Project 2 - Saiaishwaryapuppala/Python-Project-1 GitHub Wiki
PYTHON PROJECT 2
TEAM – 5
INTRODUCTION:
- Python group project with the below team:
Bindu Gadiparthi -49
Harinireddy Anumandla -03
Aishwarya -35
Sai Prasad Raju -07
koushik reddy sama -42
First Program:
Code:
- Importing the required libraries:
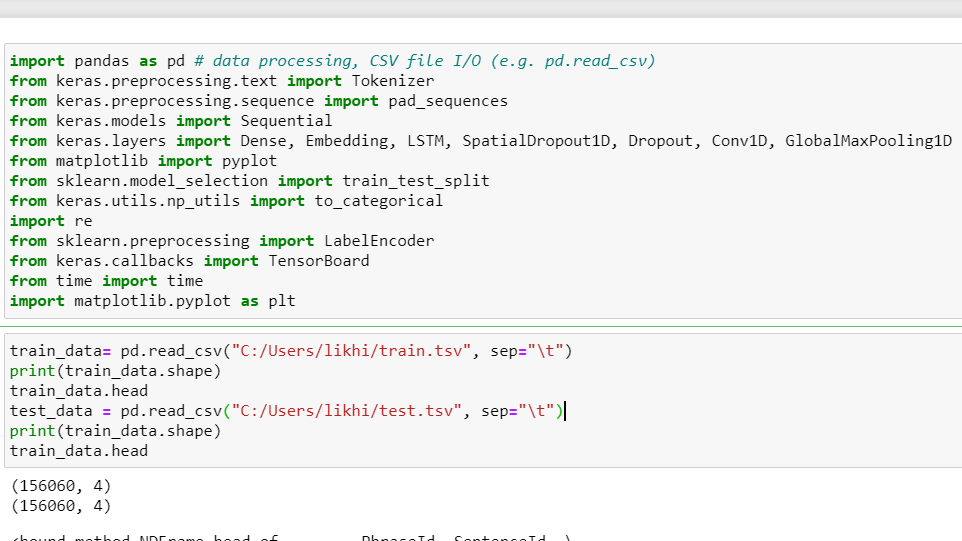
- Reading the given datasets and printing them.
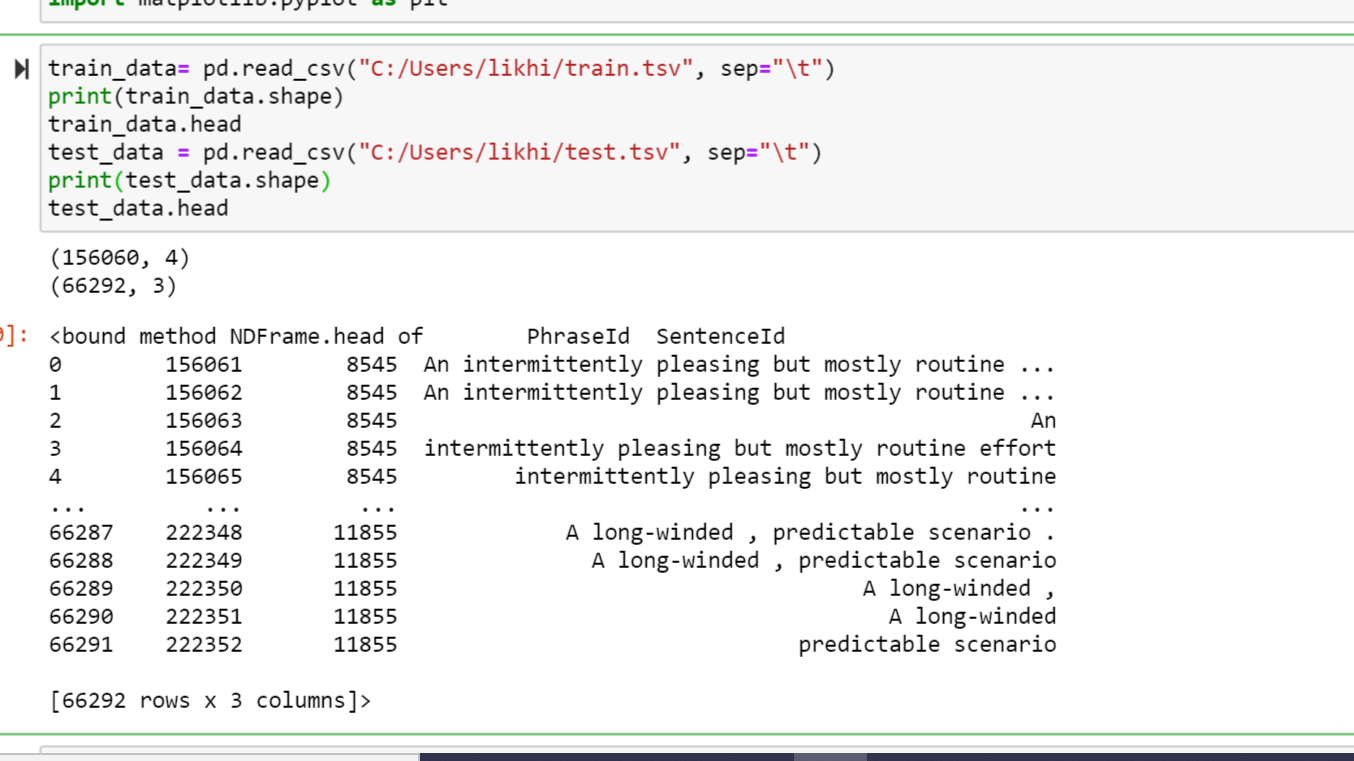
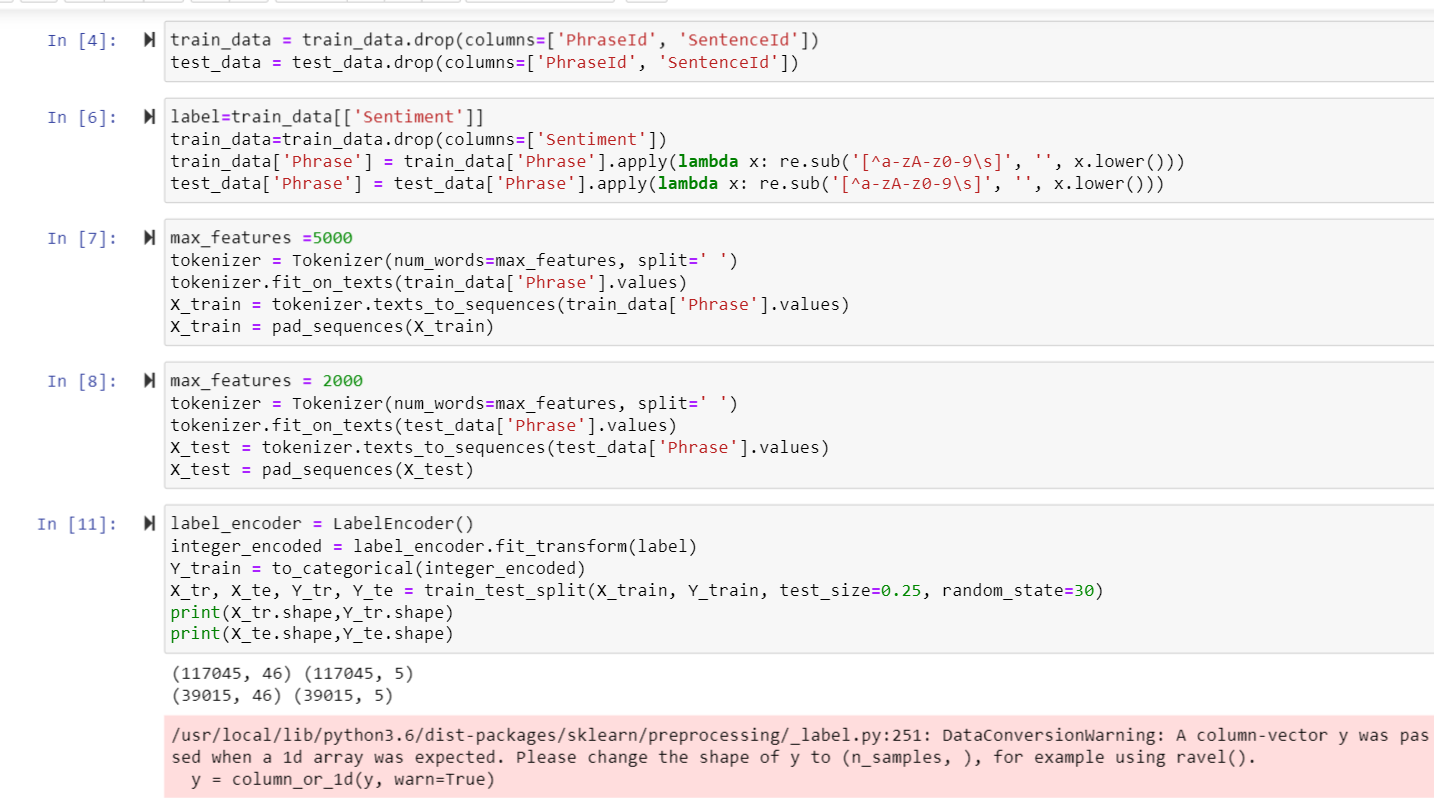
- Adding the embedded the layer and printing the history object.
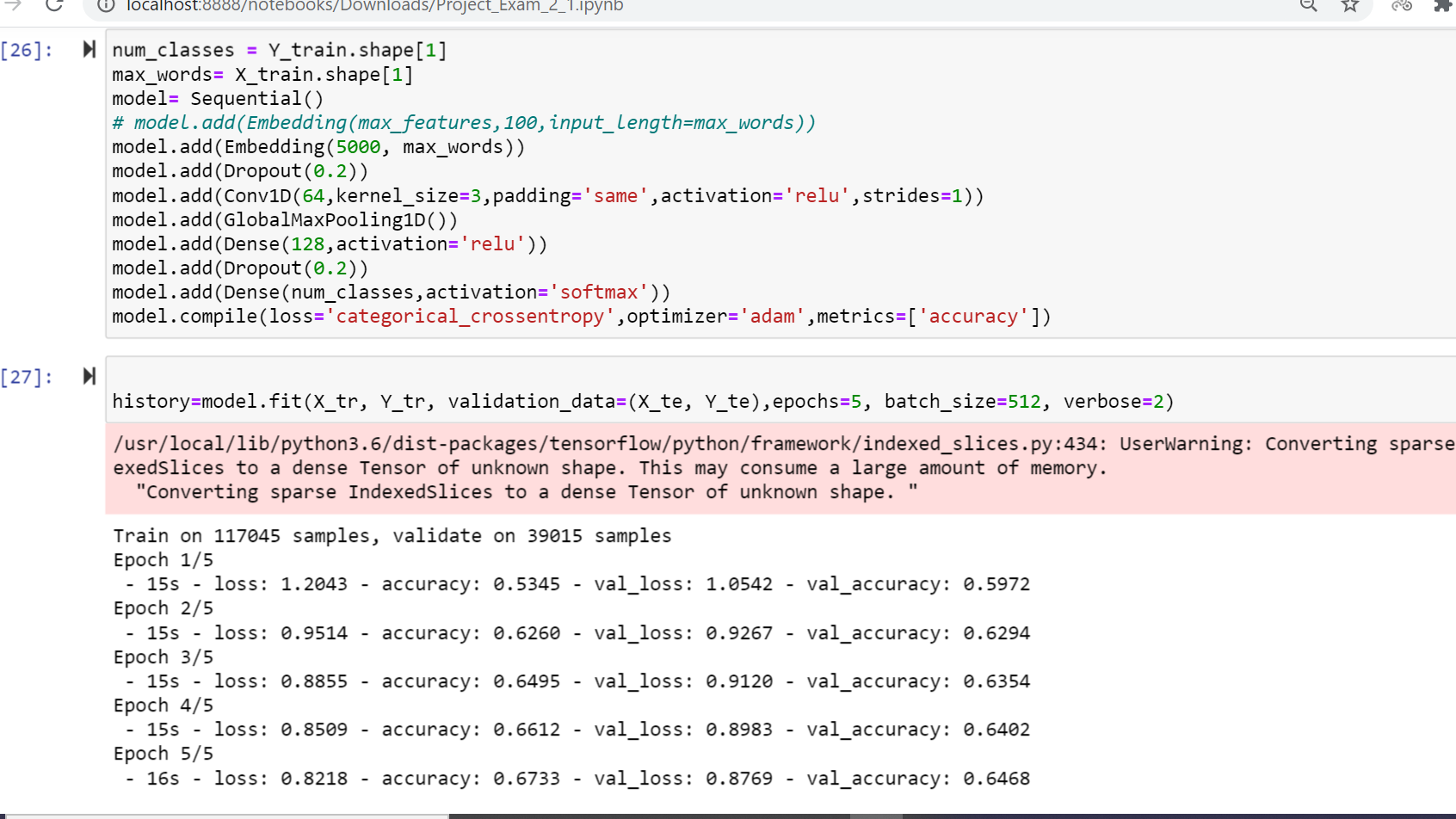
- Reporting the accuracy score and plotting the graphs of accuracy and loss values of the data.
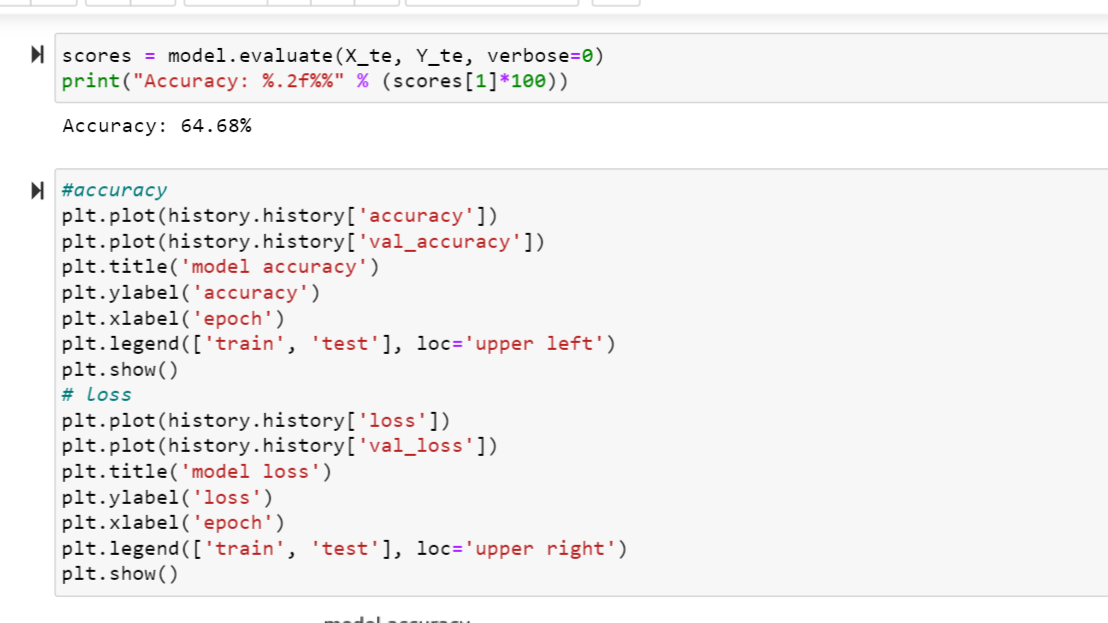
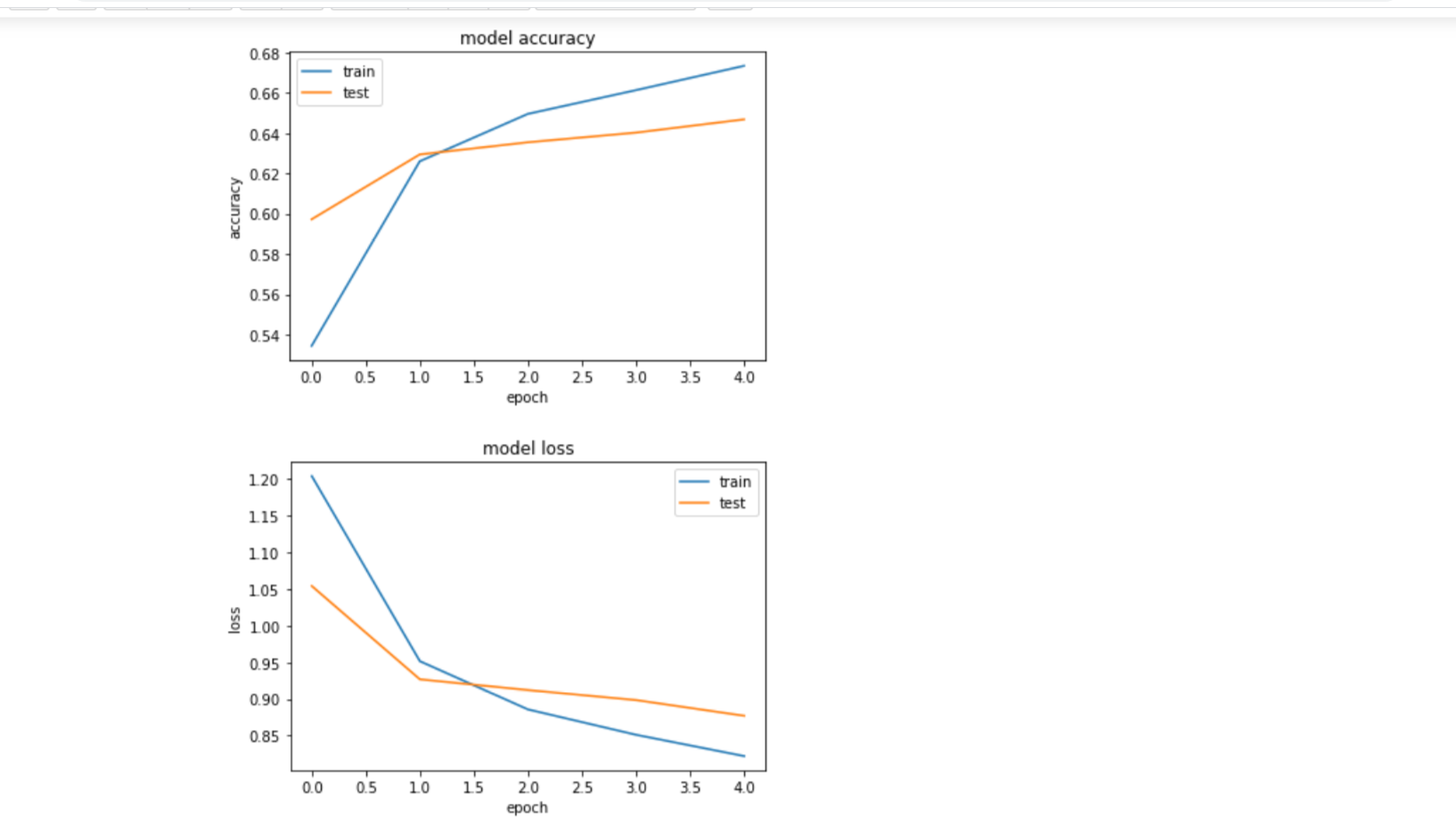
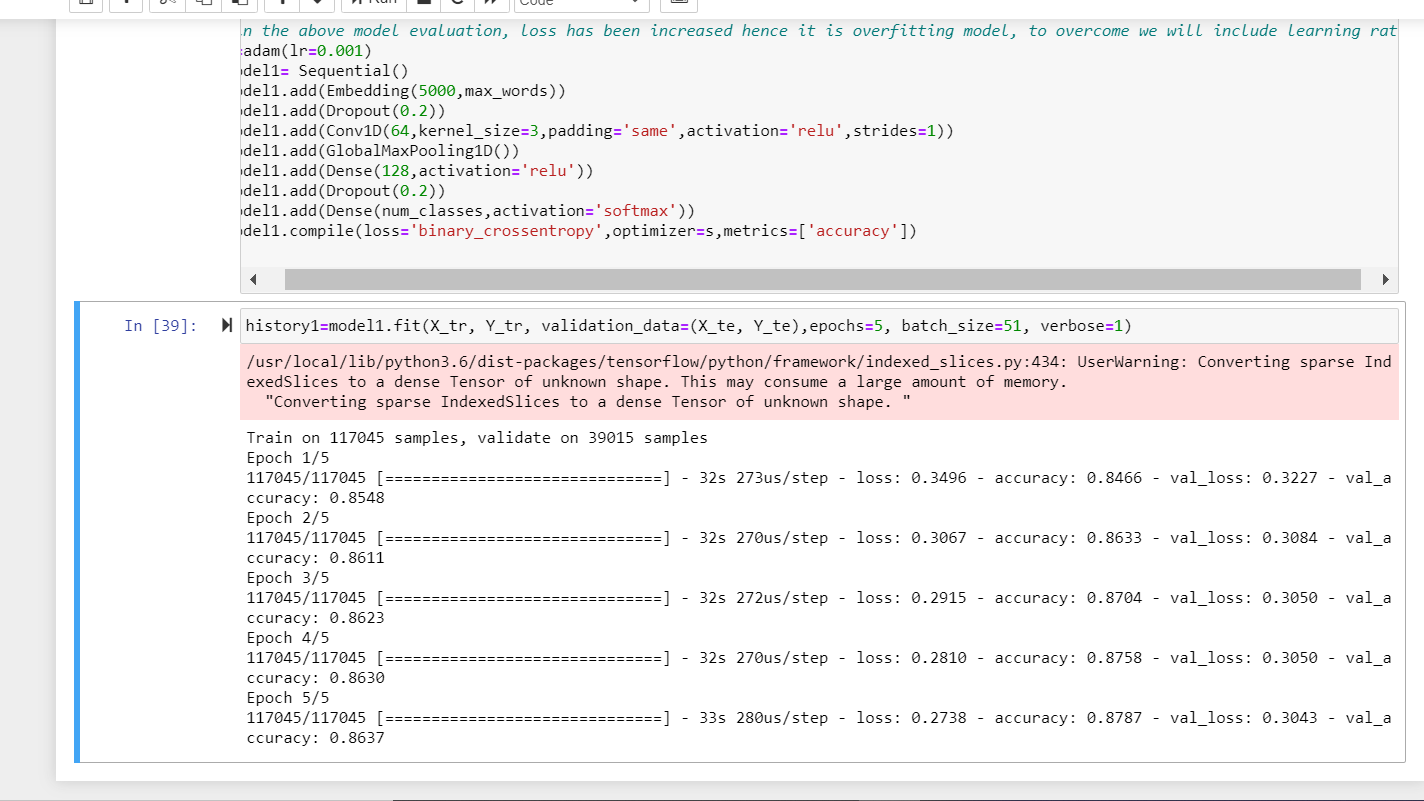
- After plotting the loss there is an increase in the overfitting model. To minimize it I have included learning rate and there is a decrease in the loss.
- Implement text classification on the 20news_group dataset using LSTM model.
a. Include Embedding layer in the design of your models and report if that leads to a better performance
b. Plot loss of the model and report if you see any overfitting problem
Dataset
The dataset consits of the 20news_group which consits of several information about politics,religion and much more. Considering this data set we are implementing Text classification.
Explanation
The given dataset 20news_group is splited into data and test sets. Tokenizer was applied to fit on raw text documents. Input_data is obtained by pad_sequences. Then, the model was built with only one LSTM and Dense layer, accuracy and loss plot is plotted.




Without Embedded Layer




The accuracy result somehow was very consistent (.85) despite how many epochs there were and the loss value is gradually decreased.


Adding Embedded Layer
-
After adding the embedding layer, the model reshaping was no longer needed. There were some tradeoffs even then the training time increased significantly, the accuracy result overall had improved (from .85 to greater than .9).
-
Despite the performance difference, the value gap between training and testing score was not significant enough to indicate if there was overfitting in the model. Hence, the model performed better with the embedding layer added.



Task 3
The main objective of this task is to implement image classification with the CNN model for the given datasets. We have imported all the required libraries ad natural images dataset. Then we made the count of the total categories in the dataset.
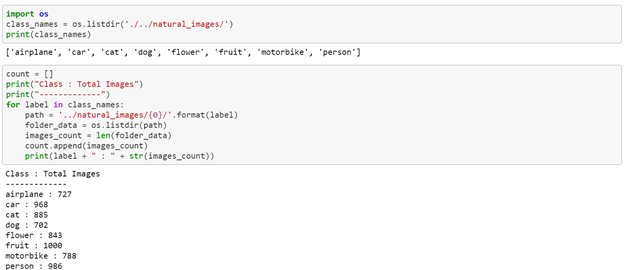
Next, we have plotted the dataset.

Then we have read the data in the sets and converted them into NumPy arrays. Also shuffled the data.

Now we have encoded the class names and converted the categorical values. Then we split the data into train and test.

Here we have implemented the model.

Next, we have compiled the model.

Then we have saved the model as image classifier h5 and calculated accuracy.

We have predicted model here


Next, we have implemented a model with scaling.
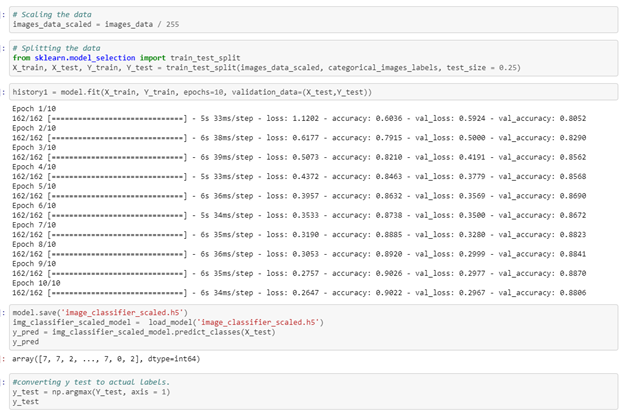
We calculated accuracy and then we made a prediction. Here accuracy increased to 88.

Predicted image clarity has been increased

In this task, we have observed that the accuracy increased with scaling than without scaling.
Task 4:
The purpose of this question is to learn about text generation. Use New York Times Comments and Headlines to train a text generation language model which can be used to generate News Headlines
a.Pass a sample headline or word to the model and predict the generated headline
Code Explanation :
Imported the required libraries
Load the dataset of New York headlines

The Dataset is Preprocessed, By performing Text cleaning which includes Removing of punctuation and Lower Casting all the words in the dataset.

Next we need to tokenize the data, which can be used to obtain the tokens and their index. So that every text document in the dataset is converted into sequence of tokens.

We need to pad the Sequence of Tokens such that all the sequences are in the same size.

Create the Sequential Model and Layers are created and The model is trained with data

The Function generate_txt is used to predict the next word based on the input words.We have first tokenized the seed text, pad the sequences and pass it into the trained model to get predicted word.
