Mixed precision computing - RecycleAI/RecycleIT-A GitHub Wiki
The IEEE Standard for Floating-Point Arithmetic is the common convention for representing numbers in binary on computers. In double-precision format, each number takes up 64 bits. Single-precision format uses 32 bits(FP32), while half-precision is just 16 bits(FP16).
Mixed-precision, also known as transprecision, computing instead uses different precision levels within a single operation to achieve computational efficiency without sacrificing accuracy.
Accuracy vs memory
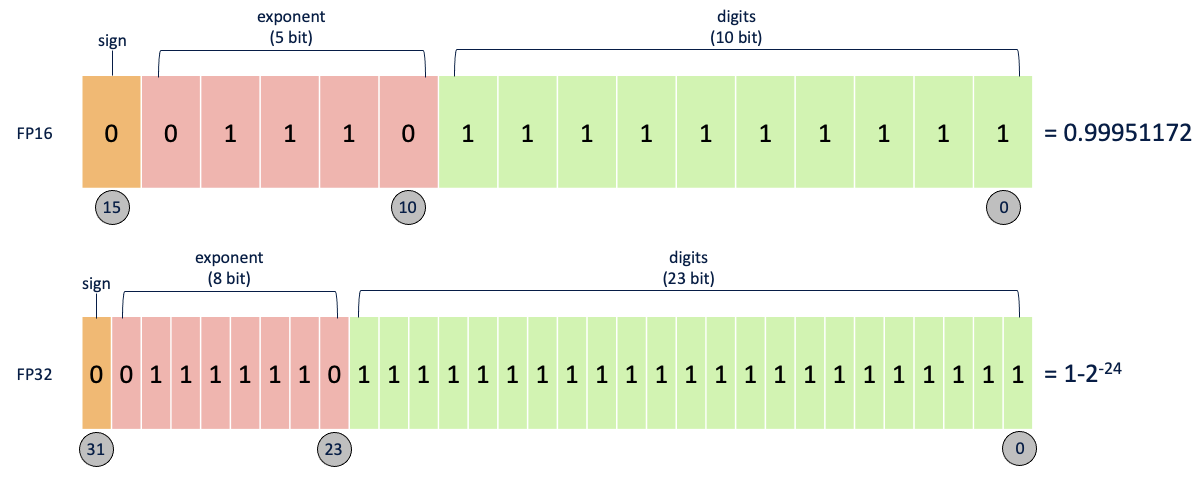
During standard training of neural networks FP32 to represent model parameters at the cost of increased memory requirements. In mixed-precision training, FP16 is used instead to store the weights, activations and gradients during training iterations.
However, as we saw above this creates a problem, as the range of values that can be stored by FP16 is smaller than FP32, and precision decreases as number become very small. The result of this would be a decrease in the accuracy of the model, in line with the precision of the floating-point values calculated.
To combat this, a master copy of the weights is stored in FP32. This is converted into FP16 during part of each training iteration (one forward pass, back-propagation and weight update). At the end of the iteration, the weight gradients are used to update the master weights during the optimizer step.
Loss scaling
Although mixed-precision training solved, in the most part, the issue of preserving accuracy, experiments showed that there were cases where small gradient values occurred, even before being multiplied by the learning rate.
The NVIDIA team showed that, although values below 2^-27 were mainly irrelevant to training, there were values in the range [2^-27, 2^-24) which were important to preserve, but outside of the limit of FP16, equating them to zero during the training iteration. This problem, where gradients are equated to zero due to precision limits, is known as underflow.
Therefore, they suggest loss scaling, a process by which the loss value is multiplied by a scale factor after the forward pass is completed and before back-propagation. The chain rule dictates that all the gradients are subsequently scaled by the same factor, which moved them within the range of FP16.
Once the gradients have been calculated, they can then be divided by the same scale factor, before being used to update the master weights in FP32.
Automatic Mixed Precision
In 2018, NVIDIA released an extension for PyTorch called Apex, which contained AMP (Automatic Mixed Precision) capability. This provided a streamlined solution for using mixed-precision training in PyTorch.
In only a few lines of code, training could be moved from FP32 to mixed precision on the GPU. This had two key benefits:
Reduced training time — training time was shown to be reduced by anywhere between 1.5x and 5.5x, with no significant reduction in model performance. Reduced memory requirements — this freed up memory to increase other model elements, such as architecture size, batch size and input data size.
also there is a sample guide for using mixed precision technique in TensorFlow.
tips to be follow out
training optimization(time, memory, accuracy) or inference optimization?