Supervised training - QueensGambit/CrazyAra GitHub Wiki
Supervised Training
- CrazyAra 0.1 used a similar training schedule as Alpha-Zero:
Using a constant learning rate 0.1 and dropping by factor 10 when no improvement was made on the validation dataset for a given period.
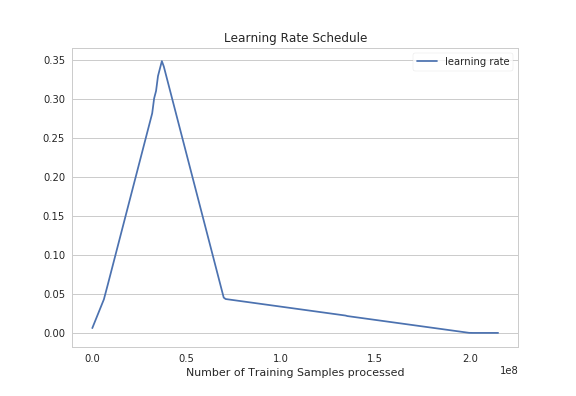
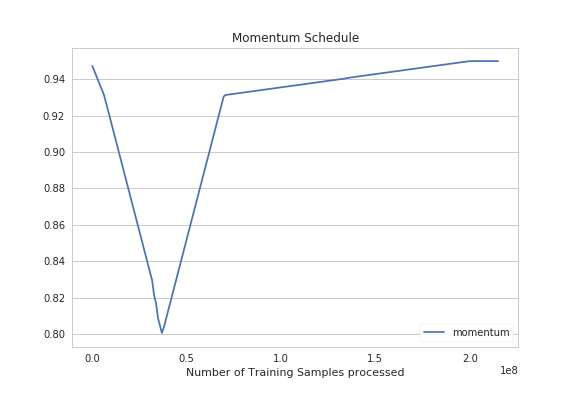
- CrazyAra 0.2 uses a One-Cycle-Policy Learning rate schedule combined with a momentum schedule. The learning rate was determined using a lr-range test and the model was trained for seven epochs with a mini batch size of 1024.
 |
 |
Referenes
- Smith and Topin - 2017 - Super-Convergence Very Fast Training of Neural Networks Using Large Learning Rates - https://arxiv.org/pdf/1708.07120.pdf_
- Smith - 2018 - A disciplined approach to neural network hyper-pararameters - https://arxiv.org/pdf/1803.09820.pdf
Training Data
The deeper model using 7 standard residual blocks and 12 bottleneck residual blocks was trained only supervised using the same training and validation dataset:
- 569,537 human games generated by lichess.org users from January 2016 to June 2018 (database.lichess.org/) in which both players had an elo >= 2000

Training Results
 |
 |
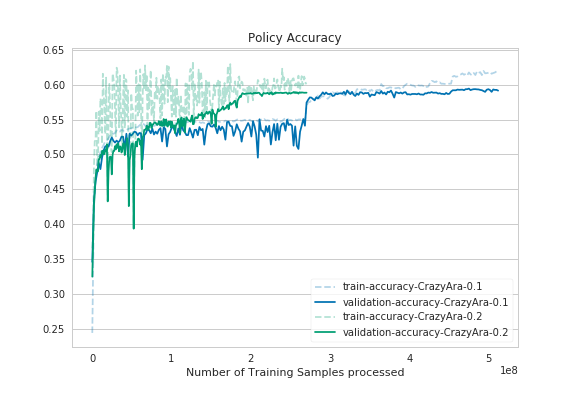 |
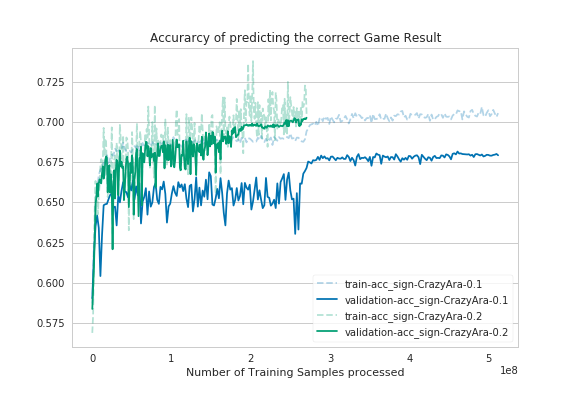 |
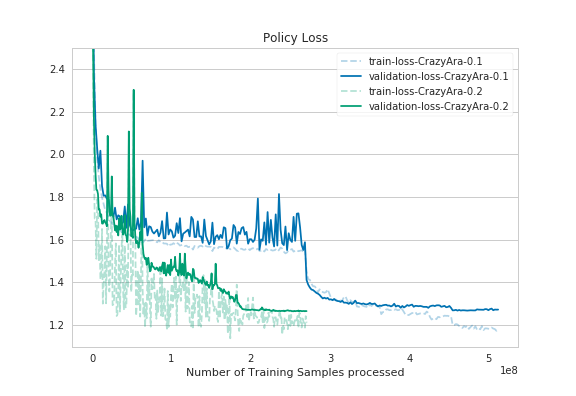
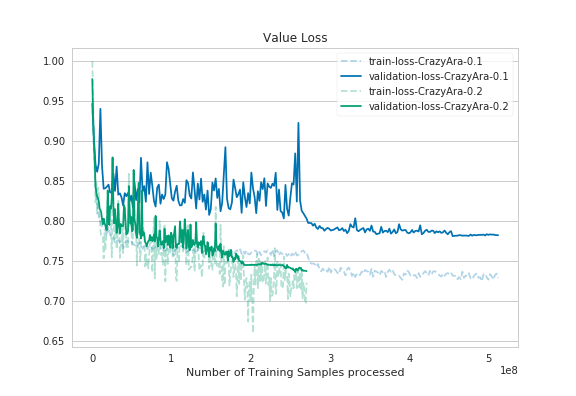
As it can bee seen in the graphs the deeper model converged quicker. Despite using half of the batch-size and having a deeper model the full training time was reduced from previously ~40 hours to ~36,5 hours.
Result overview regarding metrics
Current overall best network trained on the all over 2000 elo game dataset:
| Metric | CrazyAra 0.1 | CrazyAra 0.2 |
|---|---|---|
| val_policy_loss | 1.2680 | 1.2647 |
| val_value_loss | 0.7817 | 0.7386 |
| val_policy_acc | 0.5930 | 0.5895 |
| val_value_acc_sign | 0.6818 | 0.7010 |
| mate_in_one_policy_policy_loss | 0.5859 | 0.5514 |
| mate_in_one_value_loss | 0.0769 | 0.0534 |
| mate_in_one_acc | 0.939 | 0.939 |
| mate_in_one_top_5_acc | 0.997 | 0.998 |