CUDA - RicoJia/notes GitHub Wiki
-
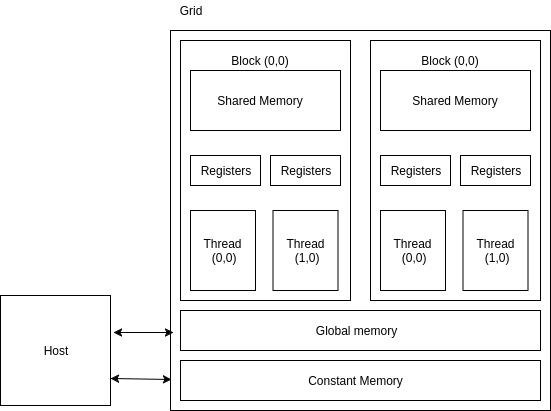
Memory Architecture with Low-capacity, High Bandwidth Memories- This is for caching values without the slow DRAMs.
- Global Memory is slowest in the figure. All threads of any block may access it.
- Const memory is for storing read-only data (to host)
- Shared memory can be accessed by threads on the same block, slower than register, faster than global memory
-
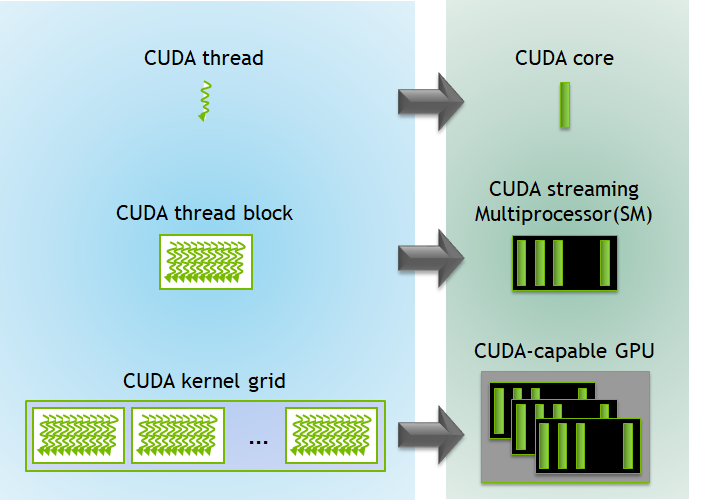
a group of threads is called a block, a group of blocks is a grid. A kernel is one grid
- a block is run by one "Streaming Multiprocessor", which is shared by multiple CUDA blocks.
Cuda Architecture- max 1024 threads on a block, 65536 blocks max
- To create the function
-
Memory limits
- global memory (on Device DRAM, 2^31 bytes)
- Constant memory (65536 bytes)
-
You cannot print a device inside a
__global__function.calling a __host__ function("std::vector<unsigned int, std::allocator<unsigned int> > ::data") from a __global__ function("histogram_gmem_atomics") is not allowed -
Basic compiling:
nvcc -o out hist.cu -ljpeg -
data types
-
float4is a struct with x, y, z, w,make_float4(a,b,c,d)
-
-
device quantifiers
-
hostis CPU, host code can- manage memory on both the device and the host
- launches kernels on the device.
- Typical workflow:
- Declare and allocate memory host and device
- Initialize host data
- Transfer data from host to device
- launch kernel
- Transfer data from device back to host
- function qualifier:
-
__global__: function called from host and executed on device -
__device__: function called on device and executed on device -
__host__: callable from host only. Ordinary C function, but can access device memory - mix style
__host__,__device__, CPU, gpu code, reduce code-duplication__device__ __host__ void init(int _w, int _h, int _subs) {}
-
-
-
tutorial Nice to have a "grid-stride" loop. That is, increment by a 2d-grid size. This way, you can fully expand along the number of the grid size.
- Also, this can maximize memory coalescing (global memory is also allocated in a logical "grid" fashion, so if thread 0 executes 0, 1256, ... within a single warp, we can maximize the number of threads accessing the same shared memory block, which reduces number of memory loading). See here
- For cuda,
.cufile is required, so you have to build a static lib with that. (D)- Because NVCC (the cuda compiler) can only recognize
.cufiles. - Usually ppl put CUDA kernels into
.cuh(D)
- Because NVCC (the cuda compiler) can only recognize