期末報告 - Sakura01210/co110a GitHub Wiki
補充教材學習報告
參考資料
nand2tertris電腦變快的方法
- 加入除法和乘法的電路
- 加入浮點數的電路
- 把原本的漣波進為加法器改成前瞻進位加法器
加入除法和乘法的電路
乘法
乘法電路是一種完成兩個互不相關的模擬信號相乘作用的電子器件。它可以將兩個二進制數相乘。它是由更基本的加法電路組成的。

乘法器在當今數字信號處理以及其他諸多應用領域中起着十分重要的作用。隨着科學技術的發展,許多研究人員已經開始試圖設計一類擁有更高速率和低功耗,佈局規律佔用面積小,集成度高的乘法器。這樣,就能讓它們更加適用於高速率,低功耗的大規模集成電路的應用當中。
乘法器是一種完成兩個互不相關的模擬信號相乘作用的電子器件。它可以將兩個二進制數相乘。它是由更基本的加法器組成的。通常的乘法計算方法是添加和位移的算法。在並行乘法器當中,相加的部分乘積的數量是主要的參數。它決定了乘法器的性能。為了減少相加的部分乘積的數量,修正的Booth算法是最常用的一類算法。為了實現速度的提高Wallace樹算法可以用來減少序列增加階段的數量。我們進一步結合修正的booth算法和Wallace樹算法,可以看到將它們集成到一塊乘法器上的諸多優勢。但是,隨着並行化的增多,大量的部分乘積和中間求和的增加,會導致運行速度的下降。不規則的結構會增加硅板的面積,並且由於路由複雜而導致中間連接過程的增多繼而導致功耗的增大。另一方面串並行乘法器犧牲了運行速度來獲得更好的性能和功耗。因此,選擇一款並行或串行乘法器實際上取決於它的應用性質。

除法
在加減乘除的過程當中除法是最複雜的,
因此還是先使用模仿紙筆的運算過程來看一下運算過程

轉化成適合硬體實現的運算步驟可以得到下圖:
因此可以知道被除數若是八位寬,則除數和餘數都是四位
而被除數也可以看成是與餘數共享,另外除數和商數也是分別透過左移和右移來完成

以下為除法器電路圖

加入浮加入浮點數的電路
每秒浮點運算次數
浮點運算次數,亦稱每秒峰值速度,即每秒所執行的浮點運算次數。浮點指的是帶有小數的數值,浮點運算即是小數的四則運算,常用來測量電腦運算速度或被用來估算電腦效能,尤其是在使用到大量浮點運算的科學計算領域中。因為FLOPS字尾的那個S代表秒,而不是複數,所以不能夠省略。在多數情況下,測算FLOPS比測算每秒指令數要準確。
浮點運算實際上包括了所有涉及浮點數的運算,在某類應用軟體中常常出現,比較整數運算更用時間。現今大部分的處理器中都有浮點運算器。因此每秒浮點運算次數所量測的實際上就是浮點運算器的執行速度。常用來測量每秒浮點運算次數的基準程式之一,是Linpack。
LINPACK是一個在數位電腦上執行數字線性代數的軟體函式庫。
效能表現
FLOPS 和 MIPS 都是用來測量電腦數字運算效能表現的方式。浮點運算測試通常用在科研和研究領域。 MIPS則用來測量電腦的整數操作效能。 整數操作的例子包括資料轉移(從A到B),條件測試(當 A=B時,執行C). 當一台電腦被用來進行資料庫查詢,文書處理、電子試算表製作或執行多個虛擬機器時,一般進行MIPS基準效能測試就足夠了。 來自勞倫斯利弗莫爾國家實驗室的弗蘭克·H·麥克馬洪發明了FLOPS和MFLOPS這兩個術語。以便他能夠比較現代的超級電腦每秒鐘能夠進行的浮點運算次數。 這比普遍使用的MIPS更適合測算那些能夠進行大量數字運算的電腦。
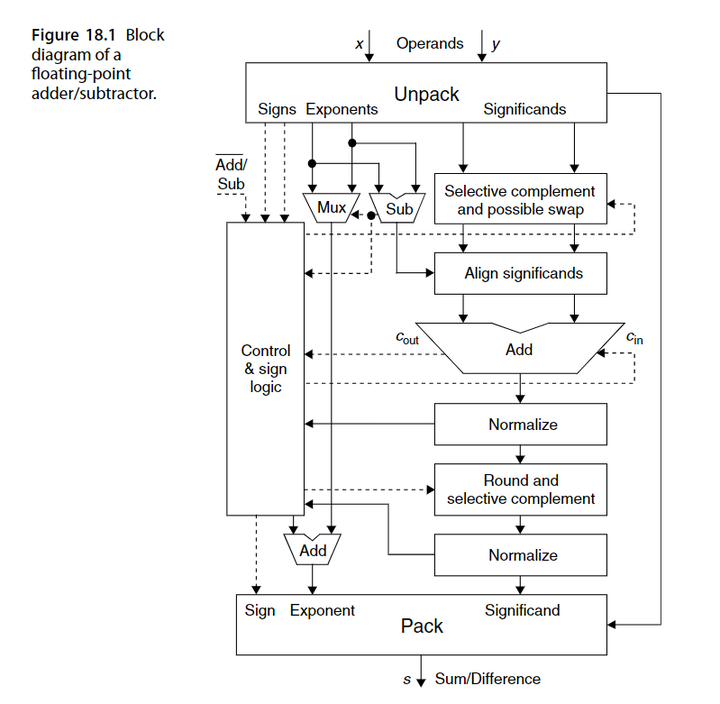
浮点数加减运算器
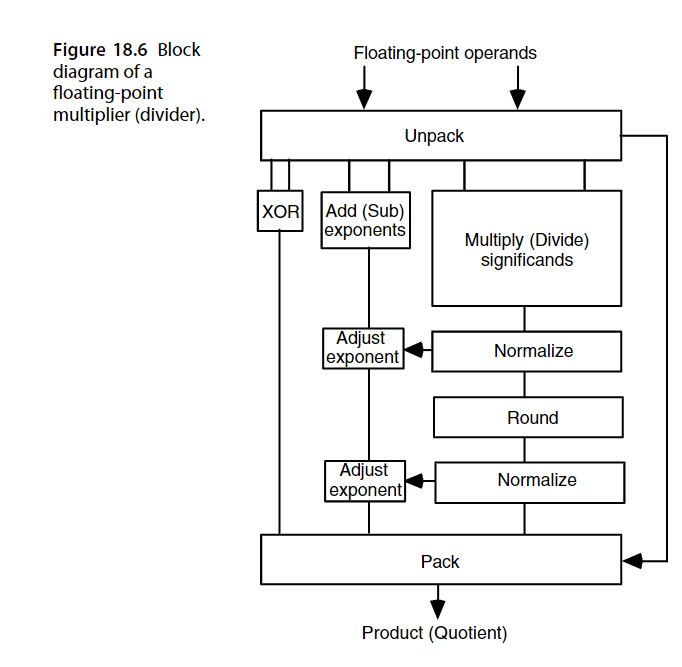
浮点乘除运算器
以下貼文來自漣波進位加法器和前瞻進位加法器的實作與研究
漣波進為加法器改成前瞻進位加法器
漣波加法器
漣波加法是按部就班的 1 次進行 1 個位元的加法(進行 4 次加法)才能得出結果,也就是必須由 2 個數值的最低位元先相加得出的商和進位才能進行第二次的運算,進行 4 次。
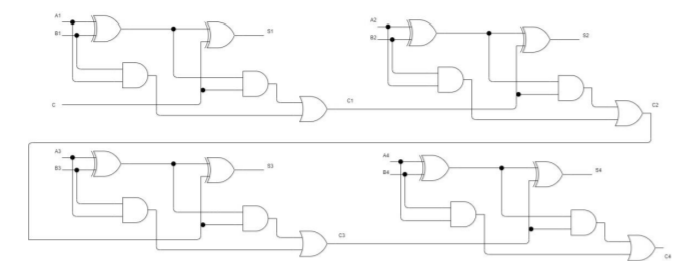
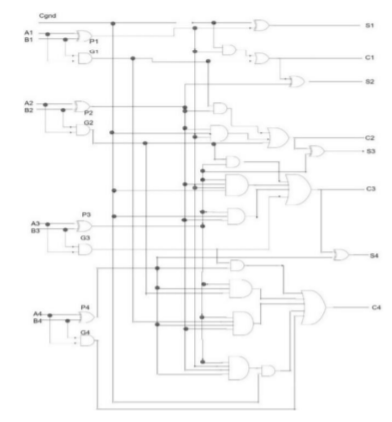
前瞻進位加法器
前瞻進位加法器是 1 次進行 4 個位元的加法,不需要等到最低的兩位元加法得出的商,在進行下一個位元的運算,因此可以省下許多時間。
以下貼文來自[RISC-V介紹1] 三分鐘帶你了解RISC-V
risc-v 處理器
什麼是RISC
CPU 的指令集可簡單分為 2 種:RISC(reduced instruction set computer, 精簡指令集電腦)和 CISC(Complex Instruction Set Computer, 複雜指令集電腦)。
什麼是指令集
中央處理器 CPU
電腦的運算核心,靠著 解讀與執行指令(instruction) 來維持電腦的運作。
組合語言與指令
我們在寫程式的時候,以 C++ 為例,要單純計算兩個數字相加,你可能會這樣寫:
int a,b,c;
a = 3;
b = 4;
c = a + b;
但是 C++ 是高階的語言,電腦看不懂,我們需要一個編譯器來把它轉成機器“比較”看得懂的組合語言。
在組合語言就是各式各樣的指令,這些指令各有不同的功能,像是把記憶體內部的資料載入 CPU 的暫存器、把兩個暫存器存資料的加起來、跳到另外一行執行等等,為了要讓 CPU 看得懂,在 C++ 裡面一行就可以寫完的東西這邊要變成很多步驟。
以上面code的第四行為例,會需要進行下列的步驟:
1. 把 a 從記憶體移到 暫存器1 中
2. 把 b 從記憶體移到 暫存器2 中
3. 把 暫存器1 和 暫存器2 的內容加起來放進 暫存器3 中
4. 把 暫存器3 放進記憶體中 c 的位置
上述的每個步驟就是一個指令,步驟1和步驟2的功能相同,那他們就屬於相同的指令,打成 RISC-V 的指令名稱就會長這樣 :
LD //load
LD //load
ADD //add
SD //save
不同的 CPU 架構的指令名稱就會跟這個不一樣,雖然基本功能都差不多,但*指令的細節會不太一樣,因此在不同 CPU 架構上編譯出來的組合語言也是不同的。
我們知道一個 CPU 的工作就是負責讀懂這些指令進行運算,因此餵給某個 CPU 的指令必須要是它看得懂的才行,而一個 CPU 看得懂的所有指令,我們就叫他“某 CPU 的指令集”,像是 RISC-V 的指令集、x86 的指令集、MIPS 的指令集等等。
為什麼要有不同的 CPU 指令集
CPU 指令集可以被簡單分類在 RISC 和 CISC 中,像是 RISC-V、MIPS、Arm 架構屬於 RISC,x86 屬於CISC。RISC 指令集中的指令數量不多,功能也不多,所以需要較多指令才能相同的工作;CISC 則相反,他指令數量超多,功能超多,很多時候只要一行指令就可以完成需要的功能。詳細比較如下:

因為兩者各有優缺點,根據不同的應用我們會需要不同的 CPU 架構:CISC 功能強大,適合高性能但同時高功耗的 CPU 架構,像是 Intel x86 ;RISC 架構簡單,適合需要面積與功耗較小的行動裝置,所以像是手機裡的 Arm 晶片就是屬於 RISC 架構的一種。
值得一提的是,電腦發展並不是一開始就有 CISC 和 RISC 兩種架構的。CISC 是在 RISC 的出現後才出現與其相對的名詞。
RISC-V在紅什麼?
指令集精簡
RISC 架構簡單,因此面積小且功耗低。 因為硬體每個功能都需要事先寫好刻成一個電路,所以指令格式愈一致,需要的電路就愈簡單,面積也就愈小,功耗也會愈低,且資料從進去 CPU 到出來的時間也會較短,所以每秒可以做的運算也愈多。此外,指令格式愈一致,執行pipeline*的效果就愈好,也就可以節省更多的時間。 就現在的趨勢來看,我們希望 CPU 算得愈快愈好,因此指令集要愈精簡愈好,而 RISC-V 就是設計更為精簡的 RISC 指令集。因為現在 CPU 已經算得很快了,要讓它更快的成本要比以前更多,為了讓同一代 CPU 能用更久,RISC-V是一個很好的選擇。
開源指令集
容易取得資源,不像 x86 受制於所屬公司知識產權的控制,因此不需授權費用,成本較低。
彈性較大
這是 RISC-V 與 Arm 的最大差別,它預留了客製指令的擴充空間,可以根據不同需求做出相對應設計。這點在 x86 和 Arm 處理器中幾乎做不到,如果需要加強某些特定的功能,價格也會隨之上升。