Structure From Motion - Sandeep10021/mapmint GitHub Wiki
Structure From Motion is a method of estimating the motion of the camera and the reconstructed three-dimensional (3D) structure of the photographed scene with images taken at two or more different viewpoints. The method can be categorized into two classes in terms of input image types; one is the method with images acquired sequentially through a single camera, such as video sequence, and another method is estimating with unordered image set with different views. One of the commonly known algorithm among the various versions of structure from motion methods that is used in 3D Point Cloud Generation is known as Incremental Structure From Motion.
Structure from motion is a pipe lined algorithm in which each sub-task is processed sequentially as shown in figure, and the incremental structure from motion which contains the iterative reconstruction process is most often used. In the correspondence search step, feature points are extracted for each image. We use the feature descriptors which are invariant to size and rotation so that the structure from motion can easily recognized feature points extracted multiple view images. Basically SIFT and SURF, which are robust feature point descriptors, are widely used for this purpose. Matching process for those descriptors can be implemented with RANSAC for the accuracy of the correspondence. Nowadays ORB feature is famously used for feature extraction and description with lower computational cost than previous features. The descriptor of ORB feature can be expressed into binary representation, so the correspondence matching can be done with Hamming distance comparison, which is faster than other matching methods.
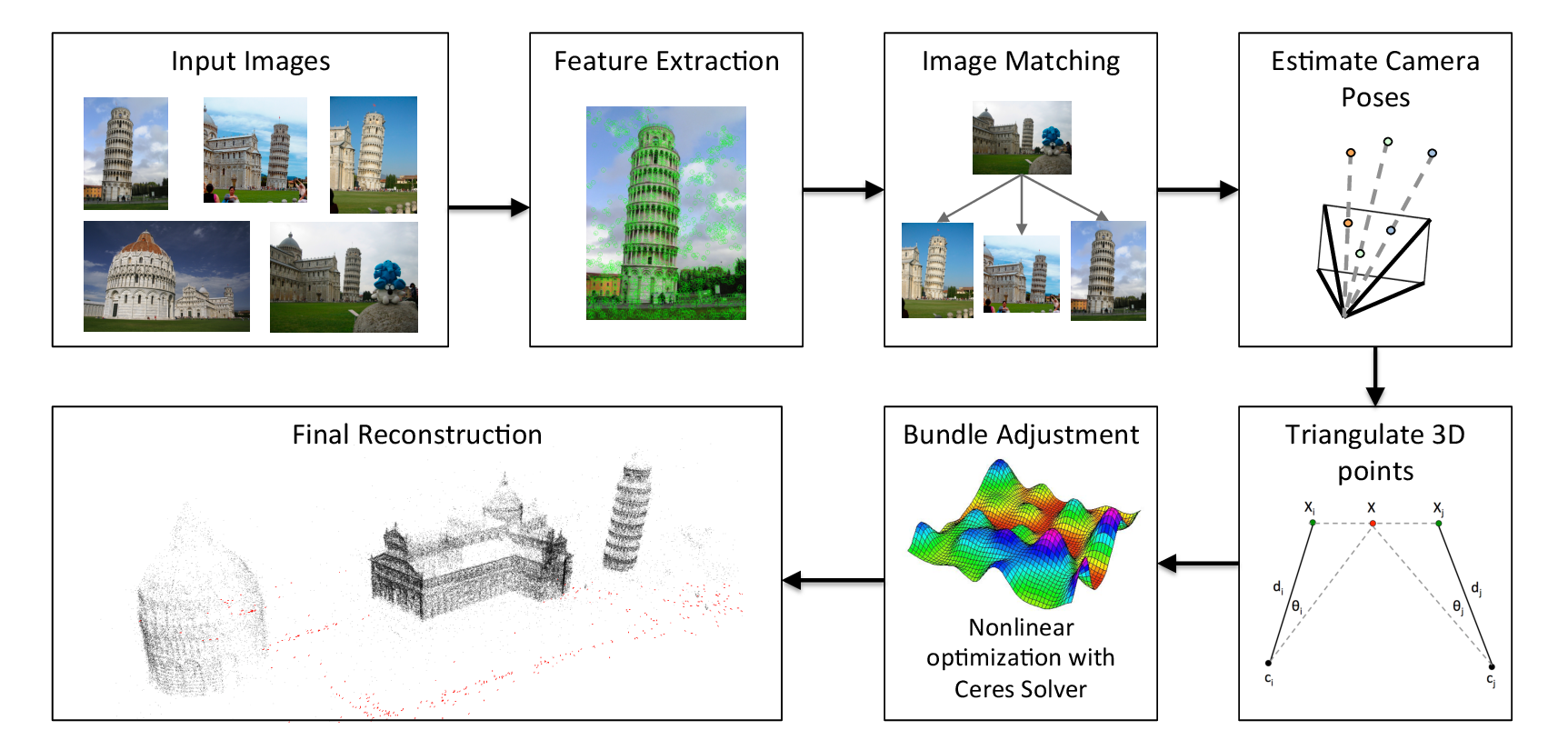
Incremental Structure From Motion Algorithm
Feature point extraction and matching are only for the external shape and do not guarantee the same correspondence with real 3D scene points. Therefore, a geometric verification process is performed to confirm the accuracy of the correspondence point search by the method of estimating the homography between the images. It can be said that a sufficient amount of feature point pairs has been verified only if it is properly projected. A scene graph is created by connecting each image as a vertex with the output data and connecting the verified image pair with a line.
In the incremental reconstruction step, the motion of the camera and the reconstructed 3D point cloud are obtained based on the generated scene graph from the previous step. First, the initial 3D reconstruction model is initialized with the two-view images. The initial model must include the correspondence relation between the feature points on the two-dimensional viewpoint and the points corresponding to the actually observed 3D scene.
Thereafter, the remaining multiple view images are added to the model one by one. Since this process can acquire the extrinsic camera parameters by estimating camera motion information through the Perspective-n-Points (PnP) algorithm, the triangulation process acquires a new 3D scene point for the added viewpoint image.
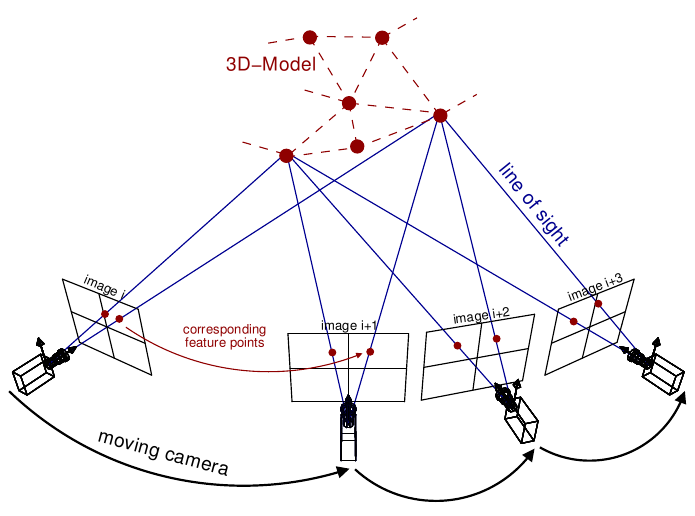
Iterative Reconstruction of Incremental Structure From Motion