Model architecture - QueensGambit/CrazyAra GitHub Wiki
Model architecture
RISEv3.3
In ClassicAra 0.9.2 the RISEv3.3 architecture was introduced which is an improvement over the RISEv2 architecture (#104).
The development process was influenced by the following papers. However, most of the proposals turned out to be not beneficial for chess neural networks or suboptimal when applied for GPU inference.
- MixConv: Mixed Depthwise Convolutional Kernels, Mingxing Tan, Quoc V. Le, https://arxiv.org/abs/1907.09595
- Direct Neural Architecture Search on Target Task and Hardware, Han Cai, Ligeng Zhu, Song Han. https://arxiv.org/abs/1812.
- MnasNet: Platform-Aware Neural Architecture Search for Mobile, Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, Quoc V. Le http://openaccess.thecvf.com/content_CVPR_2019/html/Tan_MnasNet_Platform-Aware_Neural_Architecture_Search_for_Mobile_CVPR_2019_paper.html
- FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search, Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, Kurt Keutzer, http://openaccess.thecvf.com/content_CVPR_2019/html/Wu_FBNet_Hardware-Aware_Efficient_ConvNet_Design_via_Differentiable_Neural_Architecture_Search_CVPR_2019_paper.html
- MobileNetV3: Searching for MobileNetV3, Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam. https://arxiv.org/abs/1905.02244
- Convolutional Block Attention Module (CBAM), Sanghyun Woo, Jongchan Park, Joon-Young Lee, In So Kweon https://arxiv.org/pdf/1807.06521.pdf
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks (ecaSE) - Wang et al. https://arxiv.org/abs/1910.03151
- Rethinking Bottleneck Structure for EfficientMobile Network Design, D. Zhou and Q. Hou et al., https://link.springer.com/chapter/10.1007/978-3-030-58580-8_40
The changes which where incorporated in RISEv3.3 where the following:
- Replacing squeeze excitation modules by efficient squeeze excitation modules as proposed by Wang et al. (https://arxiv.org/abs/1910.03151)
- Replacing sigmoid by hard-sigmoid as recommend in Searching for MobileNetV3 by Howard et al. (https://arxiv.org/abs/1905.02244)
- Making use of 5x5 convolutions in deeper layers as recommended in Platform-Aware Neural Architecture Search for Mobile by Tan et al. (http://openaccess.thecvf.com/content_CVPR_2019/html/Tan_MnasNet_Platform-Aware_Neural_Architecture_Search_for_Mobile_CVPR_2019_paper.html)
- Using the flag boolean flag
globalfor average pooling layers - Using a higher initial channel size, more residual blocks but a lower increase of number of channels per layer (32 instead of 64).
The architecture resulted in an ~150 Elo improvement when trained on the same data set, here Kingbase2019lite. The other only difference other difference was changing the value loss ratio from 0.01 to 0.1.
TimeControl "7+0.1"
Score of ClassicAra 0.9.1 - Risev3.3 vs ClassicAra 0.9.1 - Risev2: 81 - 15 - 64 [0.706]
Elo difference: 152.4 +/- 42.8, LOS: 100.0 %, DrawRatio: 40.0 %
160 of 1000 games finished.
RISEv2
In CrazyAra v0.2.0 a newly designed architecture was used which is called RISE for short.
It incorporates new ideas and techniques described in recent papers for Deep Learning in Computer Vision.
| ResneXt | He et al. - 2015 - Deep Residual Learning for Image Recognition.pdf - https://arxiv.org/pdf/1512.03385.pdf |
| Xie et al. - 2016 - Aggregated Residual Transformations for Deep Neurarl Networks - http://arxiv.org/abs/1611.05431 | |
| Inception | Szegedy et al. - 2015 - Rethinking the Inception Architecture for ComputerVision - https://arxiv.org/pdf/1512.00567.pdf) |
| Szegedy et al. - 2016 - Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning - https://arxiv.org/pdf/1602.07261.pdf) | |
| Squeeze | Hu et al. - 2017 - Squeeze-and-Excitation Networks - https://arxiv.org/pdf/1709.01507.pdf) |
| Excitation | Hu et al. - 2017 - Squeeze-and-Excitation Networks - https://arxiv.org/pdf/1709.01507.pdf) |
The proposed model architecture has fewer parameters, faster inference and training time while maintaining an equal amount of depth compared to the architecture proposed by DeepMind (19 residual layers with 256 filters). On our 10,000 games benchmark dataset it achieved a lower validation error using the same learnig rate and optimizer settings.
| RISE-Architecture (CrazyAra v0.2) | Vanilla-Resnet Architecture(CrazyAra v0.1) |
|---|---|
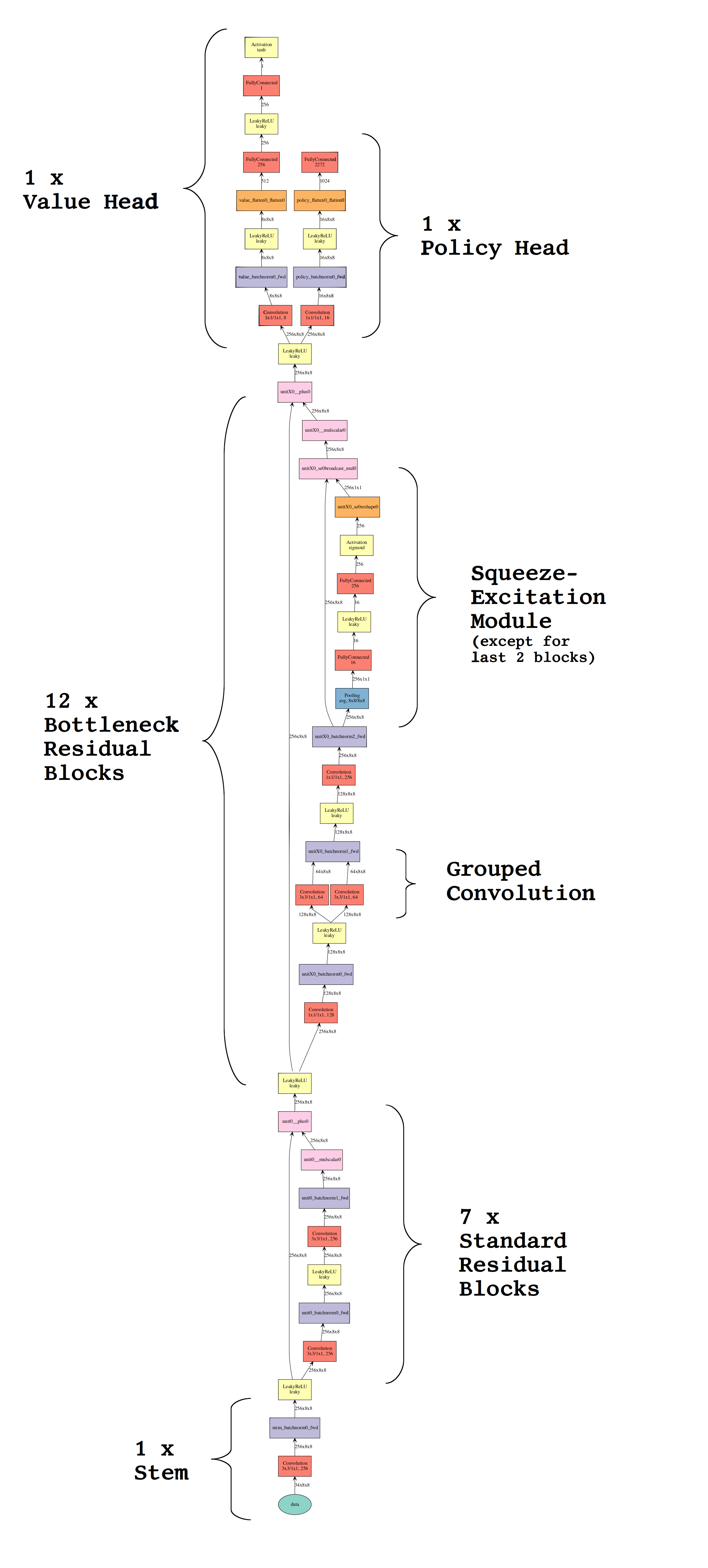 |
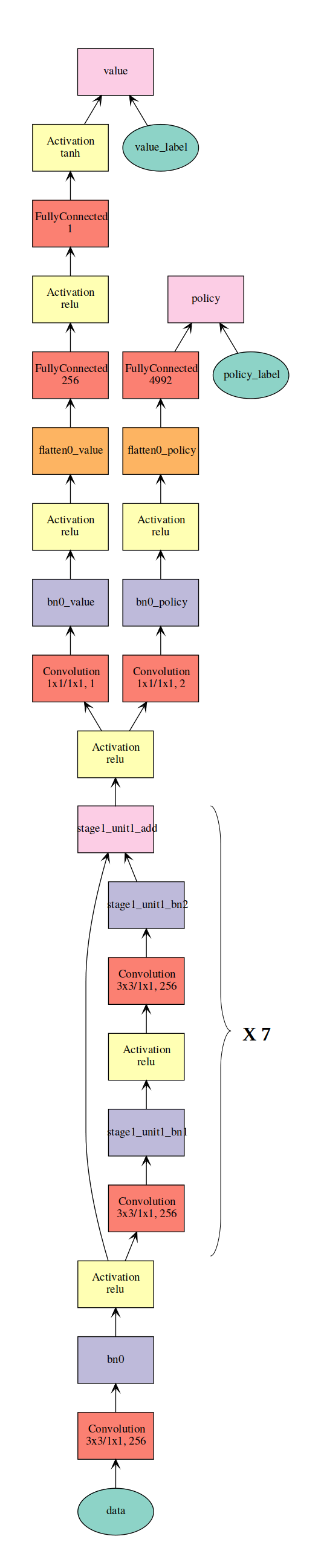 |