measures how well the application’s load operations use device memory bandwidth (if the throughput is high but the efficiency is low, the performance will still not be good). Similar: gst_efficiency: measures memory store operations
- Events mentioned in this chapter
- branch
- divergent_branch
This exercise is a good example to understand various metircs.


Use metrics to explain the performance difference:


- The performance is similar to integer reduction. (Actually, on older GPU architectures, contention for floating-point arithmetic logic units may lead to a loss in performance. However, on many GPUs there will be no difference in performance.)
- The reduction results of float are different from each other:

Calm down, there is no bug in the code. Read this: 浮点数float累加误差分析与解决