Image_Processing - RicoJia/notes GitHub Wiki
========================================================================
========================================================================
- motion vector: we want to minimize the number of bits for representing a pixel in a given frame. found by minimizing this:
- invented for video encoding. Each intensity is [0,255], but if you can find pixel correspondences, you just need to specify the vector, and delta Intensity.
-
frame is an image at a given time
-
If this is the first frame, don't do anything
-
For second frame
- say you have NxN pixel blocks
- You search an NxN block in the previous frame, such that the average pixel-by-pixel intensitity difference is minimum
- The displacement between the two blocks is "motion vector"
-
Search algorithm will quickly find that displacement
-
Intro to computer vision (free course on Coursera)
-
microsoft kinect (cambridge, revolutionary for skeleton tracking)
-
why this is hard, seeing is called "percept"
Your eyes perceive differently than intensity
-
Outline:
- image processing
- Camera Models
- Features and matching
- lightness and brightness
- image motion
- motion and tracking
- classification and recognition
- Opencv was from intel, then willow garage, then openrobotics, now non-profit
-
Computer Vision
-
what is camera calibration:
- pose, focal length
-
recovering 3D models of the environment: Armeni etal.2016
-
Image Processing Basics
- Histogram, histogram equilization
- thresholding
- Convolution
- Sharpening & edge detection
- morphological operations
- Image Pyramids
-
Practice:
- Corner Detection
- Keypoint matching
- App using keypoints
-
Segmentation
- contiyrs
- Contour property
- Line detection, circle detection, blob detection
- watershed segmentation
-
people counting
- Line passing the horizontal line
- OpenCV tracking API, filtering by color
- Moving object tracking
-
Object Detection
- Cascade Classifier
- HOG: pedestrian
- OpenCV tracking API, filtering by color
-
Moving object tracking- Object Detection
- Cascade Classifier
- HOG: pedestrian Line passing the horizontal line
- OpenCV tracking API, filtering by color
- Moving object tracking
-
Object Detection
- Cascade Classifier
- HOG: pedestrian Line passing the horizontal line
- OpenCV tracking API, filtering by color
- Moving object tracking
-
Object Detection
- Cascade Classifier
- HOG: pedestrian
- Deep Learning Model
========================================================================
========================================================================
-
Image is a function
f(x,y), and you can plot their values:

-
smoothing of a function = blurring of an image

-
image will have a min, max, even negative nums
- 255 is a pure incident
-
image: --> x(j), | V y(i)
-
MATLAB indexing starts at 1
-
-
Filter:
-
average filter is always odd.
-
moving average with a uniform one [1,1,1,1]*0.25, in 2d, it's called box filter

-
moving average non-uniform one, with 4 in the middle, can preserve the "characteristics" [1,2,4,2,1] (middle one is the one x current val, this is also the kernel, or mask)

-
in 2d, it's a "Gaussian filter"
caption

-
Gaussian filter will be smoother, cuz a single pixel convoluted with a gaussian filter is still a blob
caption
-
Note that Gaussian filter's first term (aka normalization coefficient, which affects brightness) is 1/(2pi*sigma), not 1/(sqrt(2p) * sigma)
-
the word isotropic means "circularly symmetric"
-
- size of the kernal is not "the bigger kernal", bigger here means the standard deviation of gaussian.
- the size of the kernel is the bigger the better,because it will provide smoother performance.
- the bigger the kernel, the blurrer it will be
-
Filters
-
If a filter does cross-correlation with an impulse, you don't get "flipped version" of the impulse
Impulse response is flipped!
-
Convolution is when you do have filter or the image "flipped" around a pixeli (or rotate by 180 deg). you flip a filter (about the center), then move it around the image, multply and add.
-
So the impulse response of a filter will be the impulse response itself
-
when the filter is symmetric, cross-correlation and convolution give you the same result.
-
Convolution properties:
f*g = g*ff*(g*h) = (f*g)*h- del(f * g) = del(f) * g, here
del f = del (f)/del(x)(useful in edge detection)
-
Complexity
- a convolution: NxN filter on an MxM image, that'd be
N^2M^2multiplcations and additions - if you have linearly separable filter:
C*R, think of the two as padded 3x3 matrices,The complexity is[1 2 * [1 2 1] = 1] [1 2 1 2 4 2 1 2 1](C * R) * F = C * (R*F) = 2xN x M^2
- a convolution: NxN filter on an MxM image, that'd be
-
with zero-padding, dark edge will "leak in" after filtering

-
Unsharp Mask: just (could be done with chemicals, because it's a blurry version of the original), then you do
F - M, you will get a sharper picture[1 2 3 [1 1 1 M= 2 3 4 - 1 1 1 3 4 5] 1 1 1] -
Median filter: to remove salt-pepper noise (random spikes here and there), by finding the median of the neighbor. Because here we're assuming image as a function should be "continuous". We also call it edge-preserving

-
-
Filters as templates
- A template is a "pattern" that we're looking for. When a filter cross-correlates itself, it gets its highest value when being with a similar pattern
- The technique we use is called "normalized correlation":
Normalised_CrossCorr = (1/N)*sum((x-mean(x))*(y-mean(y)))/(sqrt(var(x)*var(y));- Scale all filter values so their standard deviation become 1
- Scale the local patch values so their standard deviation become 1 as well
- do the correlation across the image, and find the patch with the highest value
- template can only work for the exact same images
========================================================================
========================================================================
-
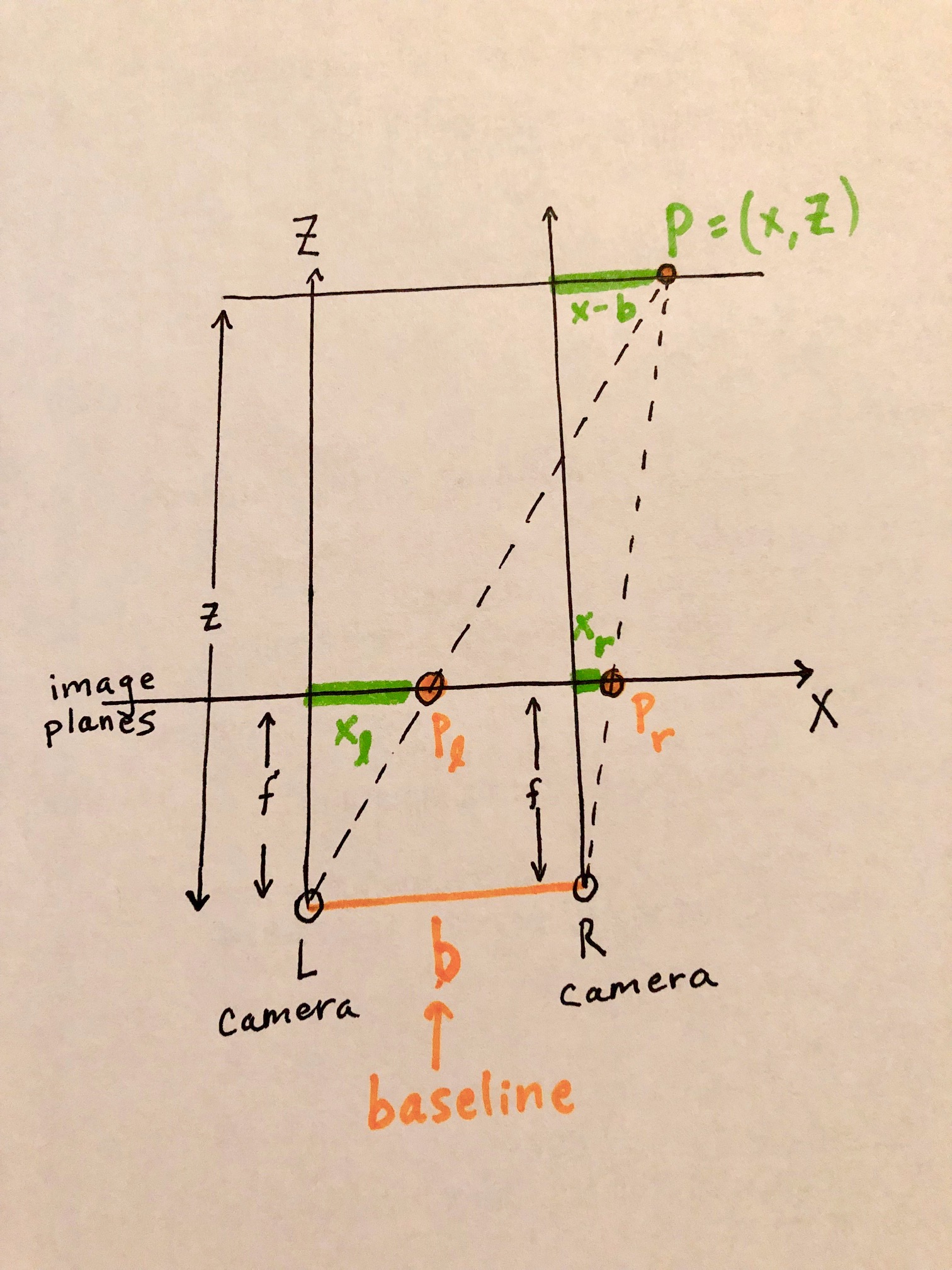
disparity: In Stereo Vision, disparity is the difference in pixel of the same point, x_l - x_r
- Have a window (xl) to compare similarity for
- Going along epipolar line, in a search region, slide along the window, find window (xr) has the highest similarity score
- For pixel xl, the disparity value is |xr-xl|. That's the disparity value
- **A good general workflow is: **
fish eye camera view -> projection (fish eye to surface projection will cause downscaling)-> ROI generation (thresholding disparity values) -> ROI mask (reproject the mast back to the fish eye view)
========================================================================
========================================================================
- edge is sudden decrease/increase in pixel values, perpendicular to the image gradient
- a gradient in image is by using the difference equation: (f(x+1) - f(x)/1) = (f(x+1) - f(x))
- so you can use a small filter: x direction: [-1,1], y direction [-1,1]T (assumey is going down from top left corner)
- Developed by Jhon Canny, as his masters thesis
- 4 steps: Smooth, Thresholding (find the significant edges), Thinning (Replace a fat edge with a thin one.), Link separate contours
-
Smoothed - image gradient (Like Sobel)
Smoothing + Image Gradient
-
Threshold
Thresholding
-
Thinning, aka non-maximum suppresion. I will keep the strip that exceeds the threshold the most. (i.e, find the local maxima in the edge)
Thinning
Thinning Result
-
Linking: Link broken Contours together, really cool
- Two threshold for thresholding: high one for "strong" edges, low one for "weak edges". Connect strong edges and weak edges together. Here we assume we want to keep weak edges that are linked to strong edges.
Linking
-
- finding a line! Finding a circle
-
it's actually "fitting a line", because you may have gaps, noise, etc.
-
each edge point will get to vote, including the noisy ones, but the noisy ones shouldn't be consistent enough for a good feature
-
Hough transform vote for lines
-
A point in xy space is a line in Hough space (k-b space), then you plot those lines, and whichever bin has the most votes, will win
Hough Space
Voting
-
but
y=kx+bsuffers from vertical slope. So we use parametric representation:d = xcos(theta) + y sin(theta)
A point in x-y space will become a sinusoid in d-theta space
- theta: [0,2p), d>0
-
Algorithm: the bins are also called "Hough Accumulator Array".
- Initialize each bin to 0
- for a given (x0, y0), iterate thru theta, then calculate d.
- Find the (theta, d) with the max value
-
complexity: K^2 * (k bins along each dimension.)
-
E.g:
A perfect line is that bright spot
caption
-
Cautions:
- you may want to take a look at probablistic Hough Transform, which samples points to find the best fit.
- Noise can bump you off, so you may want to smooth the edges a bit more
-
Extensions:
- use gradient imgs (del(f)/del(x), del(f)/del(y)) instead of just one edge pic, so for each edge pixel will only vote for thetas close to the gradient orientations.
- you can use hough transform, instead of regression, to find circles.
- Give stronger edges more votes
-
- Hough Transform for a circle!
- assume you know r, then all you do is vote for (a, b)
- If you don't know r, then it's a pain
- But if you have gradient, you can check if (a,b) generates a radius that corresponds to the gradient
- Pros & cons:
- pros:
- Some robustness to noise
- Occlusion is fine, cuz all points are processed independently
- can detect multiple models in a single pass
- Cons:
- Complexity goes exponential as number of params go up
- Detected targets can be spurious
- difficult to pick a good bin
- pros:
- Generalized Hough Transform
-
generalized hough transform:
- You have a template, and an image, you're going to search fro the template in the image.
- The template has irregular shape, so you can't express it in parametric eqns.
- For simple case where shape and location don't change, Instead, you express it like this:
1. Find centroid (Xc, Yc) in template (offline) 2. Find edges in centroid 3. For each edge k (a,b), Calculate its distance to Xc,Yc dk, the angle of (Xc - a, Yc - b), theta_k 4. Build an R table, based on the orientation of its gradient, Phi_i Phi1 (dk, theta_k) phi2 (dm, theta_m), (dn, theta_n) .... Because we may have parallel edges, we may have multiple entries under a single Phi 5. In the image, identify the blobs, and find its edges. (Online) 6. For each blob, a. For each edge point on the blob, 1. get its gradient direction, Phi_i 2. look up (dm, theta_m), (dn, theta_n)... under Phi_i, 3. then calculate the corresponding reference point (x1, y1), (x2,y2), and increase their votes. b. Once you're done with all edges, find the pixel with most votes. If the votes are more than a threshold, then we think: 1. the blob matches the template 2. the pixel is the location of the contour 7. Move on to the next blob, repeat 6.
-
generalized Hough Transform with random scale and orientation:
- sample scale space: S1, S2 ...
- For each scale, do the above
-
edges are old. Features (code words) will be more prevalent.
1. Features (like Harris Corner), are small image patches. They represent a code word? Equivalent to "edge" here 2. Offline, using a centroid, features develop an R-table for codeword and displacement(feature, centroid). 3. Online, identify each feature, and their blobs, following the same idea. -
Hough Forest: with classifiers like random forrest, using voting for displacement, orientation with features
-
========================================================================
========================================================================
-
Aliasing happens when sampling frequency is lower than 2 times of the highest fequency in the signal, like jagged lines
-
a set doeson't have to be orthogonal, just independent is fine.
-
fourier transform in image analysis:
Lower frequency vs high frequency
-
computer vision
-
-
frequency analysis
- ringing: after removing some high frequency
Ringing
- Getting rid of low frequency components is like edge image
"Edge images created by high pass filter"
- accentuate low frequncy will give u stronger edges
Stronger edges with weaker low frequency components
- Some interesting patterns

- horizontal line in 2D FFT:
- in 1d, [1,1,1,1,1] (frequency domain) is impulse response [0, 0, 1, 0, 0]
- in 2d,it's equivalent to summing up e(...x,y) * u(x,y) along y first, then along x (order here doesn't matter) link
- a perfect fourier transform assumes periodic signal (images wrapped around and around). So if you have a dark edge at the bottom of your image, you get sharp edge on Fourier analysis.
- use a gaussian filter (on the whole thing?)
- multiplication in spatial/frequency = convolution in frequency/spatial
- What is Fourier Transform? note amplitude (A), phase (phi) are both encoded in F(w)
Fourier Transform Derivation
-
If mask and image are big, use the "Fourier Trick"
-
A gaussian in spatial space is also a gaussian in frequency domain. But, the sigmal will be inverse. So: the larger spatial sigma is (of the kernel), the narrower it is in frequency domain, so the lower frequency it allows to pass.
Gaussian kernal's sigma is inversed in frequency domain
- Effect of Gaussian

- ringing and its counterpart (which cancels ringing)

- box filter is a sync in frequency domain.
sinc = sin(x)/x. See the ripples? they cause the jagged thing in spatial domain.

- sinc in frequency is a box in spatial as well!
- So why you don't want to just cut out the high frequencies! which will introduce ringing
-
One Impulse Train (Shah Function) in space is another impulse train in frequency domain
- Derivation

- when T-> 0, then there's just one impulse in time domain, and we get a solid 1 in frequency domain
- Because of shah function, Nyquist Theorem was developed afterwards.
- Derivation
-
Aliasing
- if you have too few samples, you can't tell if it's high frequency or low frequency
- Your eyes' framerate are not that high, so you may see wheels turn backwards, then forwards. That's aliasing
- AntiAliasing: Use low-pass filters. This is better than aliasing.
- low pass filtering in inputing
- During reconstruction (like in audio), use low-pass filter on the output again, cuz we know the input signals should be thrown away
- Nyquist Theorem
Convolution and Sampling
2B must < f 5. Anti-Aliasing Filter: to get rid of high freuqency components
Anti-Aliasing Filter
- Have to use it before sampling, cuz after sampling, there's no way back!
- Application of Anti-aliasing filter: when you downsample, to keep the edges better, apply AAF before downsample
-
Downsampling: take every other row, for exampe

Carving out every other row, column will lost some features
-
use gaussian
AAF will keep the features instead of simply carving pixels out
-
Might be useful for facial recognition
- Contrast:
-
contrast is the range of [low, high]
Contrast is the Range of intensity values
-
human eyes are sensitive to different contrasts at different frequencies. So you can leave out the high frequency high contrast stuff
Low contrast elements of High Frequency Can be left out
- JPEG uses discrete cosine transform
-
similar to Fourier Transform, DCT gets some coefficients at each frequency, for each cosine (remember fourier transform is e^(j2piw*t))
- disect the image into 8x8 sections
JPEG takes 8x8 pixels
- for each 8x8 sections, convolve with each block in these filters: top left is low frequency, then along the x, y axes, f goes up. the rest (i,j) represents cos(f_i*f_j).
Visualization of the JPEG filters
Then you get a component of each frequency. This is Discrete Cosine Transform DCT only works with real values, so it's great! But certain properties wont hold
- Given human perception, we require different accuracies for different frequencies' components
- "Quantize" by rounding to the nearest value, e.g, 3 at top right, so (16/3=5)
Quantization Table
-

========================================================================
========================================================================
-
- The more frequently a letter (or a symbol) appears, the less bits we should use for them. So we need to know how frequently a symbol may appear
- However, now the problem is: if H is 0, E is 00, the HE (000) might be the same as EH. So the codewords must not create ambiguity. So they call this "non-prefix code"
- Huffman Coding comes to rescue. It generates a binary tree, Based on how frequent each char is.
- How to form a code for a set of symbols
Forming a Huffman Tree
- Why?
It can't be decoded into anything else, if you decode from start to end!
-
Working Example:
- Notice how you can't decoded this into anything else: because the tree is a "full" tree, i.e, if a node has only one child, that child must be a leaf node.
-
Some things to keep in mind:
-
Every set of symbol needs to generate a customized code
-
And The decoder must know the code (the Huffman table)
-
-
JPEG
-
The input is a bmp image. with full on RGB values at each pixel.
-
chroma sub-sampling: we can see brightness differences well, but not color differences. So JPEG throws away a lot of colors. The output is a Y'CbCr image.
-
Y is brightness, Cb is blue components, Cr is red components. Cb, Cr are chroma components.
-
successor of YUV (1950) for transmitting analog TV signals using less bandwidth than RGB. Also, it can have backward compatiblity with black&white TV. (using the fact that if RGB values are the same, they will be a point on the grey scale)
-
chroma means "color" in greek.
-
Y, Cb, Cr can be converted from RGB values. Where the brightness of a pixel, is determined by RGB value all together. (Similar to greyscale)
caption
The higher a value is in dimension, the more "brightness" it has
-
So Y will be kept the same (since eyes are more sensitive to it), and Cb, Cr resolution will be decreased to save bits.
-
-
DCT & quantization
-
Separate an image into 8x8 chunks, then run DCT to get frequency components
You can see the reconstructed images by adding the frequency components back
-
For each 8x8 section, you get one number after you convolve it with a frequency pattern. That's called a DCT term. Quantization table is how to do the rounding. We want smaller terms for high frequency components
How you get frequency components for compression
-
Human eyes can't see changes occur in close proximity (high frequency components), so there're more low-frequency components, and fewer low frequency components. Quality Factor controls how big the devisors are
-
brightness is also quanized: low brightness values have lower resolutions.
-
Quality factor is how fine the quantization resolution can be
-
-
Huffman coding
-
-
H264 Decoding
- Aka AVC. There's also H.265(HEVC), RM (real player 20 yrs ago ). H264 has AAC (audio), 80% from MJPEG compression
- Will compress on portions which don't move much. (Temporal Compression)
- iframe (aka keyframe), is pretty much the same as MPEG frames. Requires higher bit rate, lower processing power. Also known as intra-frame
- pframes are medium size, which illustrates difference s from the previous iframe, or pframes.
- bframes will compare itself with the previous and the next iframe, pframe, or bframe. Smallest in filesize, but will introduce latency. **Camera Manufaturer can choose if bframes are used. **
- QP means quantization Parameter (20-51)
- MJPEG is simply encoding frames into jpg.
- Spatial Compression: Compare the pixel values block by block, and find matching pixels. Say if a blob moves from position A to B, h264 should be able to find it.
- Question: how does this work?
- depth - number of bits to represent a pixel
-
CV_32Fis 32 bit float
-
- Practice Experience:
- convolution is just flipping the kernel, pad the image on both sides, and
- the output size should be
n = (img + 2*padding_size_one_side - kernel_size +1), so we can make the output image the same size as the input image!
- the output size should be
-
cv2.filter2Dapplies correlation, not the real convolution.- also, it doesn't work with RGBA, only RGB!
- convolution is just flipping the kernel, pad the image on both sides, and